

정보
-
업무명 : R을 이용한 프로그래밍 과제
-
작성자 : 이상호
-
작성일 : 2020-10-18
-
설 명 :
-
수정이력 :
내용
[개요]
-
안녕하세요? 웹 개발 및 연구 개발을 담당하고 있는 해솔입니다.
-
다년간 축적된 경험 (기상학 학술 보고서 및 국/영문 학술 논문 게재, 블로그 운영, IT 회사 웹 개발 담당) 및 노하우를 바탕으로 개개인에게 맞춤형 솔루션을 수행할 수 있습니다.
-
특히 재능 플랫폼 (크몽, 오투잡, 해피캠퍼스, 레포트 월드)에서 누구보다도 경쟁력 있는 가격으로 양질의 서비스를 제공하고 있습니다.
-
아스키 형식의 텍스트 (text) 파일부터 과학자료 형식 (HDF, H5, NetCDF, Grib, Grb) 및 Data Base (DB) 자료까지 다양한 형태의 자료를 이용하여 수집, 전처리, 분석, 시각화해 드립니다.
-
또한 웹 사이트에 대한 정보를 이용한 웹 크롤링 및 그에 따른 엑셀 및 DB 구축도 가능합니다.
-
아울러 기초 통계 (빈도분포, Prired t-test, Wilcoxn 등)에서 지도/비지도 학습을 통한 회귀모형 구축에 이르기 까지 효율적인 통계 정보를 제공합니다.
-
최근 대한민국의 후속위성인 천리안위성 2A호 웹 서비스 서브시스템 및 환경위성 2B호 통합 자료처리 서브시스템에 대한 웹 개발을 수행하였습니다.
-
-
그리고 해솔 블로그에서는 다양한 기상학/천문학 정보와 더불어 사무 자동화/프로그래밍 언어를 소개하오니 방문 부탁드립니다.
-
좋은 하루 보내세요.
[재능플랫폼] 오투잡
[IT개발 - 응용프로그래밍] 통계 분석, 데이터 분석, 시각화를 성실하게 해 드립니다. - 재능마켓 �
판매가격:10,000원, [소개] - 데이터산업진흥원 데이터 가공 공급기업 선정 - 정보통신산업 진흥원 데이터 가공 공급기업 선정 - 다년간 축적된 경험 노하우를 바탕으로 개개인에게 맞춤형 솔루션�
www.otwojob.com
[재능플랫폼] 크몽
데이터수집, 파싱, 크롤링 해 드립니다. | 50,000원부터 시작 가능한 총 평점 0점의 IT·프로그래밍,
0개 총 작업 개수 완료한 총 평점 0점인 shlee1990의 IT·프로그래밍, 데이터분석·리포트, 데이터 마이닝·크롤링 서비스를 0개의 리뷰와 함께 확인해 보세요. IT·프로그래밍, 데이터분석·리포트, 데
kmong.com
요청
[세부 사항]
-
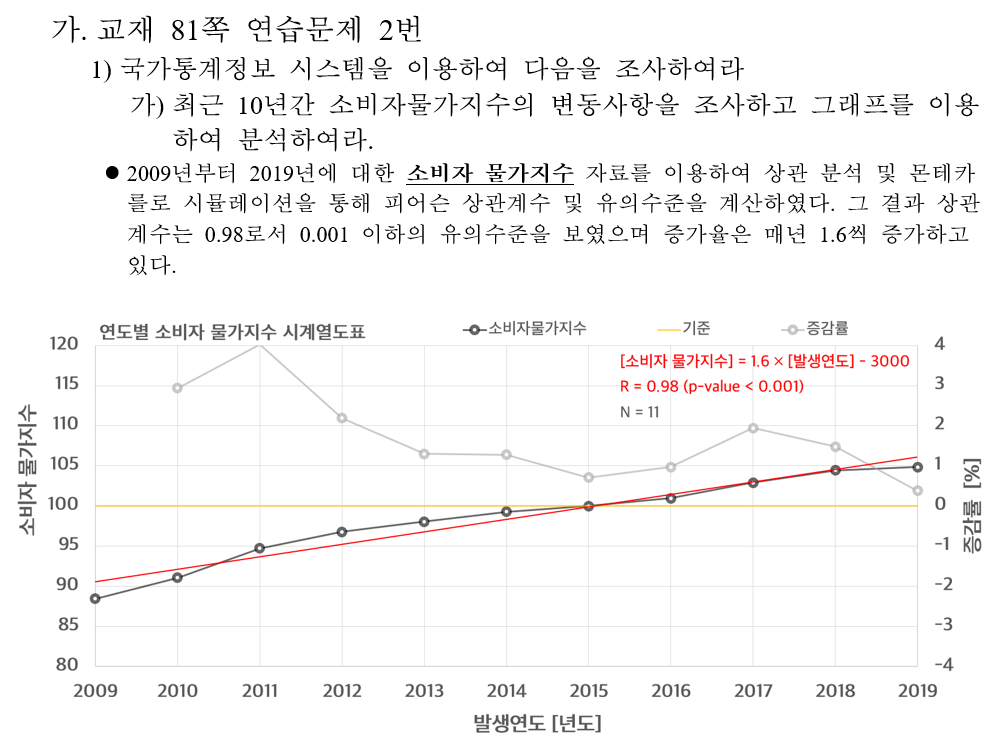
국가통계정보 시스템을 이용하여 다음을 조사하여라
-
최근 10년간 소비자물가지수의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
-
최근 10년간 국민소득의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
-
최근 10년간 수출 및 수입의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
-
-
태능선수촌에서 88올림픽에 대비하여 연습하고 있는 육상선수 중에서 25명을 뽑아 체격과 50 m 달기의 기록을 수집해 보니 다음과 같다. 성별은 (1) 남자 (2) 여자이고, 신장과 다리길이는 cm로, 체중은 kg으로, 50 m 달리기는 초 단위로 측정한 것이다.
-
성별로 신장, 체중, 다리길이, 50m 달리기의 기술통계량을 구하여라.
-
성별로 신장, 체중, 다리길이, 50m 달리기의 줄기-잎 그림과 히스토그램, 상자 그림을 그리고 설명하여라.
-
신장과 50m 달리기의 산점도를 성별로 구분하여 그리고 설명하여라.
-
-
다음은 두 명의 볼링선수가 10회 게임을 하여 그 점수를 기록한 것이다.
-
각 선수의 점수에 대한 평균값, 중앙값, 표준편차를 구하여라.
-
각 선수의 점수에 히스토그램, 줄기-잎 그림, 상자그림을 그려라.
-
누가 더 우수한 선수라고 판단되는가? 그 이유는?
-
완료
[사용 OS]
-
Windows 10
[사용 언어]
-
R v4.0.2
[명세]
- 라이브러리 읽기
library(dplyr)
library(ggplot2)
library(lubridate)
library(readr)
library(ggpubr)
국가통계정보 시스템을 이용하여 다음을 조사하여라
- 소비자 물가지수 변동사항 자료 읽기
# 1) 국가통계정보 시스템을 이용하여 다음을 조사하여라
# 가) 최근 10년간 소비자물가지수의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/소비자물가지수.csv", header = TRUE, fileEncoding = "euc-kr")
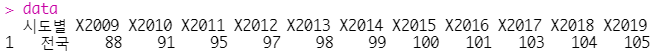
- 자료 전처리
- 가로형을 세로형으로 변환
- key을 이용하여 날짜형 (dtYear) 및 연도 (year) 환산
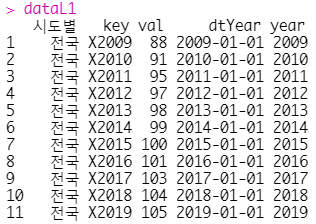
dataL1 = data %>%
tidyr::gather(-시도별, key = "key", value = "val") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
-
시각화
-
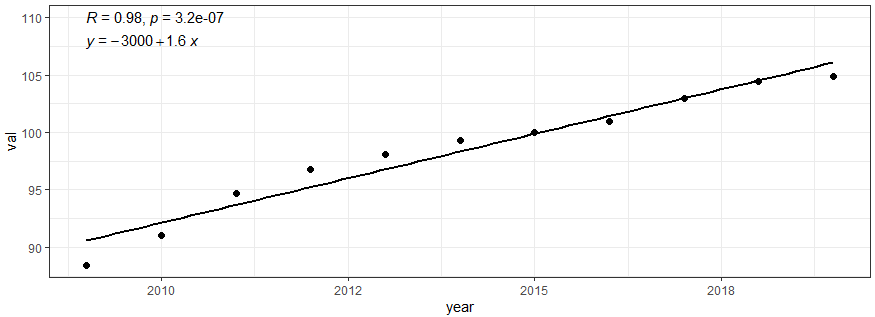
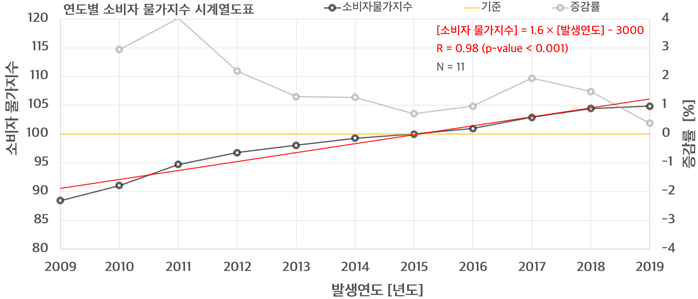
2009년부터 2019년에 대한 소비자 물가지수 자료를 이용하여 상관 분석 및 몬테카를로 시뮬레이션을 통해 피어슨 상관계수 및 유의수준을 계산하였다.
-
그 결과 상관 계수는 0.98로서 0.001 이하의 유의수준을 보였으며 증가율은 매년 1.6씩 증가하고 있다.
-
ggscatter(dataL1, x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2009, label.y = 110) +
stat_regline_equation(label.x = 2009, label.y = 108) +
theme_bw()
-
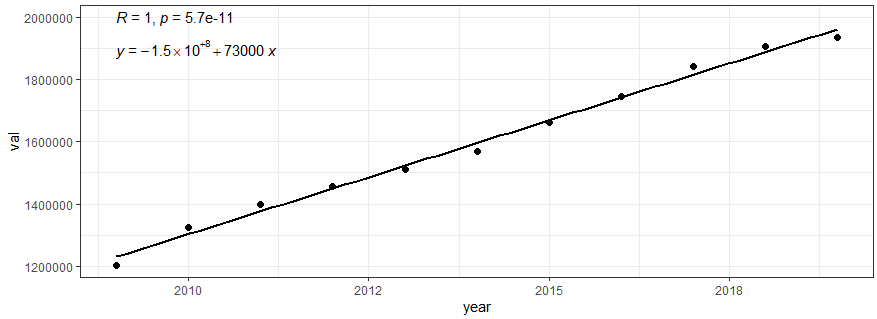
국민소득의 변동사항 자료 읽기와 전처리 및 시각화
-
2009년부터 2019년에 대한 국민 소득 자료를 이용하여 상관 분석 및 몬테카를로 시뮬레이션을 통해 피어슨 상관계수 및 유의수준을 계산하였다.
-
그 결과 상관 계수는 1.00로서 0.001 이하의 유의수준을 보였으며 증가율은 매년 73,000 [단위: 십억원]씩 증가하고 있다.
-
# 나) 최근 10년간 국민소득의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/연간지표.csv", header = TRUE, fileEncoding = "euc-kr")
dataL1 = data %>%
tidyr::gather(-연간지표별, key = "key", value = "val") %>%
dplyr::filter(연간지표별 == "국민총소득(명목, 원화표시) (십억원)") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
ggscatter(dataL1, x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2009, label.y = 2000000) +
stat_regline_equation(label.x = 2009, label.y = 1900000) +
theme_bw()

-
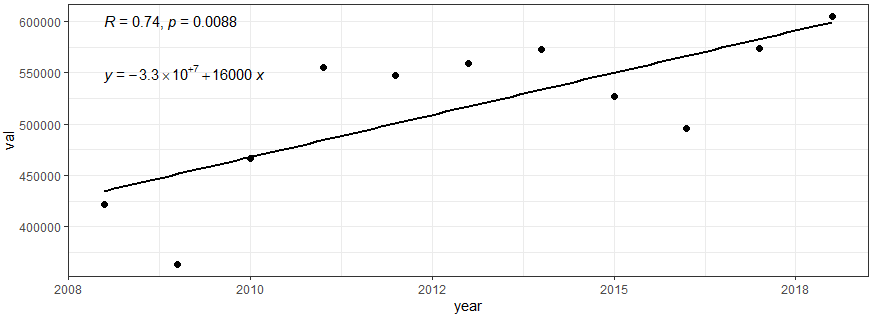
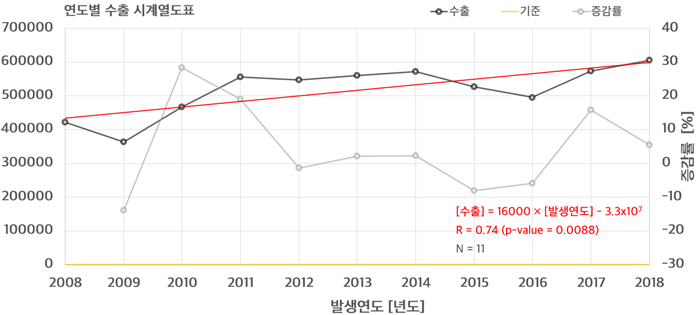
수출 및 수입의 변동사항 자료 읽기와 전처리 및 시각화
-
2008년부터 2018년에 대한 수출/수입 자료를 이용하여 상관 분석 및 몬테카를로 시뮬레이션을 통해 피어슨 상관계수 및 유의수준을 계산하였다.
-
그 결과 수출의 경우 상관 계수는 0.74로서 0.001 이하의 유의수준을 보였으며 증가율은 매년 16,000씩 증가하고 있다.
-
반면 수입에서는 수출에 비해 다소 낮은 상관 계수 (0.4) 및 유의수준 (0.22)으로서 미비한 증가율 (8,100)이 나타났다.
-
# 다) 최근 10년간 수출 및 수입의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/수출·수입_G20.csv", header = TRUE, fileEncoding = "euc-kr")
dataL1 = data %>%
tidyr::gather(-타입, key = "key", value = "val") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
# 수입
dataL1 %>%
dplyr::filter(타입 == "수입") %>%
ggscatter(x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2008, label.y = 600000) +
stat_regline_equation(label.x = 2008, label.y = 550000) +
theme_bw()
# 수출
dataL1 %>%
dplyr::filter(타입 == "수출") %>%
ggscatter(x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2008, label.y = 600000) +
stat_regline_equation(label.x = 2008, label.y = 550000) +
theme_bw()
-
수입
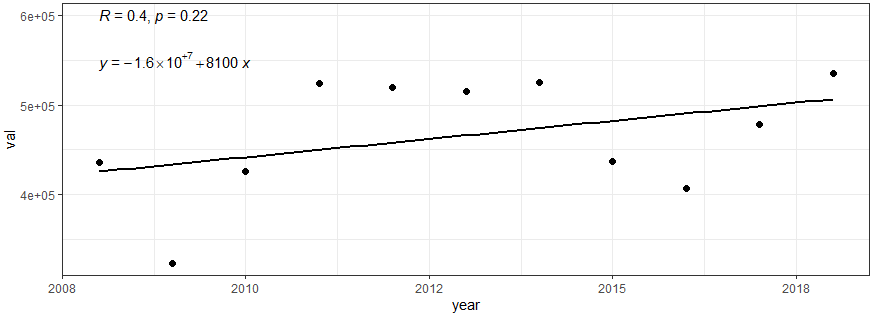
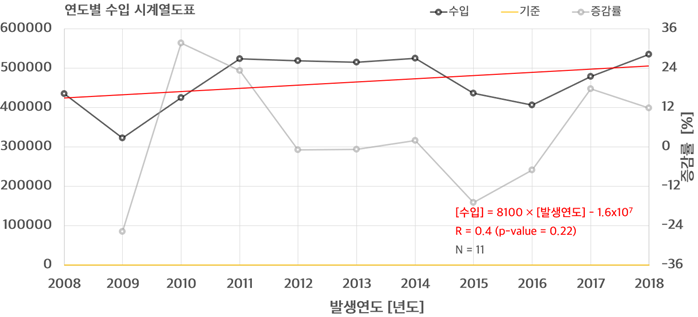
-
수출
태능선수촌에서 88올림픽에 대비하여 연습하고 있는 육상선수 중에서 25명을 뽑아 체격과 50 m 달기의 기록을 수집해 보니 다음과 같다. 성별은 (1) 남자 (2) 여자이고, 신장과 다리길이는 cm로, 체중은 kg으로, 50 m 달리기는 초 단위로 측정한 것이다.
# 1) 태능선수촌에서 88올림픽에 대비하여 연습하고 있는 육상선수 중에서 25명을 뽑아 체격과 50 m 달기의 기록을 수집해 보니 다음과 같다. 성별은 (1) 남자 (2) 여자이고, 신장과 다리길이는 cm로, 체중은 kg으로, 50 m 달리기는 초 단위로 측정한 것이다.
# dataN2 = data.frame(
# num = c(10010, 10012, 10015, 10017, 10021, 10023, 10044, 10055, 10059, 10060, 10065, 10070, 10072, 10074, 10079, 10080, 10090, 10093, 10096, 10101, 10103, 10118, 10123, 10125, 10126)
# , gender = c(1, 2, 1, 1, 2, 2, 1, 2, 1, 1, 1, 2, 1, 2, 2, 2, 1, 2, 2, 1, 1, 1, 2, 1, 1)
# , kidney = c(184.0, 160.3, 179.3, 176.2, 166.4, 168.0, 177.0, 162.4, 170.9, 188.3, 174.3, 171.7, 185.3, 165.5, 172.2, 168.6, 176.0, 168.1, 165.9, 183.0, 163.2, 176.5, 165.3, 180.9, 176.5)
# , weight = c(76.4, 57.2, 74.2, 68.2, 56.6, 64.8, 67.5, 51.2, 65.8, 77.5, 64.2, 62.6, 80.8, 64.5, 81.6, 68.0, 81.3, 72.3, 54.1, 84.0, 63.0, 68.3, 54.7, 96.0, 74.4)
# , legLength = c(101.6, 90.2, 99.4, 97.1, 91.0, 92.9, 103.6, 95.0, 79.5, 103.1, 102.7, 99.6, 101.2, 93.5, 97.5, 94.0, 95.6, 95.4, 92.6, 98.4, 86.7, 102.6, 96.5, 103.5, 95.1)
# , running = c(6.17, 6.87, 6.39, 6.77, 6.93, 7.15, 7.68, 7.50, 6.70, 6.58, 6.39, 6.92, 6.38, 6.91, 7.35, 7.12, 6.55, 7.26, 6.96, 6.48, 6.84, 6.00, 7.48, 6.71, 6.73)
# )
dataN2 = read.csv("INPUT/o2job/5번.txt", sep = "", header = TRUE, fileEncoding = "euc-kr")
# 가) 성별로 신장, 체중, 다리길이, 50m 달리기의 기술통계량을 구하여라.
dataN2 %>%
dplyr::group_by(sex) %>%
dplyr::summarise_all(funs(
mean(., na.rm = TRUE) # 평균값
, median(., na.rm = TRUE) # 중앙값
, sd(., na.rm = TRUE) # 표준편차
, max(., na.rm = TRUE) # 표준편차
, min(., na.rm = TRUE) # 표준편차
)) %>%
dplyr::glimpse()
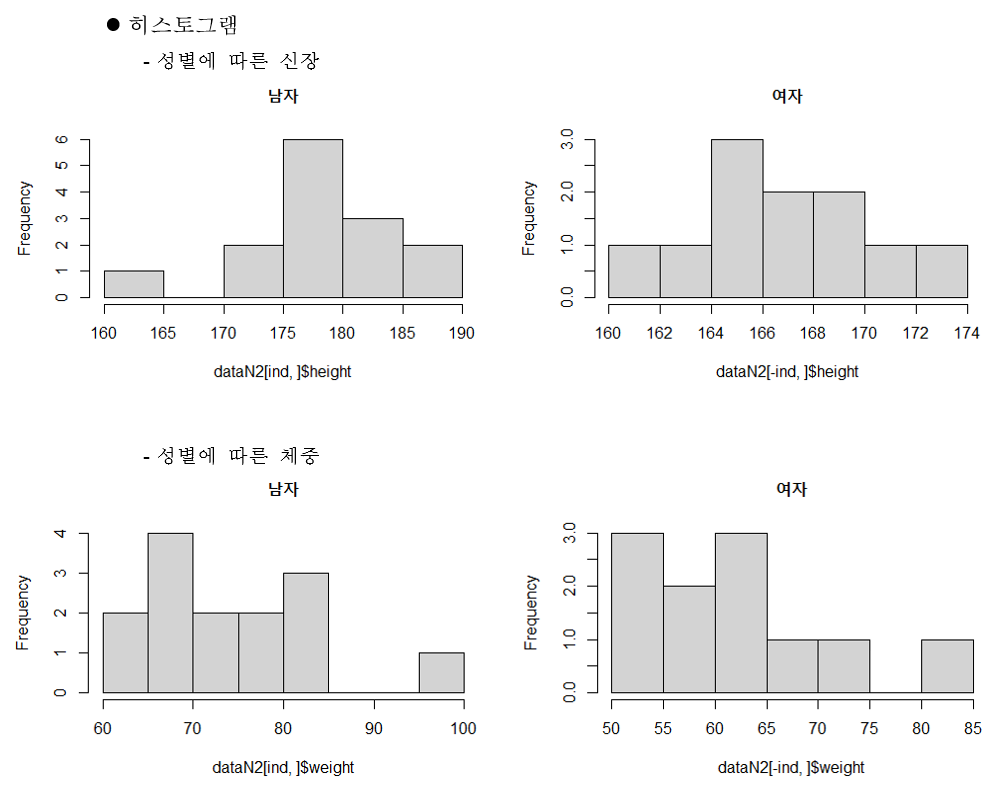
# 나) 성별로 신장, 체중, 다리길이, 50m 달리기의 줄기-잎 그림과 히스토그램, 상자 그림을 그리고 설명하여라.
# 줄기-잎 그림
ind = which(dataN2$sex == 1)
# 성별에 따른 신장
stem(dataN2[ind, ]$height)
stem(dataN2[-ind, ]$height)
# 성별에 따른 체중
stem(dataN2[ind, ]$weight)
stem(dataN2[-ind, ]$weight)
# 성별에 따른 다리길이
stem(dataN2[ind, ]$leg)
stem(dataN2[-ind, ]$leg)
# 성별에 따른 50m 달리기
stem(dataN2[ind, ]$run50)
stem(dataN2[-ind, ]$run50)
# 히스토그램
# 성별에 따른 신장도
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$height, main = "남자")
hist(dataN2[-ind, ]$height, main = "여자")
# ggplot(dataN2, aes(x = height, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 체중
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$weight, main = "남자")
hist(dataN2[-ind, ]$weight, main = "여자")
# ggplot(dataN2, aes(x = weight, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 다리길이
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$leg, main = "남자")
hist(dataN2[-ind, ]$leg, main = "여자")
# ggplot(dataN2, aes(x = leg, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 50m 달리기
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$run50, main = "남자")
hist(dataN2[-ind, ]$run50, main = "여자")
# ggplot(dataN2, aes(x = run50, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 상자그림
# 성별에 따른 신장
ggplot(dataN2, aes(x = height, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 체중
ggplot(dataN2, aes(x = weight, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 다리길이
ggplot(dataN2, aes(x = leg, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 50m 달리기
ggplot(dataN2, aes(x = run50, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 다) 신장과 50m 달리기의 산점도를 성별로 구분하여 그리고 설명하여라.
# 성별에 따른 신장
ggplot(dataN2, aes(x = height, y = run50, colour = as.factor(sex))) +
geom_point(alpha = 0.6, size = 5) +
scale_color_discrete(labels=c("남자", "여자"), name = "성별")
cor(dataN2[ind, ])
lm(dataN2[ind, ]$run50 ~ dataN2[ind, ]$height)
lm(dataN2[-ind, ]$run50 ~ dataN2[-ind, ]$height)
cor(dataN2[-ind, ])-
성별로 신장, 체중, 다리길이, 50m 달리기의 기술통계량을 구하여라.

다음은 두 명의 볼링선수가 10회 게임을 하여 그 점수를 기록한 것이다.
# 다. 다음은 두 명의 볼링선수가 10회 게임을 하여 그 점수를 기록한 것이다.
# dataN3 = data.frame(
# A = c(198, 119, 174, 235, 134, 192, 124, 241, 158, 176)
# , B = c(196, 159, 162, 178, 188, 169, 173, 183, 177, 152)
# )
dataN3 = read.csv("INPUT/o2job/6번.txt", sep = "", header = TRUE, fileEncoding = "euc-kr")
# 1) 각 선수의 점수에 대한 평균값, 중앙값, 표준편차를 구하여라.
dataN3L1 = dataN3 %>%
tidyr::gather(key = "key", value = "val")
dataN3L1 %>%
dplyr::group_by(key) %>%
dplyr::summarise_all(funs(
mean(., na.rm = TRUE) # 평균값
, median(., na.rm = TRUE) # 중앙값
, sd(., na.rm = TRUE) # 표준편차
)) %>%
glimpse()
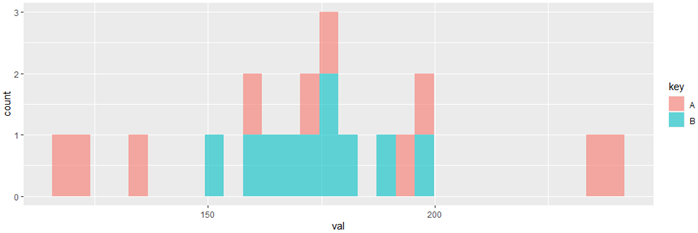
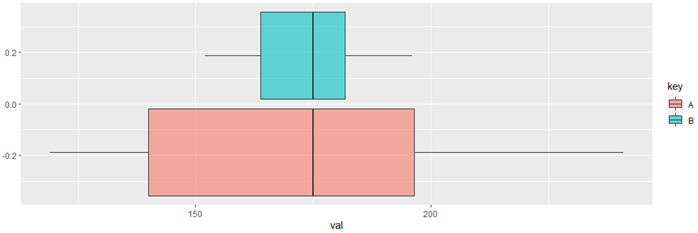
# 2) 각 선수의 점수에 히스토그램, 줄기-잎 그림, 상자그림을 그려라.
# 히스토그램
ggplot(dataN3L1, aes(x = val, fill = key)) +
geom_histogram(alpha = 0.6)
# 줄기-잎 그림
stem(dataN3$A)
stem(dataN3$B)
# 상자그림
ggplot(dataN3L1, aes(x = val, fill = key)) +
geom_boxplot(alpha = 0.6)
-
각 선수의 점수에 대한 평균값, 중앙값, 표준편차를 구하여라.

-
히스토그램
-
줄기-잎 그림

-
상자그림
[소스 코드]
#===============================================================================================
# Routine : Main R program
#
# Purpose : 재능상품 오투잡
#
# Author : 해솔
#
# Revisions: V1.0 May 28, 2020 First release (MS. 해솔)
#===============================================================================================
library(dplyr)
library(ggplot2)
library(lubridate)
library(readr)
library(ggpubr)
# 1) 국가통계정보 시스템을 이용하여 다음을 조사하여라
# 가) 최근 10년간 소비자물가지수의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/소비자물가지수.csv", header = TRUE, fileEncoding = "euc-kr")
dataL1 = data %>%
tidyr::gather(-시도별, key = "key", value = "val") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
ggscatter(dataL1, x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2009, label.y = 110) +
stat_regline_equation(label.x = 2009, label.y = 108) +
theme_bw()
# 나) 최근 10년간 국민소득의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/연간지표.csv", header = TRUE, fileEncoding = "euc-kr")
dataL1 = data %>%
tidyr::gather(-연간지표별, key = "key", value = "val") %>%
dplyr::filter(연간지표별 == "국민총소득(명목, 원화표시) (십억원)") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
ggscatter(dataL1, x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2009, label.y = 2000000) +
stat_regline_equation(label.x = 2009, label.y = 1900000) +
theme_bw()
# 다) 최근 10년간 수출 및 수입의 변동사항을 조사하고 그래프를 이용하여 분석하여라.
data = read.csv("INPUT/o2job/수출·수입_G20.csv", header = TRUE, fileEncoding = "euc-kr")
dataL1 = data %>%
tidyr::gather(-타입, key = "key", value = "val") %>%
dplyr::mutate(
dtYear = readr::parse_datetime(key, "X%Y")
, year = lubridate::year(dtYear)
)
# 수입
dataL1 %>%
dplyr::filter(타입 == "수입") %>%
ggscatter(x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2008, label.y = 600000) +
stat_regline_equation(label.x = 2008, label.y = 550000) +
theme_bw()
# 수출
dataL1 %>%
dplyr::filter(타입 == "수출") %>%
ggscatter(x = "year", y = "val", add = "reg.line") +
stat_cor(label.x = 2008, label.y = 600000) +
stat_regline_equation(label.x = 2008, label.y = 550000) +
theme_bw()
# 1) 태능선수촌에서 88올림픽에 대비하여 연습하고 있는 육상선수 중에서 25명을 뽑아 체격과 50 m 달기의 기록을 수집해 보니 다음과 같다. 성별은 (1) 남자 (2) 여자이고, 신장과 다리길이는 cm로, 체중은 kg으로, 50 m 달리기는 초 단위로 측정한 것이다.
# dataN2 = data.frame(
# num = c(10010, 10012, 10015, 10017, 10021, 10023, 10044, 10055, 10059, 10060, 10065, 10070, 10072, 10074, 10079, 10080, 10090, 10093, 10096, 10101, 10103, 10118, 10123, 10125, 10126)
# , gender = c(1, 2, 1, 1, 2, 2, 1, 2, 1, 1, 1, 2, 1, 2, 2, 2, 1, 2, 2, 1, 1, 1, 2, 1, 1)
# , kidney = c(184.0, 160.3, 179.3, 176.2, 166.4, 168.0, 177.0, 162.4, 170.9, 188.3, 174.3, 171.7, 185.3, 165.5, 172.2, 168.6, 176.0, 168.1, 165.9, 183.0, 163.2, 176.5, 165.3, 180.9, 176.5)
# , weight = c(76.4, 57.2, 74.2, 68.2, 56.6, 64.8, 67.5, 51.2, 65.8, 77.5, 64.2, 62.6, 80.8, 64.5, 81.6, 68.0, 81.3, 72.3, 54.1, 84.0, 63.0, 68.3, 54.7, 96.0, 74.4)
# , legLength = c(101.6, 90.2, 99.4, 97.1, 91.0, 92.9, 103.6, 95.0, 79.5, 103.1, 102.7, 99.6, 101.2, 93.5, 97.5, 94.0, 95.6, 95.4, 92.6, 98.4, 86.7, 102.6, 96.5, 103.5, 95.1)
# , running = c(6.17, 6.87, 6.39, 6.77, 6.93, 7.15, 7.68, 7.50, 6.70, 6.58, 6.39, 6.92, 6.38, 6.91, 7.35, 7.12, 6.55, 7.26, 6.96, 6.48, 6.84, 6.00, 7.48, 6.71, 6.73)
# )
dataN2 = read.csv("INPUT/o2job/5번.txt", sep = "", header = TRUE, fileEncoding = "euc-kr")
# 가) 성별로 신장, 체중, 다리길이, 50m 달리기의 기술통계량을 구하여라.
dataN2 %>%
dplyr::group_by(sex) %>%
dplyr::summarise_all(funs(
mean(., na.rm = TRUE) # 평균값
, median(., na.rm = TRUE) # 중앙값
, sd(., na.rm = TRUE) # 표준편차
, max(., na.rm = TRUE) # 표준편차
, min(., na.rm = TRUE) # 표준편차
)) %>%
dplyr::glimpse()
# 나) 성별로 신장, 체중, 다리길이, 50m 달리기의 줄기-잎 그림과 히스토그램, 상자 그림을 그리고 설명하여라.
# 줄기-잎 그림
ind = which(dataN2$sex == 1)
# 성별에 따른 신장
stem(dataN2[ind, ]$height)
stem(dataN2[-ind, ]$height)
# 성별에 따른 체중
stem(dataN2[ind, ]$weight)
stem(dataN2[-ind, ]$weight)
# 성별에 따른 다리길이
stem(dataN2[ind, ]$leg)
stem(dataN2[-ind, ]$leg)
# 성별에 따른 50m 달리기
stem(dataN2[ind, ]$run50)
stem(dataN2[-ind, ]$run50)
# 히스토그램
# 성별에 따른 신장도
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$height, main = "남자")
hist(dataN2[-ind, ]$height, main = "여자")
# ggplot(dataN2, aes(x = height, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 체중
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$weight, main = "남자")
hist(dataN2[-ind, ]$weight, main = "여자")
# ggplot(dataN2, aes(x = weight, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 다리길이
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$leg, main = "남자")
hist(dataN2[-ind, ]$leg, main = "여자")
# ggplot(dataN2, aes(x = leg, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 50m 달리기
par(mfrow = c(1, 2))
hist(dataN2[ind, ]$run50, main = "남자")
hist(dataN2[-ind, ]$run50, main = "여자")
# ggplot(dataN2, aes(x = run50, fill = as.factor(sex))) +
# geom_histogram(alpha = 0.6) +
# scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 상자그림
# 성별에 따른 신장
ggplot(dataN2, aes(x = height, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 체중
ggplot(dataN2, aes(x = weight, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 다리길이
ggplot(dataN2, aes(x = leg, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 성별에 따른 50m 달리기
ggplot(dataN2, aes(x = run50, fill = as.factor(sex))) +
geom_boxplot(alpha = 0.6) +
scale_fill_discrete(labels=c("남자", "여자"), name = "성별")
# 다) 신장과 50m 달리기의 산점도를 성별로 구분하여 그리고 설명하여라.
# 성별에 따른 신장
ggplot(dataN2, aes(x = height, y = run50, colour = as.factor(sex))) +
geom_point(alpha = 0.6, size = 5) +
scale_color_discrete(labels=c("남자", "여자"), name = "성별")
cor(dataN2[ind, ])
lm(dataN2[ind, ]$run50 ~ dataN2[ind, ]$height)
lm(dataN2[-ind, ]$run50 ~ dataN2[-ind, ]$height)
cor(dataN2[-ind, ])
# 다. 다음은 두 명의 볼링선수가 10회 게임을 하여 그 점수를 기록한 것이다.
# dataN3 = data.frame(
# A = c(198, 119, 174, 235, 134, 192, 124, 241, 158, 176)
# , B = c(196, 159, 162, 178, 188, 169, 173, 183, 177, 152)
# )
dataN3 = read.csv("INPUT/o2job/6번.txt", sep = "", header = TRUE, fileEncoding = "euc-kr")
# 1) 각 선수의 점수에 대한 평균값, 중앙값, 표준편차를 구하여라.
dataN3L1 = dataN3 %>%
tidyr::gather(key = "key", value = "val")
dataN3L1 %>%
dplyr::group_by(key) %>%
dplyr::summarise_all(funs(
mean(., na.rm = TRUE) # 평균값
, median(., na.rm = TRUE) # 중앙값
, sd(., na.rm = TRUE) # 표준편차
)) %>%
glimpse()
# 2) 각 선수의 점수에 히스토그램, 줄기-잎 그림, 상자그림을 그려라.
# 히스토그램
ggplot(dataN3L1, aes(x = val, fill = key)) +
geom_histogram(alpha = 0.6)
# 줄기-잎 그림
stem(dataN3$A)
stem(dataN3$B)
# 상자그림
ggplot(dataN3L1, aes(x = val, fill = key)) +
geom_boxplot(alpha = 0.6)
[결과물]
-
결과 보고서




참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'자기계발 > 재능상품' 카테고리의 다른 글
| [재능상품] Python을 이용한 CLT (Central Limit Theorem) 시연 (0) | 2020.10.18 |
|---|---|
| [재능상품] R을 이용한 부트스트랩 방법을 이용한 표본 평균 및 히스토그램 가시화 (0) | 2020.10.18 |
| [재능상품] Shell Script를 이용한 Bingo 함수 버전, 재귀 처리, 숫자 야구 (0) | 2020.10.18 |
| [재능상품] R을 이용한 점수 변화 그래프 및 바람 장미 시각화 (0) | 2020.10.12 |
| [재능상품] 통계 보고서 해석 (0) | 2020.10.11 |