

정보
- 업무명 : 데이터분석 전문가 (ADP) 필기 : 제4과목 데이터 분석
- 작성자 : 이상호
- 작성일 : 2022.10.27
- 설 명 :
- 수정이력 :

내용
[R 기초와 데이터 마트]
1. 데이터 분석 도구의 현황
- 다른 프로그램에 비해 R의 사용이 증가하고 있다.
- 1) R의 탄생
- R은 오픈소스 프로그램으로 통계, 데이터마이닝과 그래프를 위한 언어
- 다양한 최신 통계분석과 마이닝 기능을 제공
- 세계적으로 사용자들이 다양한 예제를 공유
- 다양한 기능을 지원하는 5,000개에 이르는 패키지가 수시로 업데이트
- 2) 분석도구의 비교
| SAS | SPSS | R | |
| 프로그램 비용 | 유료, 고가 | 유료, 고가 | 오픈소스, 무료 |
| 설치용량 | 대용량 | 대용량 | 모듈화로 간단 |
| 다양한 모듈 지원 및 비용 | 별도구매 | 별도구매 | 오픈소스 |
| 최신 알고리즘 및 기술반영 | 느림 | 다소 느림 | 매우 빠름 |
| 학습자료 입수의 편의성 | 유료 도서 위주 | 유료 도서 위주 | 공개 논문 및 자료 많음 |
| 질의를 위한 공개 커뮤니티 | - | - | 매우 활발 |
| 유지보수 | 쉽다 | 쉽다 | 어렵다 |
- 3) R의 특징
- 오픈소스 프로그램
- 사용자 커뮤니티에 도움 요청이 쉽다
- 약 5000개의 패키지가 수시로 업데이트 된다
- 그래픽 및 성능
- 프로그래밍이나 그래픽 측면 등 대부분의 주요 특징들에서 상용 프로그램과 대등하거나 월등하다
- 프로그래밍이나 그래픽 측면 등 대부분의 주요 특징들에서 상용 프로그램과 대등하거나 월등하다
- 시스템 데이터 저장 방식
- 각 세션 사이마다 시스템에 데이터셋을 저장하므로 매번 데이터 로딩할 필요없고 명령어 히스토리 저장 가능하다
- 모든 운영체제
- 윈도우, 맥, 리눅스 운영체제에서 사용 가능하다
- 표준 플랫폼
- S 통계 언어를 기반으로 구현된다
- R/S 플랫폼은 통계전문가들의 사실상의 표준 플랫폼이다
- 객체지향언어 이며 함수형 언어
- 통계 기능 뿐만 아니라 일반 프로그래밍 언어처럼 자동화하거나 새로운 함수를 생성하여 사용 가능하다
- 객체지향 언어의 특징
- SAS, SPSS 회귀분석 시 화면에 결과가 산더미로 나온다.
- 반면에 R은 추정계수, 각각의 표준오차, 잔차 등 결과값인 객체를 반환한다.
- 필요한 부분을 프로그래밍으로 골라 추출하여 활용 가능하다
- 함수형 언어 특징
- 더욱 깔끔하고 단축된 코드
- 매우 빠른 코드 수행속도
- 단순한 코드로 디버깅 노력 감소
- 병렬 프로그래밍으로의 전환이 더욱 용이
- 오픈소스 프로그램
- 4) R 스튜디오
- 오픈소스이고 다양한 운영체계를 지원한다.
- R 스튜디오는 메모리에 변수가 어떻게 되어있는지와 타입이 무엇인지를 볼 수 있고, 스트립트 관리와 도움말이 편리하다.
- 코딩을 해야하는 부담이 있으나 스크립트용 프로그래밍으로 어렵지 않고 쉽게 자동화 가능하다

[R 기초]
- R의 데이터 구조
- 벡터 (Vector)
- 행렬 (Matrix)
- 배열 (Array)
- 데이터프레임 (Data Frame)
- 리스트 (List)
- 외부 데이터 불러오기
- read.csv() 함수로 csv 불러오기
- 라벨 구분이 , (콤마)인 경우에 사용하기 간편함
- 라벨 구분이 tab으로 구분된 파일이라면 sep="\t" 옵션 사용
- read.table
- 일반 텍스트 형태의 파일을 읽어서 데이터 프레임에 담기
- 데이터를 R로 불러들이고 데이터 프레임에 담기
- read.csv() 함수로 csv 불러오기
- R 기초 함수
- 수열 생성하기
- 대표적인 생성 방식으로는 숫자사이에 : 를 사용하는 방법
- rep 함수는 특정값을 반복
- seq 함수는 시작숫자와 끝 숫자를 정해주면 숫자를 생성
- 평균, 분산, 표준편차
- 표본 평균 : mean()
- 표본 분산 : var()
- 표본 표준 편차 : sd()
- 기초변환 및 상관계수, 공분산
- sum() : 합계
- median() : 중앙값
- log() : 자연로그
- cov() : 공분산
- cor() : 상관 계수
- summary() : 주어진 벡터에 대한 각 사분위수 최소값, 최대값, 중앙값, 평균
- 데이터 핸들링
- 반복 구문과 조건문
- for
- while
- if~else
- 반복 구문과 조건문
- 사용자 정의 함수
- 기타 유용한 기능
- ① 문자열 통합
- ② 특정 문자열 추출
- ③ 데이터 구조 변환
- ④ 문자열 특성 변환
- 그래픽 기능
- 산점도 : plot(x,y)
- 산점도 행렬 : pairs(x,…)
- 히스토그램 : hist(x)
- 상자그림 : boxplot(x)
[데이터 마트]
- R reshape의 활용
- reshape 패키지에는 melt()와 cast() 라는 2개의 핵심 함수 사용
install.packages("reshape2")
library(reshape2)
head(airquality)
melt(airquality, id=c("Month", "Day"), na.rm=TRUE)
cast()
- plyr
- apply 함수에 기반해 데이터와 변수를 동시에 배열로 치환하여 처리하는 패키지
- split-apply-combine : 데이터를 분리-처리-다시결합하는 등 필수적인 데이터 처리 기능 제공
- 데이터 처리 함수 : (입력데이터형식) (출력데이터형식) plyr
- 데이터 테이블
- R의 기본 데이터구조인 데이터 프레임을 대신하여 사용할 수 있다.
- 기존 data.frame 방식보다 월등히 빠른 속도(최소 20배)***
- 특정 컬럼을 key값으로 색인을 지정한 후 데이터를 처리하기 때문에 빠른 그루핑과 정렬, 짧은 문장 지원 측면에서 데이터프레임보다 유용하다.
- 결측값 처리와 이상값 검색
- 결측값의 표현 : NA, . , 999999999, ' ', Unknown, Not Answer 등으로 결측값 표현
- NaN은 Not a Number 로 결측값이 아니라 숫자형데이턴데 숫자 외의 문자가 오는 경우...
- 결측값에 너무 시간 낭비 하지 말기!
- 결측값 자체가 의미있는 경우도 있음
- 쇼핑몰 가입자 중 거래가 아예 없는 경우
- 인구통계학적 데이터에서, 아주 부자이거나 아주 가난한 군집의 데이터가 없는 경우
- 결측값 처리가 전체 작업속도에 많은 영향을 준다.
- 이상값 검색 (꼭 제거하는것은 아님)
- 분석의 목적/종류에 따라 적절히 변환/제거 등
- 결측값이 있는 자료의 평균 구하기
# 평균 : NA
mean(c(1,2,3,NA))
# NA를 제거한 후에 3개로 평균을 계산
mean(c(1,2,3,NA), na.rm=TRUE)
[결측값 처리와 이상값 검색]
- 결측값 처리 방법
- 단순 대치법
- 1) completes analysis : 결측값이 존재하는 레코드를 삭제
- 2) 평균대치법 : 관측/실험을 통해 얻어진 데이터의 평균으로 대체
- 조건부 평균대치법 : 결측값있는 변수를 종속변수로하는 회귀분석 활용
- 비조건부 평균대치법 : 관측데이터의 단순 평균 사용
- 조건부 평균대치법 : 결측값있는 변수를 종속변수로하는 회귀분석 활용
- 3) 단순확률대치법 : 평균대치법에서 추정량 표준오차의 과소추정문제를 보완
- Hot-deck 방법, Nearest-neighbour 방법 등이 있다.
- 다중 대치법
- 단순대치법을 m번 반복해서 m개의 완전한 자료를 가상적으로 만들어내는 방법
- 1단계 : 대치 > 2단계 : 분석 > 3단계 : 결합
- 이상값 (Outlier) 찾기와 처리
- 이상값 (Outlier)
- 실수로 잘못 입력한 경우
- 의도하지 않게 입력되었으나 분석 목적에 부합하지 않아 제거해야 하는 경우
- 의도하지 않은 현상이지만, 분석에 포함해야하는 경우
- 의도된 이상값인 경우 (fraud, 불량)
- 이상값의 인식 방법
- 1) ESD (Extreme Studentized Deviation) : 평균에서 3표준편차 떨어진 값 (3시그마)
- 2) 기하평균 - 2.5 x 표준편차 < data < 기하평균 + 2.5 x 표준편차 인 경우
- 3) 사분위수의 Q1, Q3로부터 2.5*IQR 이상 떨어져있는 데이터
- 극단값 절단 (trimming) 방법
- 1) 기하평균을 이용한 제거 : geo_mean
- 2) 하단, 상단 백분율 이용한 제거 : 상,하위 5% 에 해당되는 데이터 제거
- 극단값 조정 (winsorizing) 방법
- 상한값과 하한값을 벗어나는 값들은 상한값, 하한값으로 바꿈
[통계분석]
1. 통계학 개요
- 자료의 수집, 정리, 해석 이 세가지가 통계학의 핵심
- 1) 통계: 특정집단을 대상으로 수행한 조사나 실험을 통해 나온 결과에 대한 요약 표현
- 총조사 (census)와 표본조사
- 2) 통계자료 획득방법:
- (1) 총 조사 (census)
- (2) 표본조사
- 모집단 : 조사하고자 하는 대상 집단 전체
- 원소 : 모집단 구성개체
- 표본 : 모집단의 일부 원소 (부분집합)
- 모수 : 모집단의 속성, 특징을 나타내는 통계값 (모평균, 모표준편차, 모상관계수)
- 모집단의 정의, 표본의 크기, 조사방법, 조사기간, 표본추출방법을 정확하게 명시
- 3) 표본추출방법: 모집단을 대표할 수 있는 표본 추출
- 확률표본추출
- 단순랜덤추출법
- 복원, 비복원 추출 : 임의의 n개 추출하는 방법 -> 각 샘플은 선택될 확률이 동일
- 계통추출법 : 모집단의 개체에 1,2,….N이라는 일련번호를 부여한 후, 첫번째 표본을 임의로 선택하고 일정 간격으로 다음 표본을 선택
- 층화추출법 : 이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할수 있도록 표본 추출
- 집락추출법 : 군집을 구분하고 군집별로 단순랜덤추출법
- 지역표본추출, 다단계표본추출
- 비확률표본추출
- 판단추출법
- 할당추출법
- 편의추출법
- 지원자 표본 추출법
- 단순랜덤추출법
- 확률표본추출
- 4) 척도 (Scale)의 종류
- 명목척도: 가장 낮은 수준의 척도로 단지 측정대상의 특성만 구분하기 위하여 숫자나 기호를 할당한 것으로 특성 간의 양적인 분석을 할 수 없고, 때문에 특성간에 대소의 비교도 할 수 없다
- 서열 척도 : 측정대상의 특성들을 구분하여 줄뿐만 아니라 이들 사이의 상대적인 크기를 나타낼 수 있고, 서로 간에 비교가 가능한 척도
- 등간척도: 명목척도와 서열척도의 특징을 모두 가지고 있으면서 크기가 어느 정도나 되는지, 특성간의 차이가 어느 정도나 되는지 파악이 가능한 척도
- 비율척도 : 가장 높은 수준의 척도로서, 가장 자세한 정보를 제공, 서로의 구분, 크기의 비교, 크기의 차이, 그리고 특성들 간의 계산까지 가능한 수준, 모두 숫자로 표현되고 그것들의 계산이 가능한 척도
2. 통계분석 (statistical analysis)
- 특정한 집단이나 불확실한 현상을 대상으로 자료를 수집해 대상 집단에 대한 정보를 구 하고 적절한 통계분석방법을 이용해 의사결정을 하는 과정 (통계적 추론)
- 대상 집단에 대한 정보 : 자료를 요약·정리한 결과, 숫자/그림으로 정리된 각종 통계
- 통계적 추론 : 수집된 자료를 이용해 대상 집단 (모집단)에 대해 의사결정을 하는 것
- 추정 (estimation), 가설검정 (hypothesis test), 예측 (forecasting)
- 기술통계(descriptive statistic) : 수집된 자료를 정리·요약하기 위해 사용되는 기초통계 자체로도 여러 용도에 쓰이나 대게 자세한 통계적 분석을 위한 전단계 역할
3. 확률 및 확률분포
- 확률 : 특정사건이 일어날 가능성의 척도
- 표본공간(sample space,Ω) : 나타날 수 있는 모든 결과들의 집합
- 원소(element) : 나타날 수 있는 개개의 결과
- 사건(event) : 표본공간의 부분집합
- 조건부확률과 독립사건
- 확률이 0이 아닌 사건 A가 일어났을 때 사건 B가 일어날 확률을 사건 A가 일어났을 때의 사건 B의 조건부확률이라 하고 P(B|A)와 같이 나타낸다.
- 조건부확률의 계산
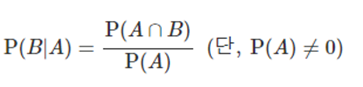
- 한 개의 주사위를 던져서 홀수의 눈이 나왔을 때, 그것이 소수일 확률을 구하여라.
- 확률변수 (random variable) : 특정값이 나타날 가능성이 확률적으로 주어지는 변수 (정의역이 표본공간, 치역이 실수값인 함수)
- 이산형 확률변수 (discrete r.v.) : 0이 아닌 확률 값을 갖는 셀 수 있는 실수값
- 연속형 확률변수 (continuous r.v.) : 특정 실수구간에서 0이 아닌 확률을 갖는 확률변수
- 결합확률분포 (joint probability distribution) : 두 확률변수의 결합확률분포
- 통계분석에서 수집된 자료에서 어떤 정보를 얻고자 할 때는 항상 수집된 자료가 특정 확률분포를 따른다고 가정
- 이산형 : 베르누이, 이항분포, 기하분포, 다항분포, 포아송분포 등
- 연속형 : 균일분포, 정규분포, 지수분포, t분포, 카이스퀘어 분포, F분포 등
4. 추정과 가설검정
- 각 확률 분포는 평균, 분산 등의 모수 (parameter)를 갖음
- 확률 표본 (random sample)
- 특정 확률분포로부터 독립적으로 반복해 표본을 추출하는 것
- 각 관찰값들은 서로 독립적이며 동일한 분포
- 모수
- 모집단의 특성을 나타내는 값(일반적으로 알려져 있지 않음)
- 표본추출에 의해 모수 추정
- 점추정 (point estimation)
- 모수가 특정한 값. 얼마나 추정이 정확한지 판단 불가
- ex) 표본평균, 표본분산
- 좋은 추정량이 되기 위한 조건
- 불편성 : 모든 가능한 표본에서 얻은 추정량의 기댓값이 모수의 값과 같아야 한다.
- 효율성 : 추정량의 분산이 가능한 작아야 한다.
- 일치성 : 표본의 크기가 아주 커지면, 측정값이 모수와 거의 같아진다.
- 충족성 : 추정량이 모수에 대하여 모든 정보를 제공한다.
- 구간추정 (interval estimation) : 미리 정해진 신뢰수준값 (99%, 95%, 90% 등) 을 기준으로 모수가 참이라고 여겨질 구간을 추정하는 방법이다.
- 가설검정 : 모집단에 대한 어떤 가설을 설정한 후 표본관찰을 통해 가설의 채택여부 결정
- 검정하고자 하는 모집단의 모수에 대한 가설 설정이 가장 기본적
- 귀무가설 (H0) : 모수에 대한 가설 중 간단하고 구체적인 표현 설정
- 대립가설 (H1) : 연구자가 입증하려는 주장을 담은 가설
- 검정통계량 (test statistic) : 검정에 사용되는 통계량
- 유의수준 (significance level) : H0이 옳은데 이를 기각하는 확률의 크기
- 기각역 (critical region) : H0이 옳다는 전제에서 구한 검정통계량의 분포에서 확률이 유의 수준인 부분
- 검정하고자 하는 모집단의 모수에 대한 가설 설정이 가장 기본적
- 오류(error)
- Type | : 귀무가설 (H0)가 맞는데 기각하는 오류
- Type || : 귀무가설 (H0)가 틀린데 채택하는 오류
- 상충관계, 일반적으로 1종오류 (α) 크기 고정시키고 2종오류(β) 최소화되게 기각역 설정
- 가설검정 : 모집단에 대한 어떤 가설을 설정한 후 표본관찰을 통해 가설의 채택여부 결정
5. 비모수 검정
- 모수적 검정방법 : 검정하고자 하는 모집단의 분포에 대한 가정 하에서 검정통계량과 그 분포를 유도해 검정 실시
- 비모수적 검정 : 자료가 추출된 모집단의 분포에 아무 제약 않고 검정 실시 **
- 정규분포를 하는 자료 : 모수적 검정
- 정규분포를 하지 않는 자료 : 비모수적 검정
[기초통계분석]
1. 기술통계 (Descriptive Statistics)
- 자료를 요약하는 기초적 통계
- 데이터 분석에 앞서 데이터의 대략적인 통계적 수치를 계산해봄으로써 데이터에 대한 대략적 이해와 분석에 대한 통찰력을 얻기에 유리
- 데이터 마이닝에 앞서 데이터의 기술통계를 확인해보는 것이 좋음
- head : 데이터를 기본 6줄 보여줘 데이터가 제대로 import됐는지 살펴볼 수 있는 함수
- summary : 데이터의 컬럼에 대한 전반적인 기초 통계량 보여줌
- 데이터의 특정 컬럼 선택 : 데이터명$column명
2. 회귀분석
- 종속 변수 (반응변수, y) : 다른 변수의 영향을 받는 변수
- 독립 변수 (설명변수, x) : 영향을 주는 변수
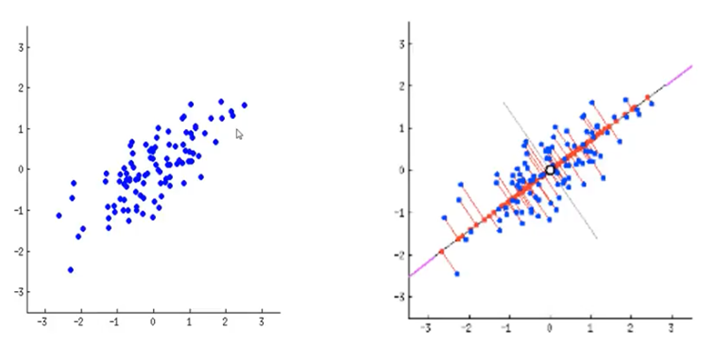
- 산점도 (scatter plot) : 좌표평면 위에 점들로 표현
- 단순회귀분석과 중회귀분석 (다중회귀분석)의 개념
- 회귀분석 : 1개 또는 그 이상의 독립변수들이 종속변수에 미치는 영향을 추정 (예측)하는 통계기법
- 단순 (선형)회귀 : 1개의 종속변수와 1개의 독립변수의 관계를 분석
- 다중회귀 (중회귀)분석 : 1개의 종속 변수와 2개 이상의 독립변수간의 관계를 분석
- 상관분석 (Correlation Analysis)
- 데이터 안의 두 변수 간의 관계를 알아보기 위함
- 두 변수의 상관관계를 알기위해 상관계 (correlation coefficient) 이용
- 피어슨 상관계수 : 등간척도 이상으로 측정되는 두 변수의 상관관계 측정
- 스피어만 상관계수 : 서열척도인 두 변수의 상관관계 측정
- 1(-1)에 가까울수록 강한 양(음)의상관관계를 나타내고 상관관계 없으면 r=0
- 회귀분석의 체크 포인트
- 모형이 통계적으로 유의미한가? F통계량 (p값) 확인
- 회귀계수들이 유의미한가? 계수의 t값, p값 또는 신뢰구간 확인
- 모형이 얼마나 설명력을 갖나? 결정계수 (R-square) 확인
- 모형이 데이터를 잘 적합하고 있나? 잔차 그래프 그리고 회귀진단
- 데이터가 전제하는 가정을 만족시키나?
- 가정 : 선형성, 독립성 (잔차와 독립변인 값 독립), 등분산성 (오차 분산 일정), 비상관성 (잔차끼리 상관 X), 정상성 (잔차가 정규분포)
- 이상 관측치
- 이상치 (outlier) : 회귀모형으로 잘 예측되지 않는 관측치 (즉 아주 큰 양수/음수의 residual)
- 큰지레점 (high leverage point) : 비정상적인 예측변수의 값에 의한 관측치. 즉 예측변수의 이상치로 볼 수 있다.
종속변수의 값은 관측치의 영향력을 계산하는 데 사용하지 않는다. - 영향관측치 (influential observation) : 통계 모형 계수 결정에 불균형한 영향을 미치는 관측치로 Cook’s distance라는 통계치로 확인할 수 있다.
- 다중공선성 (Multicolinearity) : 독립 변수의 일부가 다른 독립 변수의 조합으로 표현될 수 있는 경우이다.
- 독립 변수들이 서로 독립이 아니라 상호 상관관계가 강한 경우에 발생한다.
- 다중 공선성을 없애는 가장 기본적인 방법은 다른 독립변수에 의존하는 변수를 없애는 것이다.
- 가장 의존적인 독립변수를 선택하는 방법으로는 VIF (Variance Inflation Factor)를 사용할 수 있다.
- 최적회귀방정식의 선택: 설명변수의 선택
- 회귀모형 설정 변수 선택 원칙
- y에 영향 미칠 수 있는 모든 설명변수 x들을 y값을 예측하는데 참여시킴
- 설명변수 x가 많아지면 관리하는데 노력이 많이 요구되므로 가능한 범위 내에서 적은 수 의 설명변수를 포함시켜야 한다.
- 단계적방법 (stepwise selection)
- 모든 변수가 포함된 모델에서 출발하여 기준 통계치에 가장 도움이 되지 않는 변수를 삭제하거나, 모델에서 빠져 있는 변수 중에서 기준 통계치를 가장 개선시키는 변수를 추가한다.
- 그리고 이러한 변수의 추가 또는 삭제를 반복한다.
- 반대로 절편만 포함된 모델에서 출발해 변수의 추가/삭제를 반복할 수도 있다.
step(lm(종속변수~설명변수, 데이터세트), scope=list(lower=~, upper=~설명변수), direction="변수 선택 방법")
[다변량 분석]
- 주성분 분석 (PCA)
- 고차원의 데이터를 저차원의 데이터로 변환시키는 기법
- 고유 벡터 기반의 다변량 분석들 중 가장 쉬움
- 데이터의 분포를 가장 크게 설명하는 축을 중심으로 설명함
[시계열 예측]
1. 정상성 (stationarity)
- 시계열 자료 : 시간의 흐름에 따라 관찰된 값들
- 비정상성 시계열
- 시계열 분석하는데 다루기 어려운 시계열 자료
- 정상시계열로 만들어 분석
- 정상성 시계열
- 약한의미의 정상성 : 모든 시점에 평균일
- 시점과 분산 독립
- 공분산은 시차에만 의존
- 비정상 -> 정상 : 변환 (transformation), 차분 (difference)
- 변환 : 분산이 일정하지 않은 비정상 시계열
- 차분 (t1-t0) : 평균이 일정하지 않은 비정상 시계열
2. 시계열 모형
- 자기회귀모형 (AR모형)
- p시점 전의 자료가 현재 자료에 영향을 주는 자귀회귀모형을 AR(p) 모형이라 함
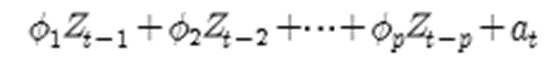
- 자기회귀모형 판단 조건
- 자기상관함수 (ACF) 빠르게 감소하고 부분자기상관함수(PACF)는 어느 시점에 절단점 갖음
- 이동평균모형 (MA모형)
- 유한한 개수의 백색잡음의 결합
- 항상 정상성 만족
- ACF에서 절단점 갖고 PACF가 빠르게 감소
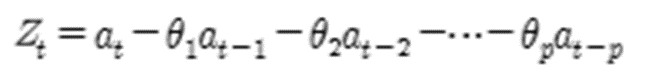
- 자기회귀누적이동평균모형 (ARIMA모형)
- 가장 일반적인 모형으로 비정상시계열 모형으로 차분이나 변환을 통해 AR/MA/ARMA로 정상화 가능
- p는 AR, q는 MA와 관련있는 차수로 ARIMA에서 ARMA로 정상화할 때 차분한 횟수 의미
- 분해 시계열
- 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
- 1) 추세요인 (trend factor) : 자료가 어떤 특정한 형태를 취할 때
- 2) 계절요인 (seasonal factor) : 고정된 주기에 따라 자료가 변화
- 3) 순환요인 (cyclical factor) : 알려지지 않은 주기를 갖고 자료가 변화
- 4) 불규칙요인 (irregular factor) : 회귀분석에서 오차에 해당하는 요인
- 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
[정형 데이터 마이닝]
- 데이터 마이닝의 개요
- 데이터 마이닝 : 대용량 데이터에서 의미있는 데이터 패턴을 파악하거나 예측을 위해 데이터를 자동으로 분석해 의사결정에 활용하는 방법
- 통계분석과 비교해 데이터마이닝의 큰 차이
- 가설이나 가정에 따른 분석이나 검증, 통계학 전문가가 사용하는 도구도 아님
- 다양한 수리 알고리즘을 이용해 DB의 데이터로부터 의미있는 정보를 찾아내는 방법
- 정보 찾는 방법론에 따라
- 인공지능, 의사결정나무, K-평균군집화, 연관분석, 회귀분석, 로지스틱분석, 최근접이웃 등
- 분석 대상이나 활용목적, 표현 방법에 따라
- 시각화 분석, 분류 (classification), 군집화 (clustering), 예측 (forecasting)
- 사용하는 분야 매우 다양
- 데이터마이닝 도구가 매우 다양하고 체계화돼 도입환경에 적합한 제품을 선택/활용가능
- 데이터 마이닝을 통한 분석 결과의 품질은 분석가의 경험과 역량에 따라 차이
- 분석대상의 복잡성이나 중요도가 높으면 풍부한 경험을 가진 전문가에게 의뢰할 필요
- 통계학 전문가와 대기업 위주시장, 쓰기 힘들고 단순 반복 작업이 많아 실무에서 적극 이용되기 어려움, 데이터 준비 위한 추출/가공 부담, 경영진과 어려운 소통, 데이터 핸들링에만 사용, 신뢰 부족
1. 데이터 마이닝 추진 단계
- 데이터 마이닝은 일반적으로 목적 정의, 데이터 준비, 데이터 가공, 데이터 마이닝 기법 적용, 검증 단계로 추진
- 1단계 : 목적 설정
- 도입 목적을 분명히 : 데이터마이닝을 통해 무엇을 왜 하는지 명확한 목적 설정
- 목적 정의 단계부터 시작 : 목적은 이해 관계자 모두가 동의하고 이해 가능
- 가능하면 1단계부터 전문가가 참여해 목적에 따라 사용할 데이터 마이닝 모델과 필요 데이터를 정의하는 것이 바람직
- 도입 목적을 분명히 : 데이터마이닝을 통해 무엇을 왜 하는지 명확한 목적 설정
- 2단계 : 데이터 준비
- 데이터 정제를 통해 데이터의 품질을 보장하고 필요하다면 보강해 데이터의 양을 충분히 확보해 데이터 마이닝 기법을 적용하는데 문제없도록 해야 함
- 고객정보, 거래정보, 상품 마스터 정보 등 필요. 웹로그 데이터, SNS데이터도 활용 가능
- 대부분 용량이 크므로 IT부서와 사전 협의해 데이터 접근 부하가 심한 일을 해도 문제 없도록 일정 조율하고 도움 요청
- 필요하면 데이터를 다른 서버에 저장 운영
- 데이터 정제를 통해 데이터의 품질을 보장하고 필요하다면 보강해 데이터의 양을 충분히 확보해 데이터 마이닝 기법을 적용하는데 문제없도록 해야 함
- 3단계 : 가공
- 모델링 목적에 따라 목적변수를 정의하고 필요한 데이터를 데이터마이닝 SW에 적용할 수 있 도록 적합한 형식으로 가공
- 모델 개발단계에서 데이터 읽기, 데이터 마이닝에 부하 걸림 -> 모델링 일정계획을 팀원 간 잘 조정
- 모델링 목적에 따라 목적변수를 정의하고 필요한 데이터를 데이터마이닝 SW에 적용할 수 있 도록 적합한 형식으로 가공
- 4단계 : 기법 적용
- 앞 단계를 거쳐 준비한 데이터와 데이터 마이닝 SW를 활용해 목적하는 정보 추출
- 적용할 데이터 마이닝 기법은 1단계에서 이미 결정됐어야 바람직함
- 데이터 마이닝 모델을 목적에 맞게 선택하고 SW사용하는데 필요한 값 지정
- 어떤 기법을 활용하고 어떤 값을 입력하느냐 등은 데이터 분석가의 전문성에 따라 다름
- 데이터 마이닝 적용 목적, 보유 데이터, 산출되는 정보 등에 따라 적절한 SW와 기법 선정
- 앞 단계를 거쳐 준비한 데이터와 데이터 마이닝 SW를 활용해 목적하는 정보 추출
- 5단계 : 검증
- 마이닝으로 추출한 정보를 검증하는 단계
- 테스트 마케팅이나 과거 데이터 활용 가능
- 검증됐으면 자동화 방안을 IT부서와 협의해 상시 데이터 마이닝 결과를 업무에 적용할 수 있게 해야 하며 보고서를 작성해 경영진에게 기대효과를 알릴 수 있어야 함
- 마이닝으로 추출한 정보를 검증하는 단계
2. 데이터 마이닝을 위한 데이터 분할
- 결과 신빙성 검증을 위해 일반적으로 데이터를 구축용 (training), 검증용 (validation), 시험용 (test)으로 분리
- 구축용 : 초기의 데이터 마이닝 모델 만드는데 사용. 추정용, 훈련용 (50%)
- 검증용 : 구축된 모델의 과잉 또는 과소맞춤 등에 미세조정 절차 위해 사용 (30%)
- 시험용 : 데이터 마이닝 추진 5단계에서 검증용으로 사용 (20%)
- 데이터 양이 충분치 않거나 사용 SW입력 변수에 대한 설명이 충분할 경우 구축용과 시험 용으로만 분해 사용하기도 함
- 필요에 따라 구축용과 시험용을 번갈아가며 사용 : 교차검증 (cross-validation)을 통해 모형평가
- 최근에는 구축용과 시험용으로만 분리해 사용하는 추세
- 최근에는 구축용과 시험용으로만 분리해 사용하는 추세
3. 데이터 마이닝 모형 평가
- 데이터 마이닝 프로젝트의 목적과 내용에 따라 적합 모형 다름
- 몇가지 모형 대안 놓고 어느 것이 적합한지 판단하는 가장 보편적 기준 : 손익비교
- 모델링은 변경 주기가 있으며 근본적으로 정확도의 편차가 급증하는 시점에 실행
- classification : 최소1년 2번
- 연관성 규칙: 비즈니스특성에 따라 1주/1개월
- forecasting : 일/주/월 단위 등 모델링 기준에 따라 다름
- 성공적 데이터마이닝 핵심 : 전반적인 비즈니스 프로세스에 대한 이해
- 각 프로세스에서 어떤 형태로 데이터가 발생돼 변형·축적되는지 이해하고 필요한 데이터 선별가능 해야 함
- 데이터에 대한 전반적 파악, 팩트와 특이사항 파악해 브레인 스토밍, 마트 잘 만들기 (자동화), 모델링 (처음부터 전체 데이터 접근 X,샘플링 최대한 활용)
[분류 분석 (Classification)]
- 분류분석 : 데이터의 실체가 어떤 그룹에 속하는지 예측하는데 사용하는 데이터마이닝 기법
- 특정 등급으로 나누는 점에서 군집분석과 유사하나 각 계급이 어떻게 정의되는지 미리 알아야 함
- 분류 (classification) : 객체를 정해놓은 범주로 분류하는데 목적
- CRM에서는 고객행동예측, 속성파악에 응용. 다양한 분야에서 활용 가능
- 분류 모델 개발할 때는 train data/test data 구분지어 모델링
- 전체 데이터를 7:3, 8:2 등으로 나눠 train 해서 최적모델 확정짓고 test로 검증
- train과 test간 편차 없어야 하며 성능은 test가 다소 낮게 나오는 경향
- 분류를 위해 사용되는 데이터마이닝 기법
- 로지스틱 회귀, 최근접이웃 (nearest neighborhood), 의사결정나무 (decision tree), 베이지안 정리를 이용한 분류, 인공신경망(artificial neural network), 지지도벡터기계(support vector machine), caret(classification and regression tree) 등
- 상황판단, 속하는 분류 집단 특성, 예측 등에도 사용
- 로지스틱 회귀분석(Logistic regression)
- 로지스틱 회귀분석은 분석하고자 하는 대상들이 두 집단 혹은 그 이상의 집단(다변수 데이터)으로 나누어진 경우에 개별 관측치들이 어느 집단으로 분류될 수 있는가를 분석하고 이를 예측하는 모형을 개발하는데 사용되는 대표적인 통계 알고리즘 이다.
- 분석 목적이나 절차에 있어서는 일반 회귀분석과 유사하나 종속 변수가 명목척도로 측정된 범주형 질적 변수인 경우에 사용한다는 점에서 일반 회귀분석과 차이가 있다.
- 의사결정 나무(Decision Tree)
- 분류함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법
- 나무의 구조에 기반한 예측모델을 갖는 데이터를 분류하기 위한 질문, 잎은 분류 결과에 따라 분리된 데이터 의미
- 연속적으로 발생하는 의사결정문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한 눈에 볼 수 있게 하며 계산결과가 의사결정나무에 직접 나타나 분석 간편
- 의사결정 나무(Decision Tree) 구성요소
- 뿌리마디(Root Node) : 나무구조가 시작되는 마디로써 전체 자료로 이루어져 있다.
- 자식마디(Child Node) : 하나의 마디로부터 분리되어진 2개이상의 마디들을 의미
- 부모마디(Parent Node) : 자식마디의 상위마디를 의미
- 끝마디(Terminal Node) 또는 잎(Leaf) : 각 나무줄기의 끝에 위치하고 있는 마디를 의미
- 중간마디(Internal Node) : 나무구조의 중간에 있는 끝마디가 아닌 마디들을 의미
- 가지(Branch) : 하나의 마디로부터 끝마디까지 연결된 일련의 마디들을 의미하며 이 때 가지를 이루고 있는 마디의 개수를 깊이(Depth)라 한다.
- 분류함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법
- 인공신경망이란?
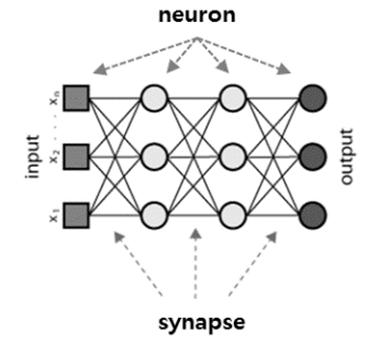
- 생물학의 뇌는 신경세포(neuron)와 신경세포를 연결하는 시냅스(synapse)를 통해서 신호를 주고 받음으로써 정보를 저장하고 학습한다.
- 인공신경망은 뇌의 학습방법을 수학적으로 모델링한 기계학습 알고리즘으로써, 시냅스의 결합으로 네트워크를 형성한 신경세포가 학습을 통해 시냅스의 결합 세기를 변화시켜, 문제를 해결하는 모델 전반을 가리킨다.
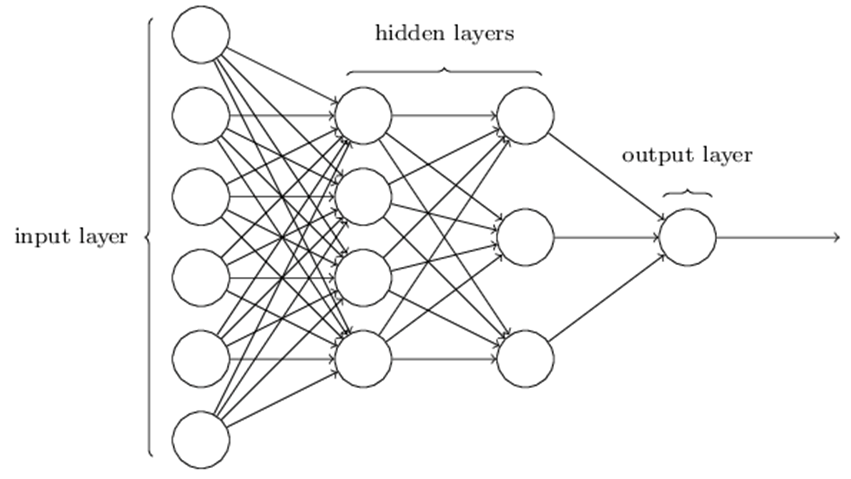
- 인공신경망 구조
- 인공신경망은 입력층(input layer), 히든층(hidden layer), 출력층(output layer)으로 구성되어 있다. 입력층에는 각각의 입력변수가 1:1로 매칭되는 뉴런(neuron)이 존재한다.
- 히든층에는 입력층의 뉴런과 가중치(weight)의 결합으로 생성되는 뉴런이 존재하며,
- 히든층에서의 층의 개수에 따라 모형의 복잡도가 결정되고 히든층의 개수가 2개 이상이 되는 경우 deep neural network 또는 deep learning이라고 칭한다.
- 출력층에는 히든층에서의 뉴런과 가중치가 결합하여 생성되는 뉴런이 존재하며, 예측하고자 하는 종속변수의 형태에 (numeric, binary or multinomial) 따라 출력층의 개수가 결정된다.
- 히든층과 출력층에 존재하는 뉴런은 이전 층에서의 입력값과 가중치를 합(summation)을 계산하는 기능과 뉴런의 가중합을 입력값으로 신호를 출력하는 활성화 함수(activation function)기능을 수행한다.
- 모형 평가
- 분류분석 모형의 평가는 예측 및 분류를 위해 구축된 모형이 임의의 모형보다 우수한 분류 성과를 보이는지와 고려된 서로 다른 모형들 중 어느 것이 우수한 예측 분류 성과를 보유하고 있는지 등을 비교 분석하는 과정
- 가장 적합한 모형을 선택하기 위해서는 성과 평가의 기준이 필요
- 모형 평가의 기준
- 일반화의 가능성
- 효율성
- 예측과 분류의 정확성
1. 홀드 아웃 (hold-out)
- 원본 데이터를 랜덤하게 두분류로 분리하여 교차 검증하는 방법
- 모형의 학습 및 구축을 위한 훈련용 자료로 하나는 성과 평가를 위한 검증자료로 사용
- 전체 데이터 중 70%는 훈련용으로 나머지는 검증용으로 사용
- 검증용 자료의 결과는 성과 측정만을 위하여 사용
2. 교차검증 (Cross Validation)
- 주어진 데이터를 가지고 반복적으로 성과를 측정하여 그 결과를 평균한 것으로 분류 분석 모형을 평가하는 방법
- 대표적인 교차검증 k-fold
3. 붓스트랩
- 평가를 반복한다는 측면에서 교차검증과 유사하나 훈련용 자료를 반복 재선정한다는 점에서 차이가 있음
- 관측치를 한 번 이상 훈련용 자료로 복원추출법에 기반한다.
- 전체 데이터의 양이 크지 않은 경우의 모형평가에 가장 적합하다.
- 일반적인 예제로 0.632 붓스트랩을 들 수 있다.
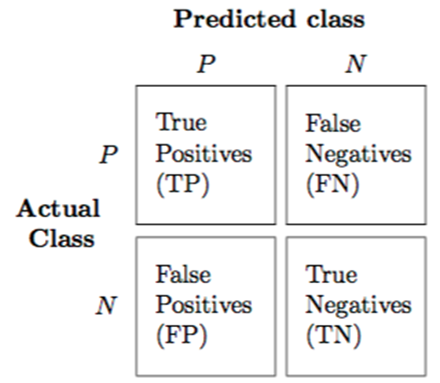
오분류표
- TP : 실제값과 예측값이 모두 True 인 빈도
- TN : 실제값과 예측값이 모두 False 인 빈도
- FP : 실제값은 False이나 True로 예측한 빈도
- FN : 실제값은 True이나 False로 예측한 빈도
- 오분류표를 이용한 평가지표
- Accuracy
- Error Rate
- Sensitivity (Recall or True positive Rate)
- Precision
- Specificity (True negative rate)
- False Positive rate
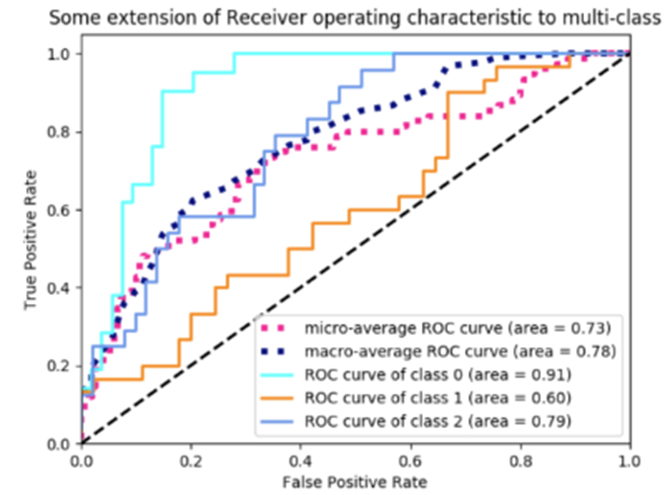
- ROC(Receiver Operating Characteristics)
- 이익도표
- 이익 : 목표 범주에 속하는 개체들이 각 등급에 얼마나 분포하고 있는지 나타내는 값
- 이익도표 : 해당 등급에 따라 계산된 이익값을 누적으로 연결한 도표
- 분류된 관측치가 각 등급별 얼마나 포함되는지 나타내는 도표
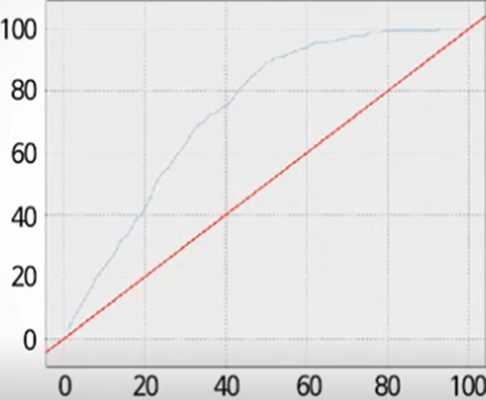
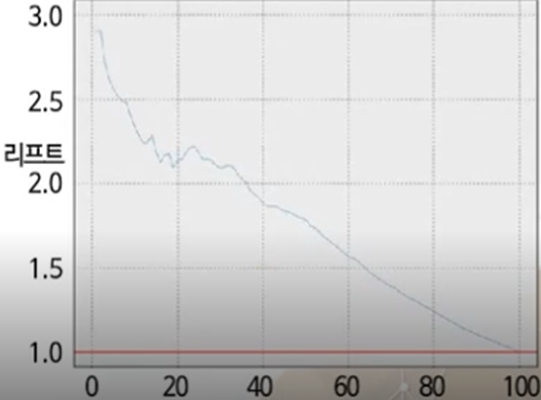
- 향상도곡선
- 랜덤모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지 등급별 파악하는 그래프
- 상위 등급은 향상도가 매우 크고 하위로 갈수록 향상도가 감소되어 예측력이 적절함 의미
- 등급에 상관없이 향상도에 차이가 없으면 예측력이 좋지 않음
[군집분석 (Clustering)]
- 각 개체에 대해 관측된 여러 개의 변수 값 들로부터 n개의 개체를 유사한 성격으로 군집화하고 형성된 군집들의 특성을 파악하여 군집들 사이의 관계를 분석하는 다변량분석기법
- 별도의 반응변수 필요없음
- 개체간의 유사성에만 기초하여 군집 형성
- 이상값탐지에도 사용, 심리학, 사회학, 경영학, 생물학 등 다양한 분야 이용
- 계층적 군집, 분리군집, 밀도-기반군집, 모형-기반군집, 격자-기반군집, 커널-기반군집, SOM
계층적 군집 (Hierarchical Clustering)
- 각 데이터가 데이터수만큼 n개의 독립군집에서 출발하여 점차 거리가 가까운 대상과 군집을 이루어 가는 것 입니다.
- 1) 최단 연결법 (Single linkage)
- 2) 최장 연결법 (Complete linkage)
3) 평균 연결법 (Average linkage) - 4) Ward 연결법 (Ward’s method)
- 수학적거리: 유클리드, 맨하튼, 민코프스키 거리
- 표준화거리 (통계적거리): 마할라노비스
- R에서 계층적 군집을 수행할 때
# 병합적 방법을 사용하는 함수
hclust, cluster 패키지의 agnes(), mclust()
# 분할적 방법을 사용하는 함수
cluster 패키지의 diana(), mona()
- H-cluster에서 군집을 지정해주는 방법
- 데이터

- 유클리드제곱 거리
| A | B | C | D | E | |
| A | 0 | ||||
| B | 2 | 0 | |||
| C | 10 | 8 | 0 | ||
| D | 13 | 5 | 9 | 0 | |
| E | 20 | 10 | 10 | 1 | 0 |
비계층적 군집
- 사전에 군집의 수를 정해주어 대상들이 군집에 할당되도록 하는 것
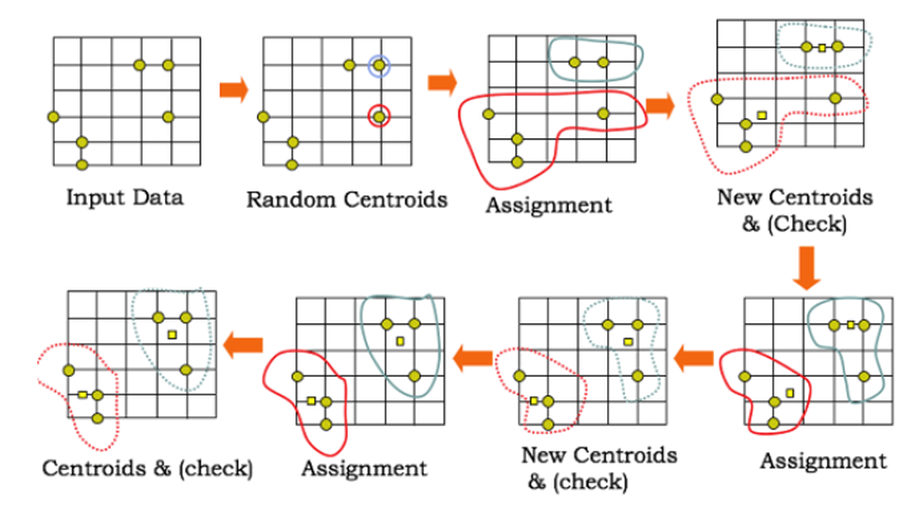
- K-Means Clustering
- 주어진 군집 수 k에 대해서 군집 내 거리제곱합의 합을 최소화 하는 것을 목적으로 한다.
- 즉, 군집 내 거리제곱합의 합이 얼마나 군집화가 잘 되었는지를 알려주는 척도
- 장점
- 알고리즘 단순, 빠름, 계층적 군집보다 많은 양의 자료를 처리
- 모든 형태의 데이터에 적용이 가능
- 단점
- 잡음이나 이상값에 영향을 받음, 계층적 군집과는 달리 사전에 군집의 수를 지정
- 군집 수 k가 원데이터 구조에 적합하지 않으면 좋은 결과를 얻을 수 없다.
혼합분포군집
- 모형기반의 군집방법으로 데이터가 k개의 모수적 모형의 가중합으로 표현되는 모집단 모형으로 나왔다는 가정하에서 모수와 함께 가중치를 자료로부터 추정하는 것이다.
- k개의 모형은 군집을 의미하고, 추정된 k개의 모형 중 어느모형으로부터 나왔을 확률이 높은지에따라 군집을 분류하게 된다.
- 혼합모형에서의 모수와 가중치의 추정, 최대 가능도 추정에는 EM알고리즘을 사용한다.
- 장점
- 확률분포를 도입하여 군집수행하는 모형기반 군집방법으로, 군집을 몇개의 모수로 표현할 수 있고, 서로 다른 크기나 모양의 군집을 찾을 수 있다.
- 단점
- EM알고리즘을 통한 모수추정에서 시간이 걸리고, 군집 크기가 작으면 추정도가 저하되어 어렵다. 또한 이상값에 민감하여 사전에 제거해줘야 한다.
- EM알고리즘을 통한 모수추정에서 시간이 걸리고, 군집 크기가 작으면 추정도가 저하되어 어렵다. 또한 이상값에 민감하여 사전에 제거해줘야 한다.
EM 알고리즘
- E단계
- 각 집단의 분포는 정규분포를 따른다고 가정하고, 각 자료가 어느 집단에서 나온지 안다면 해당 모수의 추정은 어렵지 않다.
- 그러나 각 자료가 어느 집단에서 나온지 모르니까 잠재변수의 개념을 도입하게 된다.
- 잠재변수가 z일때, 모수초기값이 주어져있다면(초기분포 값을 안다면), 각 자료가 어느집단으로부터 나올 확률이 높은지에대해 추정할 수 있다.
- M단계
- 그 다음 각 자료의 x의 조건부분포로 부터 조건부 기대값을 구한다.
- 관측변수 x와 잠재변수 z를 포함하는 로그가능도함수에 상수값인 z의 조건부기댓값을 대입하여, 로그가능도함수를 최대로 하는 모수를 찾는다
[자기조직화지도 (SOM)]
- 자기조직화지도, SOM, Self-organizing maps 는 1990, 1995, 1996년도에 코호넨이 개발한 알고리즘이다.
- 비지도 신경망으로 고차원의 데이터를 저차원의 뉴런으로 정렬하여 지도형태로 형상화하는 것인데, 입력변수의 위치관계를 그대로 보존하는 특징이 있다.
- 즉 실제공간의 입력변수가 가까이 있다면 지도상에서 가까운 위치에 존재하는 것이다.
- 따라서 패턴발견이나 이미지분석에 용이하다.
- 두 개의 인공신경망 구조로 변수와 동일하게 뉴런수가 존재하며, 자료는 학습을 통해 경쟁층에 (맵) 정렬하게 된다.
- 입력층은 입력벡터를 받는 층이고, 경쟁층은 2차원격자구조로 입력벡터의 특성에 따라 벡터가 한점으로 클러스터링 되는 층이다.
- 또한 입력층의 뉴런들은 경쟁층에 각각의 뉴련과 연결되는 완전연결의 형태를 띤다.
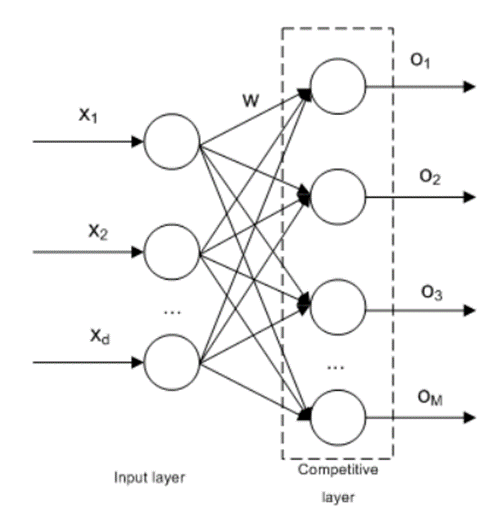
- SOM 기본 용어
- 입력층(input layer) : 입력 벡터를 입력받는 층
- 경쟁층(competitive layer) : 입력 벡터의 특성에 따라 입력 벡터가 한점으로 클러스터링 되는 층
- 가중치(weight) : 인공신경망에서 가중치는 각 입력값에 대한 입력 값의 중요도 값을 의미
- 노드(node) : 경쟁층에서 입력 벡터들이 서로의 유사성에 의해 모이는 하나의 영역
- SOM의 기능
- 구조탐색(Find structures in data)
- 데이터의 특징을 파악하여 유사 데이터를 Clustering 한다.
- 고차원의 데이터 셋을 저차원인 맵(2D 그리드에 매칭)에 표현 하는 것인데, 이를 통해 SOM은 입력 데이터를 유사한 그룹으로 분류한다.
- 차원축소(Dimension Reduction) & 시각화(Visualization)
- 차원을 축소하여 통상 2차원 그리드에 매핑하여 인간이 시각적으로 인식할 수 있게 한다.
- 차원을 축소하여 통상 2차원 그리드에 매핑하여 인간이 시각적으로 인식할 수 있게 한다.
- 구조탐색(Find structures in data)
자기조직화지도(SOM) VS 신경망 모형
- 신경망 모형은 연속적인 layer로 구성된 반면 SOM은 2차원의 그리드로 구성
- 신경망 모형은 에러 수정을 학습하는 반면에 SOM은 경쟁 학습을 실시
- SOM은 비지도학습
- R에서 SOM 구현을 위한 패키지
kohonen 패키지, som함수
[연관분석 (Association Analysis)]
1.연관 규칙 개념
- 연관규칙(Association rule)이란 항목들간의 ‘조건-결과’식으로 표현되는 유용한 패턴을 말한다.
- 이러한 패턴, 규칙을 발견해내는 것을 연관분석(Association Analysis)이라 하며, 흔히 장바구니 분석이라고도 한다.
2. 연관 규칙의 측정 지표
- 지지도(Support) : 상품 A와 B를 동시에 구매할 확률 P(A∩B)를 나타냄
- 신뢰도(Confidence) : 상품 A가 구매되었을 때, 상품 B가 구매될 확률, P(B|A)를 나타냄
- 향상도(Lift) : 상품 A를 구매한 사람이 B를 구매할 확률과 A의 구매와 상관없이 B를 구매할 확률의 비율 P(B|A)/P(B) = P(A∩B)/P(A)P(B)
- 향상도에서 만약 A와 B가 독립이라면 P(A∩B)가 P(A)*P(B) 이므로 Lift=P(A)*P(B)/P(A)*P(B) = 1된다.
- 즉, A와 B가 관련성이 없다면 LIFT=1이 되고, LIFT>1면 LIFT값이 클수록 관련도가 높다
- LIFT <1 면 오히려 A를 구매한 사람은 B를 구매하지 않는다는 결론이 나온다.
3. 연관 분석 절차
- Apriori 알고리즘 분석 절차
- 최소지지도를 설정
- 개별품목 중에서 최소 지지도를 넘는 모든 품목을 찾음
- 찾은 개별 품목만을 이용하여 최소 지지도를 넘는 두 가지 품목 집합을 찾음
- 찾은 품목 집합을 결합하여 최소 지지도를 넘는 세 가지 품목 집합을 찾음
- 반복적으로 수행하여 최소 지지도가 넘는 빈발품목을 찾음
- 장점
- 결과가 분명하다 (If-then 규칙)
- 거대 자료의 분석의 시작으로 적합하다.
- 변수의 개수가 많은 경우에 쉽게 사용될 수 있다.
- 계산이 용이하다.
- 단점
- 품목 수의 증가에 따라 계산량이 폭증한다.
- 자료의 속성에 제한이 있다. 예를 들면, 구매자의 개인정보 중 나이 등의 연속형 변수를 사용할 수 없다.
- 적절한 품목을 결정하기가 어렵다.
- 거래가 드문 품목에 대한 정보를 찾기가 어렵다.
[기출 문제]
1. 시간의 흐름에 따라 관측된 데이터를 무엇이라 하는가?
① 주성분 분석
② 회귀분석
③ 시계열 자료
④ 군집분석
2. 붓스트랩 방식을 이용했을 때 일반적인 훈련 데이터 양은?
① 63.2%
② 10.2%
③ 33.2%
④ 36.8%
3. Boxplot에 관한 설명이다 적절하지 않은 것은?
① 중위수는 상자의 선으로 표시된다.
② 사분위 간 범위 상자는 데이터 중간의 50%를 나타냄
③ 수염은 상자의 양쪽에 연결되며, 데이터의 상위, 하위 25%의 범위를 나타낸다.
④ 상자박스는 그룹간의 분포차이를 비교할 수 있다.
4. K-평균 군집의 설명 중 옳은 것은?
① 결과는 덴드로그램의 형태로 표현된다.
② 한번 군집이 형성되면 군집에 속한 개체는 다른 군집으로 이동할 수 없다.
③ 초기값을 지정하지 않는다.
④ 알고리즘이 단순하며, 빠르다.
5. 분해 시계열에 대한 설명 중 적절하지 않은 것은?
① 추세요인 : 어떤 특정한 형태를 취할 떄
② 계절요인 : 고정된 주기에 따라 자료가 변화는 경우
③ 순환요인 : 급격한 인구증가 등의 이유로 인하여 주기를 가지고 변화하는 자료
④ 불규칙 요인 : 위 세가지 요인으로 설명할 수 없는 요인에 의해 발생
6. 최솟값, 1사분위수, 중위수, 3사분위수, 최댓값, 평균값을 구하는 함수는?
① str
② summary
③ head
④ inform
7. hclust에 관한 설명 중 적절하지 않은 것은?
① 최단 연결법은 평균 연결법 보다 계산량이 많아 질 수 있다.
② 중심 연결법은 두 군집의 중심간의 거리를 측정한다.
③ 최단 연결법은 고립된 군집을 찾는데 중점을 둔 방법이다.
④ 최단 연결법은 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타 날 수 있는 거리의 최솟값으로 측정한다.
8. 다음 중 변수의 표준화와 함께 변수간의 상관성을 동시에 고려한 통계적 거리는?
① 유클리드
② 맨하튼
③ 마할라노비스
④ 민코프스키
9. 상관 분석에 대한 설명으로 옳지 않은 것은?
① 종속변수 값을 예측하는 선형 모형 추출 방법이다.
② 데이터 안의 두변수간의 관련성을 파악하는 방법이다.
③ 관련성의 정도를 측정하는 방법으로 상관 계수를 이용한다.
④ 두 변수간의 비선형 관계를 알 수 있다.
10. 데이터 마이닝 단계 중 데이터마이닝 소프트웨어에 적용 할 수 있게 데이터를 준비하는 단계는 ?
① 데이터 준비
② 데이터 가공
③ 목적 정의
④ 데이터 마이닝 기법 적용
11. 연관규칙의 향상도 설명이 옳은 것은?
① 향상도가 1보다 높아질 수록 연관성이 낮다
② 향상도가 1이면 서로 독립관계이다.
③ 향상도가 1이면 연관성이 있다.
④ 향상도가 0이면 서로 독립관계이다.
12. 각 열이 서로 다른 타입의 데이터 구조가 가능한 것은?
① 벡터
② 행렬
③ 데이터프레임
④ 배열
13. 비모수 검정의 특징이 아닌 것은?
① 관측값들의 순위나 부호등을 이용해 검정한다.
② 평균, 분산등을 이용해 검정을 실시한다.
③ 특정 분포를 따른다고 가정하지 않는다.
④ 추론시 수많은 모수가 필요할 수 있다.
14. SOM에 대한 설명이 잘못된 것은?
① 역전파 알고리즘을 사용한다.
② 비지도 학습의 신경망이다.
③ 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 형상화한다.
④ 데이터의 특징을 파악하여 유사 데이터를 Clustering한다.
15. 이질적인 모집단을 세분화시키기 위한 방법은?
① 연관분석
② 분류분석
③ 주성분분석
④ 군집분석
16. 다음 중 앙상블 모형이 아닌 것은?
① 배깅(bagging)
② 랜덤 포리스트(random forest)
③ 부스팅
④ 시그모이드(sigmoid)
17. 다음은 가설검정에 관한 설명이다. 가장 적절하지 않은 것은?
① 귀무가설이 옳은데도 귀무가설을 기각하게 되는 오류를 제1종 오류라고 한다.
② 점추정은 ‘모수가 특정한 값일 것‘이라고 선언하는 것이다.
③ 유의수준은 제2종 오류의 최댓값이다.
④ 가설 검정이란 모집단에 대한 어떤 가설을 설정한 뒤에 표본관찰을 통해 그 가설의 채택 여부를 결정하는 분석 방법이다.
18. y=c(1,2,3,NA)일때 3*y의 결과는?
① NA NA NA NA
② FALSE
③ 3 6 9 NA
④ NA
19. 기업이 보유하고 있는 각종 내부 데이터와 이외의 외부 데이터를 포함하는 모든 사용 가능한 원천 데이터를 기반으로 감춰진 지식, 기대하지 못했던 경향 또는 새로운 규칙등을 발견하고 이를 실제 비즈니스 의사결정 등에 유용한 정보로 활용하는 일련의 작업을 무엇이라 하는가?
① 분류분석
② 데이터마이닝
③ 기술분석
④ 군집분석
20. 다음 중 결측값 처리에 대한 imputation에 관한 내용 중 틀린 것은?
① 관측된 자료의 평균값으로 결측값을 대치하여 분석할 수 있다.
② 단순확률 대치법은 평균 대치법의 과소 추정 문제를 보완하고자 고안된 방법이다.
③ 불완전 자료를 모두 무시하고 완전하게 관측된 자료만으로 분석하는 방법이다.
④ 다중 대치법은 추정량의 과소 추정이나 계산의 난해성 문제를 보완하는 방법이다.
21. 회귀분석 모형에 관한 설명 중 부적절한 것은 ?
① 모형이 얼마나 설명력을 갖는지는 결정계수를 확인한다.
② 모형이 통계적으로 유의미한지는 p-value를 확인한다.
③ p-value가 5% 이상이면 유의미하다고 할 수 있다.
④ 회귀계수는 회귀식의 기울기에 해당한다.
22. 데이터 분할에 관한 설명 중 적절하지 않은 것은?
① 모델을 만들 때 training set과 test set으로 나누어 사용한다.
② 모델이 단순하여 정확도가 낮은 모델을 과소적합 되었다고 말한다.
③ test set 결과가 training set 결과보다 좋다.
④ 데이터를 더 많이 더 다양하게 확보하는 것이 모델의 정확도를 높이는 방법이다.
23. 군집 분석 설명 중 옳은 것은 ?
① 혼합분포군집 기법 – CURE
② 밀도기반 기법 – DBSCAN
③ 모델기반 군집화 기법 – AGNES
④ 격자기반 기법 – 코호넨 네트워크
24. 다음 중 연관분석 설명으로 적절하지 않은 것은?
① 품목 수가 증가하면 분석에 필요한 계산은 기하급수적으로 늘어난다.
② 너무 세분화된 품목을 가지고 연관규칙을 찾으려면 의미 없는 분석 결과가 나온다.
③ 분석 계산이 간편하고 분석 결과를 이해하기 쉽다.
④ 상대적으로 거래량이 적으면 규칙 발견하기가 좋다
25. 오분류표의 TN=50, FP=10, FN=5, TP=10일 때 Accuracy를 구하시오?
(TN+T P) / 75 = 60/75 =0.8
26. 시계열 자료에서 모든 시점에 대해 일정한 평균을 가지는 것을 어떤 특성이라고 하는가?
정상성
27. 아래의 결과에서 주성분 3개를 수용했을 때 잃는 정보량은 얼마인가?
약 4.4%

28. 군집 분석에서 중요한 지표로서, 거리가 가까울수록 높고 멀수록 낮은 지표이자 완벽히 분리된 경우 1이 되는 지표는?
** Dumm Index = 군집과 군집 사이의 최솟값/ 군집내의 데이터들 거리 중 최댓값
분자값이 클수록 군집간의 거리가 멀고, 분모값이 작을 수록 군집 내의 데이터가 잘 모여있으므로 Dumm Index 값이 커진다. 즉, Dumm Index 값이 클수록 군집화가 잘되어 있다고 볼 수 있다.
** 실루엣(Silhouette)은 1에 가까울수록 군집화가 잘 되어 있다고 판단할 수 있다.
실루엣
29. 평균이 일정하지 않은 경우에 현재 시점에서 바로 전 시점의 자료값을 빼는 것을 무엇이라고 하는가?
차분
30. 단순회귀 분석에서 사용하는 모형 탐색법은?
OLS (ordinary least square)
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'자기계발 > 자격증' 카테고리의 다른 글
| [자격증] 데이터분석 전문가 (ADP) 필기 : 10회, 11회 기출 문제 (0) | 2022.10.27 |
|---|---|
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제5과목 데이터 시각화 (0) | 2022.10.27 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제3과목 데이터 분석 기획 (0) | 2022.10.27 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제2과목 데이터 처리 기술 이해 (1) | 2022.10.15 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제1과목 데이터 이해 (1) | 2022.10.15 |