

정보
-
업무명 : 문자열 조작 "stringr" 패키지 소개
-
작성자 : 박진만
-
작성일 : 2020-02-09
-
설 명 :
-
수정이력 :
내용
[특징]
-
R 에서 문자열을 다루고 조작하는 패키지
[활용 자료]
-
본문의 소스코드 실행
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용 OS]
-
Windows10
[사용 언어]
-
R v3.6.2
-
R Studio v1.2.5033
소스 코드
-
기본적 특징
-
base 함수보다 빠름.
-
함수 이름이 "str_"로 시작됨
-
주요 문자열 처리는 이것 하나로 가능
-
"%> %" - 파이프 연산자
-
기존의 stringi 패키지를 wrapping 하였음.
-
[명세]
설치
- 1. CRAN 에서 설치
install.packages("stringr")
- 2. GitHub 에서 설치
devtools::install_github("hadley/stringr")
-
3. GitHubinstall 을 이용하여 설치
githubinstall::githubinstall("stringr")
문자열 가공
-
문자열 연결 : str_c()
-
문자열을 연결시키는 함수
-
paste()처럼 사용할 수 있음
-
str_c("Heasol", "Blog", sep = " ")
-
문자열 벡터의 요소를 하나로 연결하려면 collapse=옵션을 사용
-
이 부분도 paste()마찬가지로 사용할 수 있음.
x <- c("Seoul", "Busan", "Incheon")
str_c(x, collapse = ", ")
- 문자열 벡터끼리 결합 역시 가능
y <- c("Special City", "City", "City")
(ni <- str_c(x, y, sep="-"))
-
문자열 분할 : str_split()
-
패턴이 일치하는 지점에서 분할시킴
-
결과는 리스트 형식
-
str_split(ni, pattern = "-")
-
simplify=TRUE 옵션을 주는 경우 결과가 매트릭스 형으로 반환됨
str_split(ni, pattern = "-", simplify = TRUE)
- "n=" 옵션을 사용하는 경우 선택적으로 분할 개수를 지정할 수 있음
- 분할 지점은 문자열의 앞 부분 부터 우선하게 됨
str_split("S-e-o-u=l", pattern = "-", n=3)
-
문자열 분할 : str_split_fixed()
-
str_split()마찬가지로 문자열을 분할하는 함수
-
그러나 구분할 문자가 없는 경우 경우 길이가 0 인 문자열이 들어가게 됨
-
a <- c("Seoul-City","Heasol-Blog","Good")
str_split_fixed(a, pattern="-", n=2)
문자열 검색
-
문자 포함 여부 검색 (논리값 리턴) : str_detect()
-
벡터에서 패턴과 일치하는 문자가 있는지 여부를 판정
-
반환 값은 논리벡터 (TRUE or FALSE)
-
x <- c("Seoul", "Busan", "Incheon")
str_detect(x, pattern="Se")
-
패턴에 정규 표현식을 사용하는 것도 가능함.
str_detect(x,pattern="l$")
-
문자 포함 여부 검색 (요소값 리턴) : str_subset()
-
벡터에서 패턴과 일치하는 문자가 있는지 여부를 판정
-
반환 값은 일치하는 문자열 백터
-
str_subset(x, pattern="S")
문자열 치환
-
문자열 치환 (앞부분 치환) : str_replace()
-
패턴과 일치하는 문자열 치환
-
일치하는 패턴이 여러개인 경우 가장 앞 부분만을 치환시킴
-
str_replace(x, pattern="n", replacement="*")
-
문자열 치환 (모두 치환) : str_replace_all()
-
패턴과 일치하는 문자열 치환
-
일치하는 패턴이 여러개인 경우 모두 치환시킴
-
str_replace_all(x, pattern="n", replacement="*")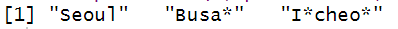
문자열 추출
-
일치하는 요소를 추출 : str_extrcat()
-
패턴과 일치하는 부분만 추출
-
변환값은 백터값임
-
일치하는 패턴이 여러개인 경우 가장 앞의 하나만 추출함
-
str_extract(x, pattern="n")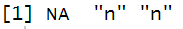
-
일치하는 모든 요소를 추출 : str_extract_all()
-
패턴과 일치하는 부분 모두 추출
-
반환 값은 기본적으로 리스트
-
str_extract_all(x, pattern="n")
-
수치로 지정하여 추출 : str_sub()
-
start로 시작위치, end 로 끝 위치 지정
-
마이너스(-) 를 사용하면 뒤에서부터 지정
-
str_sub(x, start=1, end=4)
str_sub(x, start=4, end=-1)
기타
-
문자 인코딩 : str_conv()
-
문자를 인코딩 시켜줌
-
iconv() 와 동일
-
str_conv(x, encoding="UTF-8")-
그 외
-
문자열 추출 (그룹) : str_match()
-
조건을 포함한 부분의 계산 : str_count()
-
패턴의 위치 : str_locate()
-
문자열의 길이 : str_length()
-
문자열의 반복 : str_dup()
-
[전체 코드]
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'프로그래밍 언어 > R' 카테고리의 다른 글
| [R] ggplot2에서 텍스트 추가를 위한 "ggfittext" 패키지 소개 (0) | 2020.02.12 |
|---|---|
| [R] 범주형 데이터 (Factor) 를 다루는 "forcast" 패키지 소개 (0) | 2020.02.10 |
| [R] 데이터 정제를 위한 "dplyr, tidyr" 패키지 소개 (0) | 2020.02.08 |
| [R] 기상 관측소 정보를 이용하여 태양 위치 시간 (일출/일몰/아침 골든/남중/저녁 골든/일몰/항해 박명/천문 박명/밤/아침 박명) 계산 (0) | 2020.01.09 |
| [R] 정지궤도/극궤도 기상위성으로부터 시공간 일치 자료 (Himawari-8/AHI vs Terra/CERES)를 이용한 2차원 빈도분포 산점도 (0) | 2020.01.07 |