

정보
-
업무명 : NetCDF 형식인 NPP/CERES SSF 기상위성 자료를 이용하여 아스키 (ASCII) 형식으로 처리
-
작성자 : 이상호
-
작성일 : 2019-12-27
-
설 명 :
-
수정이력 :
내용
[특징]
-
NetCDF 형태인 기상위성 자료를 가시화하기 위해서 ASC 형태로 변환이 요구되며 이 프로그램은 이러한 목적을 달성하기 위한 소프트웨어
[기능]
-
NPP/CERES SSF 기상위성 자료를 이용하여 ASC 형태로 처리
[활용 자료]
-
위성명 : NPP 기상위성
-
센서명 : CERES
-
자료 레벨 : SSF
-
자료 종류 : 날짜, 시간, 위도, 경도, 태양 천정각, 대기 상단에서의 상향단파복사, 대기 상단에서의 하향단파복사, 지표면 특성, 운량
-
영역 : 전지구
-
해상도 : 20 km
-
확장자 : NetCDF
-
기간 : 2012년 03월 15일 0000-2300 UTC
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용법]
-
입력 자료를 동일 디렉터리 위치
-
소스 코드를 실행 (Rscript Processing_Using_NetCDF_Format_of_NPP_CERES_SSF_Data.R)
-
ASC 형태인 결과를 확인
[사용 OS]
-
Windows10
[사용 언어]
-
R v3.6.2
-
R Studio v1.2.5033
소스 코드
[명세]
-
메모리 해제
# Set Option
memory.limit(size = 9999999999999)
-
라이브러리 읽기
# Library Load
library(RNetCDF)
library(tidyverse)
library(lubridate)
-
파일 읽기
# File Read
sInputFileDirName = "INPUT_SSF15/*.nc"
sFileDirName = Sys.glob(sInputFileDirName)
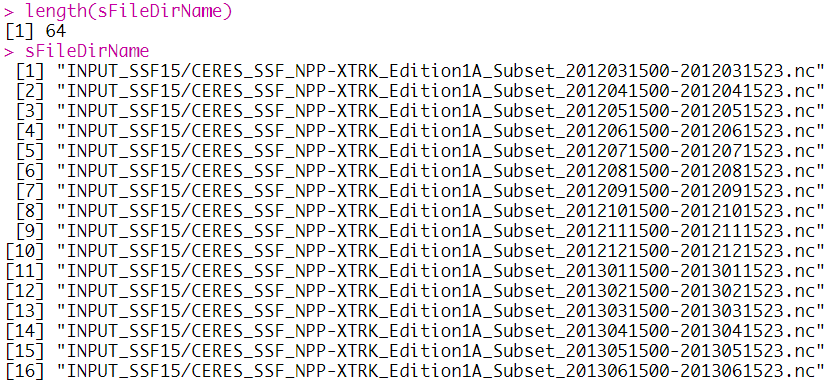
length(sFileDirName)
sFileDirName
-
NetCDF 파일 읽기
# NetCDF File Open
ncFile = open.nc(sFileDirName[iCount])
-
출력을 위한 파일명 초기화
# Set Output File Name
sFileDirNameSplit = unlist(str_split(string = sFileDirName[iCount], pattern = "_|/|\\."))
sOutputFileDirName = paste0('OUTPUT/', sFileDirNameSplit[5], "_", sFileDirNameSplit[8], ".OUT")

-
NetCDF 파일 읽기
# NetCDF File Read
ncData = read.nc(ncFile)
-
NetCDF 파일 갯수 및 Time 단위 가져오기
# Get Time Unit
nFileNumber = dim.inq.nc(ncFile, "time")$length
sTimeUnit = att.get.nc(ncFile, "time", "units")
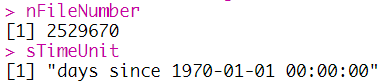
-
NetCDF 변수 가져오기
# Get Variable
nDateTime = utcal.nc(sTimeUnit, ncData$time)
nLon = ncData[["lon"]]
nLat = ncData[["lat"]]
nSza = ncData[["CERES_solar_zenith_at_surface"]]
nRsr = ncData[["CERES_SW_TOA_flux___upwards"]]
nInsw = ncData[["TOA_Incoming_Solar_Radiation"]]
nDsr = ncData[["CERES_downward_SW_surface_flux___Model_B"]]
nSurfaceType = ncData[["Surface_type_index"]][1, ]
nClearFraction = ncData[["Clear_layer_overlap_percent_coverages"]][1, ]
-
NetCDF 변수들을 Data Frame 형태로 초기화
# Set Data Frame
dfData = data.frame(nDateTime, nLat, nLon, nSza, nRsr, nInsw, nDsr, nSurfaceType, nClearFraction)
# Print Data Frame
dplyr::tbl_df(dfData)

-
Data Frame를 통해 L1 전처리
-
각 변수에 따라 최소값/최대값 설정
-
# L1 Processing Using Data Frame
dfDataL1 = dfData %>%
dplyr::filter(
between(nLat, -90.0, 90.0)
, between(nLon, -180.0, 180.0)
, between(nSza, 0.0, 180.0)
, between(nRsr, 0.0, 1400.0)
, between(nInsw, 0.0, 1400.0)
, between(nDsr, 0.0, 1400.0)
, between(nSurfaceType, 1, 120)
, between(nClearFraction, 0, 100)
)
# Print Data Frame
dplyr::tbl_df(dfDataL1)

-
L1 자료를 이용해서 L2 전처리
-
NA 제거
-
# Delete NA Using L1 Data Frame
dfDataL2 = na.omit(dfDataL1)
# Print Data Frame
dplyr::tbl_df(dfDataL2)

-
L2 자료를 출력
-
옵션 설명
-
sep : 구분자
-
file : 출력 파일명
-
append : 이어쓰기 여부
-
row.names : 행 이름 포함 여부
-
col.names : 열 이름 포함 여부
-
-
# Write Using L2 Data Frame
write.table(
dfDataL2
, sep = " "
, file = sOutputFileDirName
, append = FALSE
, row.names = FALSE
, col.names = FALSE
)


[전체]
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'프로그래밍 언어 > R' 카테고리의 다른 글
| [R] 새해 경자년에 해돋이/일출/해 뜨는 시간 가시화 (0) | 2019.12.31 |
|---|---|
| [R] NetCDF 형식인 NPP/CERES SSF 1deg 기상위성 자료를 이용한 가시화 (0) | 2019.12.30 |
| [R] 다수의 날짜정보를 컬럼으로 가진 DataFrame 에서의 컬럼 제어 방법 (0) | 2019.12.21 |
| [R] 동아시아 대기질 이미지 영상을 통해 크롤링 및 애니메이션 구현 (0) | 2019.12.08 |
| [R] ggplot2를 이용한 Log 스케일로 산점도 가시화 (0) | 2019.12.06 |