

정보
-
업무명 : 기초통계 : 표본분산과 비편향 분산
-
작성자 : 박진만
-
작성일 : 2020-04-14
-
설 명 :
-
수정이력 :
내용
[개요]

[특징]
-
통계이론 설명
[활용 자료]
-
없음
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용법]
-
내용 참조
상세 내용
[t 검정]
-
t 검정은 표본 데이터에서 t 값이라 불리는 통계를 계산하고 t 값을 이용하여 두 그룹 간의 모평균에 차이가 있는지를 검정하는 방법이다.
-
\(X_{1}, X_{2}, \ldots, X_{n}\)을 평균 μ와 분산 σ2 인 정규 분포를 따르는 확률 변수라고 할 때, t 값은 표본 평균 \(\bar{X}\) 및 표본 불편 분산 \(S^{2}\)을 사용하여 아래와 같이 놓을 수 있다.
-
샘플 크기 n이 작을 때, t는 자유도 n - 1 의 t 분포에 따라
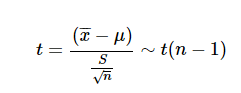
-
그러면 t 분포를 이용하여 모평균의 신뢰 구간을 구할 수있다. 예를 들어, 샘플 크기가 클 때의 모평균의 구간 추정과 동일한 단계에서 작은 샘플 크기의 경우 모평균은 확률 α로 다음 범위 내에.
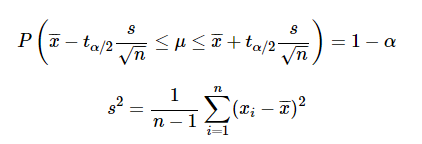
-
이것을 이용하여 표본 평균과 모평균의 차이를 검정하고, 두 그룹 간의 모평균의 차이를 검정 할 수있게된다.
[단일 표본 : 귀무가설]
-
귀무가설이란 모집단으로부터 n 개의 표본 X1, X2, ..., Xn을 독립적으로 추출했을 때, n 개의 표본을 사용하여 그 모집단의 평균이 μ인지 여부를 검정하는 방법이다.
-
여기에서 검정을 수행하기 위해 귀무 가설 H0 를 "표본 평균 \(\bar{X}\)가 모평균 μ와 동일하다고 가정한다.
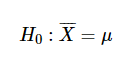
-
여기서 \(\bar{X}=\mu\)를 하는 이유는 이 가설이 일어날 수있는 사례가 단 한 가지 밖에 없기 때문이다. 예를 들어, \(\bar{X} \neq \mu\) 라고 가정한다면, \(\bar{X}>\mu\)도 성립하고 \(\bar{X}<\mu\)도성립하게 된다.
-
또한 \(\bar{X}<2 \mu\)나 \(\bar{X}<3 \mu\) 같은 경우도 생각할 수있다. 따라서 \(\bar{X} \neq \mu\)를 가정하게 된다면, 다양한 케이스에 대해 검증 해야할 필요가 있다.
-
그러나 가설을 \(\bar{X}=\mu\)라고 놓는다면, \(\bar{X}=\mu\)라는 케이스만을 검증하면 충분하기 때문이다.
-
여기에서 샘플 크기가 작은 경우, 귀무 가설 H0이 맞으면 T 값은 자유도 ν = n - 1 t 분포를 따른다.
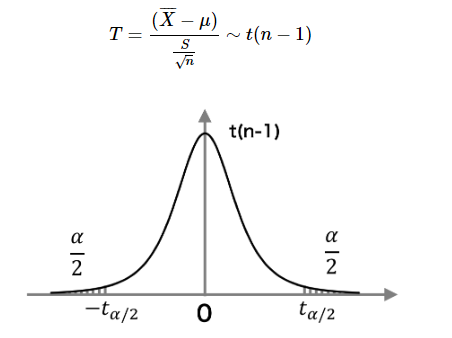
[단일 표본 : 검정과 유의수준]
-
t 분포 형태에서 T 값은 0의 값을 가질 확률이 가장 높고, 또한 ± ∞ 확률도 0이 아니라는 것을 알 수있다.
-
여기서, T ≤ -t α / 2 일 때의 확률이 α / 2, T ≥ t α / 2 일 때의 확률이 α / 2가되는 점 t α / 2 및 점 -t α / 2 에 주목해보자면, 이때 귀무 가설이 맞는 경우, 즉 표본 평균이 μ와 등가이면 표본 데이터에서 계산되는 T 값을 확률 1 - α로 -t α / 2 <T <t α / 2 의 범위에 들게 된다.
-
예를 들면 α = 0.05 일 때 T 값은 0.95의 확률로 -t 0.025 <T <t 0.025 에 위치한다.
-
물론 -t 0.025 <T <t 0.025 이외의 값도 취할 수 있지만, 그 확률은 0.05이며 매우 작다고 놓을 수 있는 것이다.
-
그래서 T 값은 확률 1 - α로 -t α / 2 <T <t α / 2 의 범위에 들어가는 때문에 T 값이 범위 내에있을 때 귀무 가설을 보류하고, T 값이 범위 밖에있을 때 귀무 가설을 기각하고 (즉 표본 평균이 μ와 동치가 아니라고 판단하고), 기각 판정을 내릴 수있다.
-
이 때 T 값을 확률 α로 -t α / 2 <T <t α / 2 의 범위 밖에 있기 때문에 이러한 판정을 내릴 것으로, 확률 α로 판정 실수가 발생할 위험이 있다.
-
따라서 이러한 판정을 내릴 때 "위험 요소 α 하에서 귀무 가설을 기각했다 (위험 요소 α 하에서 표본 평균이 μ와 동치가 아니라고 판단했다)"의 문장을 추가 할 필요가 있다. 이 위험 요소 α는 유의 수준 이라고도 한다.
[R을 이용한 단일 표본에 대한 T 표본 검정]
-
다음은 R을 사용하여 표본 x의 평균이 2.0인지 여부를 판정하는 예이다.
-
먼저 T 값을 계산 한 다음 ± t α / 2 의 값을 계산하여 양자를 비교하여 판정을 내린다.
-
이 때, 유의수준 0.05 이내에서 판정을 내려야 한다.
x <- c(3.2, 3.6, 2.9, 2.5, 3.1, 2.7, 3.0, 3.2)
n <- length(x)
t.value <- (mean(x) - 2.0) / (sd(x) / sqrt(n))
# 8.602691
err <- qt(0.975, df = n - 1) * sd(x) / sqrt(n)
mean(x) - err
# 2.743258
mean(x) + err
# 3.306742
alpha <- 0.05
t.alpha.2.n <- qt(alpha / 2, df = n - 1)
# -2.364624
t.alpha.2.p <- qt(1 - alpha / 2, df = n - 1)
# 2.364624
p.value <- 2 * pt(- abs(t.value), df = n - 1)
# 5.716248e-05
-
따라서 T 값 ( t.value)은 t.value> t.alpha.2.p이기 때문에 유의수준 0.05 하에서 귀무 가설을 기각 할 수 있다. 또한 R의 t.test함수를 사용하면 다음과 같이 단일 표본 t 검정을 할 수있다.
x <- c(3.2, 3.6, 2.9, 2.5, 3.1, 2.7, 3.0, 3.2)
t <- t.test(x, mu = 2.0)
t
# One Sample t-test
#
# data: x
# t = 8.6027, df = 7, p-value = 5.716e-05
# alternative hypothesis: true mean is not equal to 0
# 95 percent confidence interval:
# 2.743258 3.306742
# sample estimates:
# mean of x
# 3.025
[표본이 2개인 경우에 대한 t 검정 - 분산이 같은 경우]
-
2 표본 t 검정은 두 그룹의 모평균에 차이가 있는지를 검정하는 방법이다.
-
여기에서 두 그룹을 X 그룹과 Y 그룹으로 가정한다. 또한 X 그룹의 모평균 μ X , Y 그룹의 모평균을 μ Y 로 둔다. 이때 귀무 가설을 'X 그룹의 모평균과 Y 그룹의 모평균에 차이가 없다 "고 할 수있다.
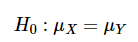
-
두 그룹의 모평균에 차이가 있는지의 여부를 검정하기 위해, 여기서 X 그룹의 표본 평균과 Y 그룹의 표본 평균의 차이에 대해 주목한다.
-
즉 모집단 X에서 표본을 추출했을 때, 해당 그룹의 표본평균인 \(\bar{X}\)는 \(\mathcal{N}\left(\mu_{X}, \sigma_{X}^{2} / n_{X}\right)\)의 분포를 따른다.
-
마찬가지로 모집단 Y에서 표본을 추출했을 때, 표본 평균\(\bar{Y}\) 는 \(\mathcal{N}\left(\mu_{Y}, \sigma_{Y}^{2} / n_{Y}\right)\)의 분포를 따른다.
-
이 때, \(\bar{X}\) 와 \(\bar{Y}\) 가 독립이면 (다변량 결합 분포의 계산을 함으로써) 양자의 차이는 다음의 분포를 따르게 된다.
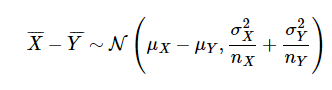
-
이를 표준화하면
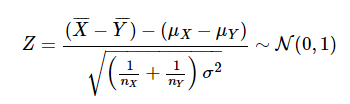
-
샘플 크기가 작으면 Z는 자유도 n X + n Y - 2의 t 분포를 따른다.
-
여기에 작은 샘플 크기임을 나타 내기 위해 위 식에서 확률 변수 Z를 T로 바꿔 쓴다고 해 보자.
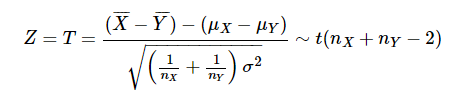
-
여기서, 모분산 σ 2 를 알 수 없기 때문에, X 그룹 및 Y 그룹의 표본에서 모집단의 불편 분산을 추정한다.
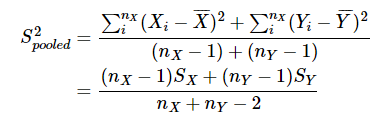
-
추정 된 모집단의 불편 분산을 확률 변수 T에 대입하면 아래의 식을 얻을 수 있다.

-
귀무 가설이 성립한다면 μ X = μ Y 이다. 따라서 귀무 가설 하에서 T는 다음과 같이 계산할 수 있다.
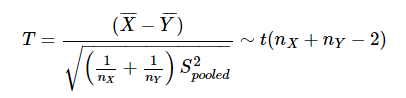
-
이와 같이 T 값이 구해지면, 그 때부터 1 표본 t 검정과 마찬가지로 가설검정을 진행할 수 있다.
[R을 이용하여 표본이 2개인 경우에 대한 t 검정 수행 (균등 분산의 경우)]
-
R에서 2 표본 t 검정을 할 때 t.test함수에 두 그룹의 데이터를주고 실행한다. 검정시 유의 수준은 0.05로 한다.
# Two Sample t-test
#
# data: x and y
# t = -2.2788, df = 14, p-value = 0.03888
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# -15.4324621 -0.4675379
# sample estimates:
# mean of x mean of y
# 9.4125 17.3625
alpha <- 0.05
nx <- length(x)
ny <- length(y)
t.alpha.2.n <- qt(alpha / 2, df = nx + ny - 2)
# -2.144787
t.alpha.2.p <- qt(1 - alpha / 2, df = nx + ny - 2)
# 2.144787
-
t.test결과에서 t 값은 -2.2788이며, 이것이 -t α / 2 = -2.144787보다 작기 때문에 유의수준 0.05 하에서 귀무 가설을 기각한다. 따라서, X 그룹과 Y 그룹의 모평균이 동일하지 않은 것이 판정되었다.
[표본이 2개인 경우에 대한 t 검정 - 분산에 차이가 있는 경우]
-
두 그룹의 모평균에 차이가 존재하는지 여부를 검정 할 때, 두 그룹의 분산이 다른 경우에는 다음 식에 따라 T 값을 계산한다.
-
이 때 T 값은 자유도 ν의 t 분포를 따른다.
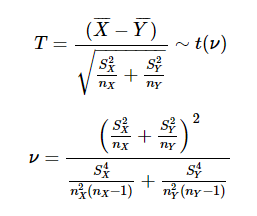
[R을 이용하여 표본이 2개인 경우에 대한 t 검정 수행 (분산이 다른 경우)]
x <- c(20.5, 5.3, 12.4, 2.9, 12.3, 6.7, 2.1, 13.1)
y <- c(1.4, 16.1, 31.0, 10.9, 20.6, 15.7, 24.2, 28.0)
t.test(x, y, var.equal = FALSE)
## Welch Two Sample t-test
##
## data: x and y
## t = -2.2376, df = 12.026, p-value = 0.04495
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -17.909469 -0.240531
## sample estimates:
## mean of x mean of y
## 9.4125 18.4875
[실제 t 검정의 예시]
-
t 검정은 일반적으로 처리 전과 처리 후 차이가 발생했는지 여부를 조사하는 목적으로 사용된다.
-
예를 들어, 마우스의 약제 투여 실험에서 약물 투여 전과 투여 후 심박수에 차이가 발생했는지 여부를 조사 하는 등의 목적을 들 수 있다.
| 개체 | 약제 투여 전 심박수 | 약제 투여 후 심박수 | 변화 |
| 마우스 1 | 591 | 585 | -6 |
| 마우스 2 | 615 | 590 | -25 |
| 마우스 3 | 602 | 583 | -19 |
| 마우스 4 | 618 | 594 | -24 |
| 마우스 5 | 596 | 589 | -7 |
-
이 경우 처리 전과 처리 후의 심박수의 차이에 주목하여 그 차이가 0인지 여부를 단일 표본 t 검정으로 간주 할 수 있다.
before <- c(591, 615, 602, 618, 596)
after <- c(585, 590, 583, 594, 589)
t.test(before, after, paired = TRUE)
##
## Paired t-test
##
## data: before and after
## t = 3.9595, df = 4, p-value = 0.01669
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 4.840301 27.559699
## sample estimates:
## mean of the differences
## 16.2
diff <- after - before
t.test(diff, rep(0, 5), var.equal = FALSE)
## Welch Two Sample t-test
##
## data: diff and rep(0, 5)
## t = -3.9595, df = 4, p-value = 0.01669
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -27.559699 -4.840301
## sample estimates:
## mean of x mean of y
## -16.2 0.0
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'통계 이론' 카테고리의 다른 글
| [통계 이론] 기초통계 : Wilcoxon 순위 합 검정 (0) | 2020.04.14 |
|---|---|
| [통계 이론] 기초통계 : F 검정 (2) | 2020.04.14 |
| [통계 이론] 기초통계 : 표본 분산과 불편 분산 (0) | 2020.04.14 |
| [통계이론] 확률분포 : 푸아송 분포 (0) | 2020.04.11 |
| [통계 이론] 확률분포 : 이항분포 (0) | 2020.04.11 |