

정보
-
업무명 : 정보처리기사 실기 : 28강 응용 SW 기초 기술 활용 (데이터베이스 기초 활용하기)
-
작성자 : 이상호
-
작성일 : 2020-05-10
-
설 명 :
-
수정이력 :

내용
[데이터베이스 종류 및 선정]
[1] 데이터베이스 종류
-
1. 데이터베이스 개요
-
데이터베이스는 다수의 인원, 시스템 또는 프로그램이 사용할 목적으로 통합하여 관리되는 데이터의 집합이다.
-
IT 시스템의 발달로 인해 급증하는 데이터에 대한 효과적인 관리 가 중요해졌다. 자료의 중복성 제거, 무결성 확보, 일관성 유지, 유용성 보장은 데이터베이스 관리의 핵심이다.
-
DBMS(Database Management System)는 위와 같은 데이터 관리의 복잡성을 해결하는 동시 에 데이터 추가, 변경, 검색, 삭제 및 백업, 복구, 보안 등의 기능을 지원하는 소프트웨어 이다.
-
저장되는 정보는 텍스트, 이미지, 음악 파일, 지도 데이터 등 매우 다양하며, SNS의 발달과 빅데이터의 폭넓은 활용으로 인해 데이터의 종류와 양은 급격히 증가 중이다.
-
-
2. 데이터베이스 종류
-
(1) 파일시스템 파일에 이름을 부여하고 저장이나 검색을 위하여 논리적으로 그것들을 어디에 위치시켜야 하는지 등을 정의한 뒤 관리하는 데이터베이스 전 단계의 데이터 관리 방식이다.
-
ISAM(Indexed Sequential Access Method): 자료 내용은 주저장부, 자료의 색인은 자료가 기록된 위치와 함께 색인부에 기록되는 시스템- VSAM(Virtual Storage Access Method): 대형 운영 체계에서 사용되는 파일 관리시스템
-
-
(2) 계층형 데이터베이스 관리시스템(HDBMS: Hierarchical Database Management System)
데이터를 상하 종속적인 관계로 계층화하여 관리하는 데이터베이스이다. 데이터에 대 한 접근 속도가 빠르지만, 종속족인 구조로 인하여 변화하는 데이터 구조에 유연하게 대응하기가 쉽지 않다. IMS, System2000과 같은 제품이 있다. -
(3) 망형 데이터베이스 관리시스템(NDBMS: Network Database Management System)
데이터의 구조를 네트워크상의 망상 형태로 논리적으로 표현한 데이터 모델이다. 트리 구조나 계층형 데이터베이스보다는 유연하지만 설계가 복잡한 단점이 있다. IDS, TOTAL, IDMS와 같은 제품이 있다. -
(4) 관계형 데이터베이스 관리시스템(RDBMS: Relational Database Management System)
가장 보편화된 데이터베이스 관리시스템이다. 데이터를 저장하는 테이블의 일부를 다른 테이블과 상하 관계로 표시하며 상관관계를 정리한다. 변화하는 업무나 데이터 구 조에 대한 유연성이 좋아 유지 관리가 용이하다.-
Oracle: 미국 오라클사에서 개발한 데이터베이스 관리시스템으로 유료이다. 리눅스/ 유닉스/윈도 모두를 지원하며 대형 시스템에서 많이 사용한다.
-
SQL Server: 마이크로소프트사에서 개발한 관계형 데이터베이스 시스템이다. 마이크로소프트사 제품이기 때문에 윈도즈 서버에서만 구동이 되며, 마이크로소프트사의 개발언어인 C# 등과 가장 잘 호환된다.
-
MySQL: 썬 마이크로시스템에서 소유했던 관계형 데이터베이스 시스템이었으나 오라클에서 인수하였다. 리눅스, 유닉스, 윈도에서 모두 사용이 가능하고 오픈소스 기반 으로 개발되었다. - Maria DB: MySQL 출신 개발자가 만든 데이터베이스로 MySQL과 완벽히 호환된다.
-
-
-
3. 데이터베이스 관리시스템(DBMS) 특징
-
데이터 무결성: 부적절한 자료가 입력되어 동일한 내용에 대하여 서로 다른 데이터가 저장되는 것을 허용하지 않는 성질
-
데이터 일관성: 삽입, 삭제, 갱신, 생성 후에도 저장된 데이터가 변함없이 일정
-
데이터 회복성: 장애가 발생하였을 시 특정 상태로 복구되어야 하는 성질
-
데이터 보안성: 불법적인 노출, 변경, 손실로부터 보호되어야 하는 성질
-
데이터 효율성: 응답 시간, 저장 공간 활용 등이 최적화되어 사용자, 소프트웨어, 시스템 등의 요구 조건을 만족 시켜야 하는 성질
-
-
4. 상용 데이터베이스 관리시스템 및 오픈소스 기반 데이터베이스 관리시스템
-
상용 데이터베이스 관리시스템은 특정 회사에서 유료로 판매하는 시스템이다. 유지 보 수와 지원이 원활한 장점이 있다.
-
오픈소스 기반 데이터베이스 시스템은 오픈소스 라이선스 정책을 준용하는 범위 내에 서 사용이 자유롭다. 최근 사용 비중이 증가하고 있다.
-
[관계형 데이터베이스 활용]
[1] ERD(E-R Diagram)
-
1. ERD 개요
-
ERD는 업무 분석 결과로 도출된 실체(엔티티)와 엔티티 간의 관계를 도식화한 것이다. ERD로 요소들 간 연관성을 도식화하여 데이터베이스 관리자, 개발자, 사용자 모두 데이터 의 흐름과 연관성을 공통적으로 쉽게 확인할 수 있다.
-
-
2. ER Model
-
ERD의 구성 요소인 개체, 관계, 속성을 추출하기 위해서는 업무나 시스템에 대한 명확한 정의가 있어야 한다. ERD로 도식화하기 전 각 개체를 사각형, 화살표, 마름모로 표기한 형태를 ER 모델이라고 한다.
-

-
(1) 엔티티(Entity)
-
사물 또는 사건으로 정의되며 개체라고도 한다. ERD에서 엔티티는 사각형으로 나타내 고 사격형 안에는 엔티티의 이름을 넣는다.
-
가능한 한 대문자로 엔티티 이름을 써 주며 단수형으로 명명한다.
-
유일한 단어로 정한다.
-
-
-
(2) 속성(Attribute)
-
엔티티가 가지고 있는 요소 또는 성질을 속성이라 부른다. 속성은 선으로 연결된 동그 라미로 표기(Chen Model)하거나 표 형식으로 표기(Crow's Foot Model)하기도 한다. 관계형 데이터베이스 활용을 위해서는 Crow's Foot Model이 편리하다.
-
속성명은 단수형으로 명명한다.
-
엔티티명을 사용하지 않는다.
-
속성이 필수 사항(Not Null)인지, 필수 사항이 아닌지(Null) 고려하여 작성한다.
-
-

-
(3) 관계(Relationship) 두 엔티티 간의 관계를 정의한다. 개체는 사각형(□), 속성은 타원형(○)을 이용하여 표시하며, 관계 표시는 를 참조한다.

[2] ERD(E-R Diagram) 작성
-
1. ERD 작성 표기
-
ERD는 종이, 화이트보드, 포스트잇, 전문 소프트웨어 등을 사용하여 작성자가 원하는 도 구를 사용하여 작성하면 된다. 최근에는 업무를 효과적으로 분석하는 툴들로부터 결과를 추출하여 자동으로 ERD를 작성하여 주는 소프트웨어도 시중에 많이 출시되었다.
-
-
2. ERD 최적화
-
(1) 테이블 정의 : 업무나 시스템을 분석하여 엔티티, 속성을 추출한 뒤 테이블을 작성한다.
-
(2) 정규화 수행 :데이터베이스 정규화는 무결성을 확보하고 중복성을 배제하여 테이블에 정확한 데이터가 들어가도록 하는 데 목적이 있다. 데이터의 중복성을 없애면 저장 공간을 최소화 하고 시스템의 속도 또한 빠르게 할 수 있다.
-
1차 정규화: 반복되는 그룹의 속성을 별도로 추출한다.
-
2차 정규화: 부분 함수적 종속성을 제거한다.
-
3차 정규화: 키에 종속되지 않은 칼럼을 제거한다.
-
-
(3) ERD 관계형 스키마(논리 모델, 물리 모델) 작성
-
사용자가 식별하기 쉬운 한글 또는 영어 단어로 작성된 논리 ERD를 작성한다. 시스템 이 식별하기 쉽도록 코드화된 물리 ERD를 작성한다.
-
-

[3] 관계형 데이터베이스 테이블 생성
-
1. 생성 언어
-
데이터베이스의 종류와 상관없이 명령어는 국제 표준으로 제정된 SQL(Structured Query Language)를 사용한다. 미국 표준 연구소인 ANSI와 국제 표준화 기구인 ISO에서 SQL을 관계 데이터베이스의 표준 질의어로 채택하고 표준화하고 있다.
-
-
2. 테이블 관리
-
쿼리 명령어 “Create”를 사용하면 테이블 및 속성을 생성할 수 있다. (예: CREATE TABLE table_name (column1 datatype, column2 datatype, ....);
-
쿼리 명령어 “Drop”을 사용하면 테이블을 삭제할 수 있다. (예: DROP TABLE table_name ;)
-
쿼리 명령어 “Show tables”를 사용하면 테이블의 내용을 확인할 수 있다.
-
[수행]
[1] ERD를 작성한다.
-
1. ERD 작성을 위한 요소를 추출한다. 업무의 흐름으로부터 개체, 관계, 속성을 구분해 내야 한다. 다음 시나리오에서 세 가지 요소를 추출한 뒤 의 결과와 비교한다.

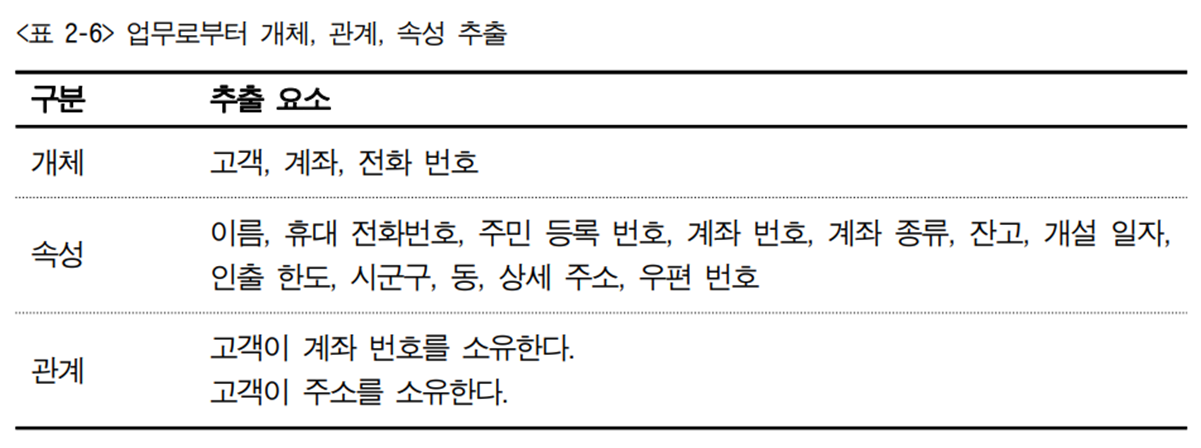
-
2. ERD를 작성한다.
-
추출된 요소를 가지고 ERD를 작성한다. 일부 작성된 ERD에 추출 요소들을 입력한다.
-
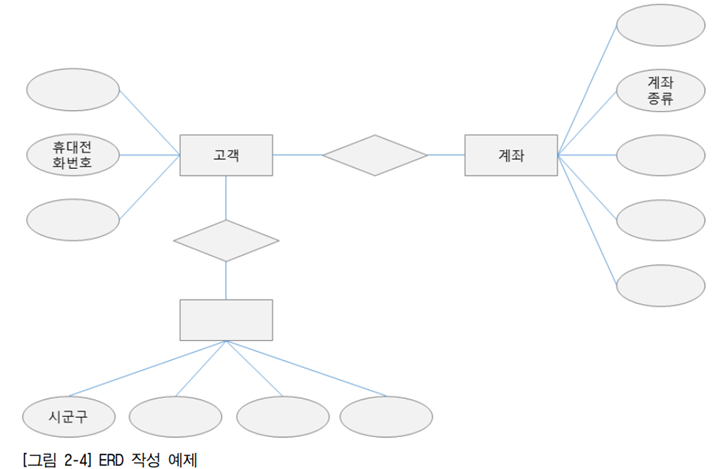
[2] ERD 관계형 스키마를 작성한다.
-
작성된 ERD에 다음의 추가적인 제약 조건을 고려하여 논리 관계형 스키마를 작성한다.
-
1. 관계형 스키마 작성을 위해 테이블 형태로 표시한다.
-
테이블의 가장 위 칸은 유일하게 필드를 구분할 수 있는 구분자(유일키)가 되어야 한다. 유일키를 만드는 방법은 여러 가지가 있으며 일련번호를 부여하기도 한다.
-
유일키 아래 칸에는 속성들을 기입한다.
-


-
2. 테이블 간 관계를 설정한다.
-
테이블 간 관계를 표시한다. 표기 시에는 1:1, 1:N, N:1, N:N의 관계를 고려해야 한다.
-
테이블 간 연결할 수 있는 속성을 부여하여 하나의 테이블에서 다른 테이블의 값을 찾아갈 수 있어야 한다.
-

[3] 관계형 데이터베이스 테이블을 생성한다
-
1. 관계형 테이블 생성을 위한 물리 스키마을 작성한다.
-
SQL 표준 언어는 한글 입력이 허용되지 않는다. 위 논리 스키마와 매칭되는 물리 스키마 를 작성한다.
-

-
2. 테이블 생성을 위한 SQL 명령어를 작성한다.
-
작성 시 필요한 datatype은 정수형, 실수형, 날짜형 등 다양하다. SQL 표준을 참조하여 필요로 하는 데이터 형을 입력하도록 한다.
-

[4] ERD 작성을 위한 자동화 툴을 사용하여 생산성을 높인다.
-
ERD를 종이나 파워포인트 같은 툴로 그리는 것은 한계가 있다. 무료로 배포되는 ERD 작 성 툴을 활용하여 ERD를 작성해 본다. DbDesigner와 같은 무료 소프트웨어를 사용하면 생산성을 높일 수 있는데, 무료로 배포되고 있는 소프트웨어가 많으므로 자신에게 적합한 툴을 선택하여 사용한다.
[데이터베이스 관리]
[1] 데이터베이스 기본 연산
-
CRUD는 데이터베이스가 가지는 기본적인 데이터 처리 기능인 Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 말한다.

[2] 데이터베이스 관리 툴
-
Oracle, DB2, SAP, SQL Server, Edge 등의 상용 데이터베이스를 편리하게 관리하기 위하 여 다양한 관리 툴을 사용한다.
-
1. 툴 선정 시 고려 사항
-
협업: 개발자, 품질 담당자, 필요에 따라 경영층까지 협업이 용이한 툴 선정
-
지원 깊이: SQL에서 제공하는 명령어에 대한 지원 커버리지
-
시각화: 데이터의 흐름, 테이블 가시화 등 그래픽 요소 지원 여부
-
이기종 데이터베이스 지원: 하나의 툴로 다양한 복수의 데이터베이스 지원
-
비용: 라이선스 비용, 운용 인력 급여 등 유지하는 데 들어가는 총비용 고려
-
편의 기능: 관리자, 사용자를 구분한 접근 권한 설정 등 편의 기능 고려
-
-
2. 데이터베이스 관리 툴의 주요 기능
-
논리적/물리적 모델 구축
-
스크립트를 사용한 자동 생성 및 수정
-
SQL 관련 최적화 수행(악성 SQL 추출, 튜닝, Index 생성 전후 성능 비교 등)
-
벤치마크 시나리오 생성
-
가상 유저를 가정한 다양한 테스트 환경 단순화
-
부하 테스트 수행
-
데이터베이스 상태 모니터링 및 문제 해결 방안 제시
-
[3] 오픈소스 기반 DBMS 및 DBMS 관리 툴
-
정보통신산업진흥원에서는 공개SW포털이라는 웹 사이트를 운영하여 다양한 오픈소스 정보를 정기적으로 업데이트 하고 있다.


[수행]
[1] 데이터베이스 기본 연산을 수행한다.
-
1. SQL 표준을 준수하여 저장되어 있는 데이터에 대하여 Insert(삽입), Read(읽기), Update (갱신), Delete(삭제) 명령어를 작성한다.

-
(1) 데이터 삽입 명령어를 작성한다.
-
테이블에서 데이터를 읽기 위해서는 “Insert” 명령어를 사용한다.
-

-
(2) 데이터 읽기 명령어를 작성한다.
-
테이블에서 데이터를 읽기 위해서는 “Select” 명령어를 사용한다. Select 다음 * 표기를 사용하면 모든 데이터를 읽어 오고 칼럼명을 지정하면 특정 칼럼만을 읽어 온다.
-

-
(3) 데이터 갱신 명령어를 작성한다.
-
테이블에서 데이터를 갱신하기 위해서는 “Update” 명령어를 사용한다. where 조건절을 사용하여 업데이트할 데이터를 특정해야 한다.
-

다음 두 문장을 사용했을 때 update에 대한 결과에 어떤 차이점이 있는지 기록한다.
- UPDATE Address SET address1 = '제주도', address2 = '서귀포시 색달동', address3 = '청아아파트 111동 11호' WHERE SEQ_ID = 1;
- UPDATE Address SET address1 = '제주도', address2 = '서귀포시 색달동', address3 = '청아아파트 111동 11호' WHERE address1 = `경기도';
(4) 데이터 삭제 명령어를 작성한다.
테이블에서 데이터를 삭제하기 위해서는 “Delete” 명령어를 사용한다. where 조건절을 사용하여 삭제할 데이터를 특정해야 한다.

-
(5) SQL 기타 명령어 사용
-
ALTER DATABASE 명령어를 사용하여 데이터베이스를 수정한다.
-
ALTER TABLE 명령어를 사용하여 테이블 구조를 수정한다.
-
DROP TABLE 명령어를 사용하여 테이블을 전체 삭제한다.
-
CREATE INDEX 명령어를 사용하여 테이블 내 데이터의 검색 속도를 향상시킬 수 있는 인덱스를 생성한다.
-
DROP INDEX 명령어를 사용하여 인덱스를 삭제한다.
-
JOINT 기능을 사용하여 복수의 테이블로부터 데이터를 조합하여 가져온다.
-
그 외 UNION, GROUP BY 등의 다양한 명령어를 활용한다.
-
[2] 데이터베이스 관리 툴을 사용한다
-
데이터베이스 관리 툴을 사용하면 데이터베이스의 생성, 관리, SQL 문장의 작성, 모니터링 등 다양한 기능을 손쉽게 활용할 수 있다. 오픈소스 기반으로 무료로 사용할 수 있는 툴 과 상용화로 비용을 지불해야 사용할 수 있는 툴이 있으며, 지속적으로 새로운 기능을 가 진 프로그램들이 나오고 있으므로 자신에게 적합한 툴을 선정하도록 한다. 공개 Demo 버 전을 활용하면 유료 소프트웨어라도 일정 기간 사용 체험을 해 볼 수 있다. 데이터베이스 관리 툴은 다음과 같은 기능 등을 제공한다.
-
데이터베이스 생성, 삭제
-
SQL 명령어 작성 및 실행
-
상태 모니터링: 받은 데이터양, 보낸 데이터양, 동시 연결 수, 실패한 시도 등
-
사용자 계정 관리
-
데이터베이스 내보내기/가져오기
-
환경 설정
-
[연습문제]
-
데이타베이스의 개용에 대한 설명이 잘못된 것은?
-
데이터베이스는 다수의 인원, 시스템 또는 프로그램이 사용할 목적으로 통합하여 관리되는 데이터의 집합이다.
-
IT 시스템의 발달로 인해 급증하는 데이터에 대한 효과적인 관리 가 중요해졌다. 자료의 중복성 제거, 무결성 확보, 일관성 유지, 유용성 보장은 데이터베이스 관리의 핵심이다.
-
DBMS(Database Management System)는 위와 같은 데이터 관리의 복잡성을 해결하는 동시 에 데이터 추가, 변경, 검색, 삭제 및 백업, 복구, 보안 등의 기능을 지원하는 소프트웨어 이다.
-
저장되는 정보는 텍스트, 이미지, 음악 파일, 지도 데이터 등 매우 다양하며, SNS의 발달과 빅데이터의 폭넓은 활용으로 인해 데이터의 종류와 양은 급격히 감소 중이다.
-
-
관계형 데이터베이스 관리시스템이 아닌 것은?
-
오라클
-
My-Sql
-
TOTAL
-
SQL Server
-
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'자기계발 > 자격증' 카테고리의 다른 글
| [자격증] 정보처리기사 실기 : 30강 응용 SW 기초 기술 활용 (기본 개발환경 구축) (0) | 2020.05.13 |
|---|---|
| [자격증] 정보처리기사 실기 : 29강 응용 SW 기초 기술 활용 (네트워크 기초 활용하기) (0) | 2020.05.13 |
| [자격증] 정보처리기사 실기 : 27강 응용 SW 기초 기술 활용 (운영체제 기초 활용하기) (0) | 2020.05.12 |
| [자격증] 정보처리기사 실기 : 26강 프로그래밍 언어 활용 (언어특성 활용하기, 라이브러리 활용하기) (0) | 2020.05.12 |
| [자격증] 정보처리기사 실기 : 25강 프로그래밍 언어 활용 (기본문법 활용하기) (0) | 2020.05.12 |