

정보
-
업무명 : 데이터 정제를 위한 "dplyr, tidyr" 패키지 소개
-
작성자 : 박진만
-
작성일 : 2020-02-07
-
설 명 :
-
수정이력 :
내용
[특징]
-
R 에서 데이터를 조작하고 다루는 패키지 (dplyr, tidyr) 를 소개한다.
[기능]
-
변수 (열)의 선택
-
변수 (열)의 신규 생성 및 업데이트
-
레코드 (행)를 조건에 따라 추출 및 정렬
-
데이터 집계 (요약)
-
데이터 그룹화
-
여러 데이터 집합을 결합
-
wide 형 (가로형)과 long 형 (세로 형)를 변환
-
열 결합 및 분리
[활용 자료]
-
Iris 예제 데이터를 포함한 예시 데이터
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용법]
-
첨부코드 참조
[사용 OS]
-
Windows10
[사용 언어]
-
R v3.6.2
-
R Studio v1.2.5033
소스 코드
[개요]
-
dplyr, tidyr 은 R 에서 데이터 프레임을 조작하는 패키지
-
주로 데이터를 전처리를 위해 사용됨
-
%>% 파이프 연산자를 이용해 체인 형식의 코드 사용 가능
[해당 패키지의 장점과 단점]
-
장점
-
직관적이고 이해하기 쉬운 코드
-
불필요한 객체 생성이 필요없음.
-
빠른 처리속도 및 메모리 소모가 적음
-
dplyr과 tidyr 의 병행 사용이 가능
-
-
단점
-
사용 가능한 함수가 제한적임
-
코드 작성 방식에 있어서 심한 호불호 존재함
-
[명세]
[준비작업]
-
패키지 설치 및 로드
install.packages("dplyr")
install.packages("tidyr")
library(dplyr)
library(tidyr)
-
패키지 설치 확인
installed.packages() %>%
as.data.frame() %>%
select_("Package"," Version") %>%
filter(Package %in% c("dplyr", "tidyr"))-
패키지는 CRAN에서 다운 받아짐
-
성공적으로 패키지가 설치 되었다면 아래와 같은 메시지가 출력된다.
-
버전은 다를 수 있음.
-
본 글에서는 아래 이미지에 해당하는 버전으로 코드를 수행하였음
-
[열 선택]
-
변수 (열) 의 선택 : select
df <- iris %>%
dplyr::select(Sepal.Width,Species)
head(df, 3)
-
사용방법 : dplyr::select (데이터프레임, c(열1,열2...) )
-
열 지정 방법은 기본함수인 "subset" 과 동일함
-
열 지정의 경우 특별한 기능을 사용할 수 있음 (하단 참조)
-
열 선택용 함수 : starts_with()
df <- iris %>%
dplyr::select(starts_with("sepal"))
head(df, 3)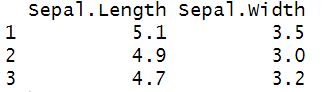
-
start_with (x, ignore.case = TRUE)
-
열의 시작 글자가 일치하는 변수를 검색함
-
덧붙여 ignore.case = FALSE로 하면 대소문자 구분이 가능함
-
열 선택용 함수 : contains()
df <- iris %>%
dplyr::select(contains("pe"))
head(df, 3)
-
ontains (x, ignore.case = TRUE)
-
열 이름이 부분적으로 일치하는 경우 열 이름을 검색하여 가져옴
-
열 선택용 함수 : matches()
df <- iris %>%
dplyr::select(matches(".t."))
head(df, 3)
-
[matches (x, ignore.case = TRUE)
-
정규 표현식을 지정하고 변수를 가져 옴
-
열 선택용 함수 : num_range()
df <- as.data.frame(matrix(1:30, nrow = 3, ncol = 10))
colnames(df) <- c(paste0("beer", 1:5), paste0("sake0", 1:5))
ls(df)
dplyr::select(df, num_range("beer", 1:3, 1))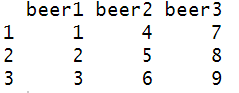
dplyr::select(df, num_range("sake", 2:4, 2))
-
num_range ( "문자열",대상의 숫자, 자릿수)
-
"beer1에서 beer3까지" 형식의 지정 방법. 즉 열 이름에 번호가 부여되어 있어야 함.
-
열 선택용 함수 : one_of()
vname <- c("Petal.Length", "Sepal.Width")
df <- iris %>%
dplyr::select(one_of(vname))
head(df, 3)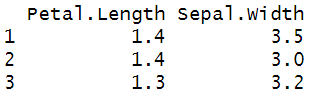
-
변수 이름을 문자열 벡터로 정리해 전달 때 사용.
-
열 선택용 함수 : everything()
df <- as.data.frame(matrix(1:15, nrow = 3, ncol = 5))
colnames(df) <- c("Incheon", "Pusan", "Daegu", "Daesjeon", "Ulsan")
dplyr::select(df, everything())
dplyr::select(df, Incheon, Pusan, everything())
-
전부 가져옴
[열 신규 생성 및 업데이트]
-
dplyr::mutate
df <- iris %>%
dplyr::mutate(beer=Sepal.Width*2)
head(df, 2)
df <- iris %>%
dplyr::mutate(beer=Sepal.Width*3)
head(df, 2)
-
dplyr :: mutate (데이터프레임, 변수이름 = 처리내용)
-
데이터 프레임에 새로운 열을 추가
-
변수 이름에 기존 변수를 지정하면 덮어쓰기됨
[조건에 따른 행 추출 및 정렬]
-
dplyr::filter()
df <- iris %>%
dplyr::filter(Species=='virginica')
head(df, 3)
-
dplyr :: filter (데이터 프레임 조건식)
-
사용법은 subset ()과 동일
-
dplyr::arrange()
df <- iris %>%
dplyr::arrange(Sepal.Length)
head(df, 3)
df <- iris %>%
dplyr::arrange(desc(Sepal.Length))
head(df, 3)
-
asc 또는 아무것도 안 적음 : 오름차순 정렬
-
desc : 내림차순 정렬
-
두개 이상의 열에 대해서도 가능
[데이터 집계 및 요약]
-
dplyr::summarize()
df <- iris %>%
dplyr::summarize(varmean=mean(Sepal.Length))
df
-
dplyr :: summarize (데이터 프레임, 새로운 변수 이름 = 함수 (처리 대상의 변수 이름))
-
열의 집계를 산출
-
각종 집계 함수 sum, sd, mean 등 사용 가능
[기타 summarize 관련 함수]
-
이외에도 summarize_if(), summarize_at(), summarize_all()가 존재함
-
자세한 내용은 dplyr 도움말 참조
[데이터 그룹화]
-
dplyr::group_by()
df <- iris %>%
dplyr::group_by(Species) %>%
dplyr::summarize(cmean=mean(Sepal.Length))
df
-
dplyr :: group_by (변수1,변수2...)
-
위 코드를 실행하면 데이터가 그룹화 됨
-
이 후 summarize 등 그룹별로 원하는 작업을 수행할 수 있다.
[여러 데이터 세트 결합]
-
데이터 세트 준비
a <- data.frame(x1=c("A","B","C"),x2=1:3)
b <- data.frame(x1=c("A","B","D"),x3=c(TRUE, FALSE, TRUE))
y <- data.frame(x1=c("A","B","C"),x2=1:3)
z <- data.frame(x1=c("B","C","D"),x2=2:4)
- dplyr::full_join()
df <- dplyr::full_join(a,b,by="x1")

-
dplyr :: full_join (데이터 프레임 1, 데이터 프레임 2, by = 키 변수)
-
모든 행과 열을 결합
-
해당 사항이없는 경우 NA이 들어가게 됨
-
dplyr::inner_join()
df <- dplyr::inner_join(a,b,by="x1")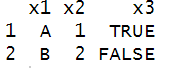
-
dplyr :: inner_join (데이터 프레임 1, 데이터 프레임 2, by = 키 변수)
-
두 데이터 프레임에 존재하는 행만을 남겨 결합함
-
dplyr::bind_cols()
df <- dplyr::bind_cols(y, z)
df
-
왼쪽의 데이터 프레임에 오른쪽 데이터 프레임의 열을 추가함
-
행 수가 일치하지 않은경우 오류가 발생함
-
dplyr::bind_rows()
df <- dplyr::bind_rows(y, z)
df
-
왼쪽의 데이터 프레임에 오른쪽 데이터 프레임의 행을 추가함
-
열 수가 일치하지 않은경우 오류가 발생함
-
dplyr::bind_rows(... .id=)
df <- dplyr::bind_rows(y, z, .id = "df_id")
df
-
인수 .id=**를 지정하면 테이블 id를 변수로 만들어줌
-
이는 굉장히 편리한 기능임
[데이터프레임의 행,열을 변환]
-
tidyr :: gather()
df <- iris %>%
tidyr::gather(key = keykey, value = valuevalue, -Species)
head(df, 4)
-
data : 사용하는 데이터 프레임
-
key : 정리했을 때, "이 행의 값은 어떤 변수에 들어갈 것인가"를 나타내는 변수.
-
value : 정리 한 변수의 값.
-
... : 정리할 변수를 지정한다. 즉 dplyr :: select ()의 기법을 그대로 사용할 수 있음.
-
tidyr :: spread()
df <- iris %>%
dplyr::mutate(id=rownames(iris)) %>%
tidyr::gather(key = keykey, value = valuevalue, contains("l."))
head(df,2)
df_2 <- df %>%
tidyr::spread(key = keykey, value = valuevalue)
head(df_2,2)
-
gather과 반대로 작용함.
-
그러나 spread를 실행 한 후 기본 키가 될 수 있는 변수가 존재할 필요가 있음
[열 결합 및 분리]
-
tidyr::unite
df <- iris %>%
tidyr::unite(col = colll, starts_with("Sepal"), sep = "-")
head(df)
-
여러개의 열을 하나로 합침
-
tidyr : separate
df <- iris %>%
tidyr::unite(col = colll, starts_with("Sepal"), sep = "-")
df2 <- df %>%
tidyr::separate(col = colll, into = c("Sepal.Length","Sepal.Width"), sep = "-")
head(df2)
-
하나의 열을 지정한 문자로 분할하여 별도의 열에 지정함
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'프로그래밍 언어 > R' 카테고리의 다른 글
| [R] 범주형 데이터 (Factor) 를 다루는 "forcast" 패키지 소개 (0) | 2020.02.10 |
|---|---|
| [R] 문자열 조작 "stringr" 패키지 소개 (1) | 2020.02.09 |
| [R] 기상 관측소 정보를 이용하여 태양 위치 시간 (일출/일몰/아침 골든/남중/저녁 골든/일몰/항해 박명/천문 박명/밤/아침 박명) 계산 (0) | 2020.01.09 |
| [R] 정지궤도/극궤도 기상위성으로부터 시공간 일치 자료 (Himawari-8/AHI vs Terra/CERES)를 이용한 2차원 빈도분포 산점도 (0) | 2020.01.07 |
| [R] 직달 일사량 자료를 이용한 일조량 산출 및 비교 분석 (0) | 2020.01.06 |