

정보
-
업무명 : 기초통계 : 표본분산과 비편향 분산
-
작성자 : 박진만
-
작성일 : 2020-04-14
-
설 명 :
-
수정이력 :
내용
[개요]

[특징]
-
통계이론 설명
[활용 자료]
-
없음
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용법]
-
내용 참조
상세 내용
[표본분산과 비편향 분산]
-
분산은 표본 분산 (sample variance)과 불편 분산 (unbiased variance)의 두 종류가 존재한다.
-
표본 분산은 표본에서 계산 된 분산이며, 모집단에 비해 표본수가 적을 때는 표본 분산이 모분산보다 작아진다.
-
즉 표본 분산이 모집단 분산에 맞춰서 동일하게 보정 한 것을 비편향 분산이라 한다.
-
통계학에서는 이 비편향 분산을 사용하는 경우가 많다.
-
n 개의 표본 \(x_{1}, x_{2}, \dots, x_{n}\) 에 대한 평균값을 \(\bar{X}\)라 할 때 표본 분산은 아래와 같이 구할 수 있다.
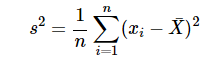
-
한편, 불편 분산은 아래와 같이 n 대신 n-1로 나누어 구할 수 있다.

[표본 분산과 모 분산의 오차]
-
표본 분산과 모 분산의 사이에 존재하는 오차를 계산해보자.
-
첫째로, 표본 분산의 정의식에 \(x_{i}-\bar{X}=x_{i}-\mu-(\bar{X}-\mu)\) 를 대입하고 식을 변환한다.

-
이 때, 표본 분산의 기대값을 구하면 아래와 같다.

-
한편, n 개의 데이터가 평균 μ, 분산 σ 2 인 모집단에 속하기 때문에 이때 분산은 다음과 같이 계산할 수 있다.

-
따라서 표본 분산의 기대값에 위 식을 대입하면 아래와 같다.

-
즉, 표본 분산 (기대 값)은 모 분산에 비해 \(E\left[(\bar{X}-\mu)^{2}\right]\) 만큼 작다.
-
여기서 표본 분산은 모 분산과 동등하지 않기 때문에 공정하지 않을 수 있다.
[불편분산]
-
표본 분산의 기대 값은 모집단 분산에 비해 \(E\left[(\bar{X}-\mu)^{2}\right]\) 만큼 작다.
-
따라서 표본 분산의 오차를 보정한다면 표본 데이터를 이용하여 모집단 분산을 추정 할 수 있게 된다.
-
평균 μ, 분산 σ2의 모집단 정보는 아래의 관계가 성립한다.

-
이를 표본 분산의 기대 값의 식에 대입한다.

-
따라서,

-
따라서, 표본에서 분산을 계산할 때 n으로 나누는 것이 아니라, 위 식과 같이 n-1로 나눈 것으로, 모집단 분산 σ와 동일하다.
-
여기서 n-1로 나누어 계산 된 분산을 불편 불편분산이라 한다.
-
통계 분야에서 말하는 분산은 대부분의 경우 불편 분산을 의미한다.

참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'통계 이론' 카테고리의 다른 글
| [통계 이론] 기초통계 : F 검정 (2) | 2020.04.14 |
|---|---|
| [통계 이론] 기초통계 : t 검정 (0) | 2020.04.14 |
| [통계이론] 확률분포 : 푸아송 분포 (0) | 2020.04.11 |
| [통계 이론] 확률분포 : 이항분포 (0) | 2020.04.11 |
| [통계이론] 확률분포 : 정규분포 (0) | 2020.04.10 |