

정보
- 업무명 : 데이터분석 전문가 (ADP) 필기 : 제2과목 데이터 처리 기술 이해
- 작성자 : 이상호
- 작성일 : 2022.10.15
- 설 명 :
- 수정이력 :

내용
[ETL (Extraction, Transformation and Load)]
- Extraction (추출) : 원천들로부터 데이터 획득
- Transformation (변형) : 데이터 클렌징, 형식변환, 표준화,통합
- Load (적재) : 적재
[ODS (Operational Data Store) 구성]
- 데이터에 추가 작업을 위해 다양한 데이터 원천들로부터의 데이터 추출 통합한 데이터베이스
[데이터웨어하우스 특징]
- 주제 중심 : 데이터 웨어하우스의 데이터는 실 업무 상황의 특정 이벤트나 업무 항목을 기준으로 구조화된다.
- 영속성 : 데이터 웨어하우스의 데이터는 최초 저장 이후에는 읽기 전용 속성을 가지며 삭제되지 않는다.
- 통합성 : 데이터 웨어하우스의 데이터는 기관, 조직이 보유한 대부분의 운영 시스템들에 의해 생성된 데이터들의 통합본이다.
- 시계열성 : 운영 시스템들은 최신 데이터를 보유하고 있지만, 데이터 웨어하우스는 시간순에 의한 이력 데이터를 보유한다.
- 스타 스키마

- 스노우 플레이크 스키마 : 스타스키마의 차원 테이블을 제3정규형으로 정규화한 형태

[CDC (Change Data Capture)]
- 데이터베이스 내 데이터에 대한 변경을 식별해 필요한 후속처리(데이터 전송/공유)를 자동화하는 기술 또는 설계 기법이자 구조
- CDC 구현 기법
- Time Stamps on Rows
- Version Numbers on Rows
- Stratus on Rows
- Time/Version/Status on Rows
- Triggers on Tables
- Event Programming
- Log Scanner on Database
[EAI (Enterprise Application Integration)]
- 기업 정보 시스템들의 데이터를 연계 통합하는 소프트웨어 및 정보 시스템 아키텍처 프레임워크
- 구현 유형
- 가. Meditation (intra-communication) : Publish – subscribe 모델
- EAI 엔진이 중개자로 동작
- 나. Federation(inter-communication) : Request – reply 모델
- EAI 엔진이 외부 정보 시스템(고객 또는 파트너)으로부터의
데이터 요청들을 일괄적으로 수령해 필요한 데이터를 전달
- EAI 엔진이 외부 정보 시스템(고객 또는 파트너)으로부터의
- 가. Meditation (intra-communication) : Publish – subscribe 모델
[데이터 연계 및 통합 기법 요약]
- 데이터 연계 밑 통합 아키텍처 비교
| 일괄 통합 | 비동기식 실시간 통합 | 동기식 실시간 통합 |
| 비실시간 데이터 통합 대용량 데이터 대상 높은 데이터 조작 복잡성 데이터 추출 데이터 변형 데이터 적재 Change data capture 감사 증적(audit trail) 웹 서비스/SOA 교차 참조 데이터 재 처리 허용 점대점 데이터 연계 자동화 도구 및 자체 개발 SW 혼용 |
근접 실시간 데이터 통합 중간 용량 데이터 중간 데이터 조작 복잡성 데이터 추출,변형, 적재 Change data capture Data pooling and DB Streams 웹 서비스/SOA 감사 증적(audit trail) 교차 참조 다수 데이터 원천 및 목표 시스템 데이터 재 처리 허용 자동화 도구 및 자체 개발 SW 혼용 |
실시간 데이터 통합 목표 시스템 데이터 처리 가능시에만 원천 데이터 획득 데이터 추출,변형,적재 웹 서비스/SOA Single transaction integration 단일 트랜잭션 단위 데이터 통합 데이터 재처리 불가 단일 또는 다수 데이터 원천 감사 증적(audit trail) |
- 일괄 통합
- 비실시간 데이터 통합
- 대용량 데이터 대상
- 높은 데이터 조작 복잡성
- 데이터 추출
- 데이터 변형
- 데이터 적재
- Change data capture
- 감사 증적(audit trail)
- 웹 서비스/SOA
- 교차 참조
- 데이터 재 처리 허용
- 점대점 데이터 연계
- 자동화 도구 및 자체 개발 SW 혼용
- 비동기식 실시간 통합
- 근접 실시간 데이터 통합
- 중간 용량 데이터
- 중간 데이터 조작 복잡성
- 데이터 추출,변형, 적재
- Change data capture
- Data pooling and DB Streams
- 웹 서비스/SOA
- 감사 증적(audit trail)
- 교차 참조
- 다수 데이터 원천 및 목표 시스템
- 데이터 재 처리 허용
- 자동화 도구 및 자체 개발 SW 혼용
- 동기식 실시간 통합
- 실시간 데이터 통합
- 목표 시스템 데이터 처리 가능시에만 원천 데이터 획득
- 데이터 추출,변형,적재
- 웹 서비스/SOA
- Single transaction integration
- 단일 트랜잭션 단위 데이터 통합
- 데이터 재처리 불가
- 단일 또는 다수 데이터 원천
- 감사 증적(audit trail)
- 데이터 처리 기법 비교
| 구분 | 전통적데이터처리기법 | 빅데이터 처리 기법 |
| 추출 | 운영 DB -> ODS -> DW | 빅데이터 환경 |
| 변환 | O | O |
| 로딩 | O | O |
| 시각화 | X | O |
| 분석 | OLAP, 통계와 데이터마이닝 | 통계와 데이터마이닝 |
| 리포팅 | BI | BI |
| 인프라스트럭처 | SQL, 전통적 RDBMS | NoSQL, 초대형 분산 데이터 스토리지 |
[대용량 비정형 데이터 처리]
- 1. 대용량 로그 데이터 수집
- 초고속 수집 성능과 확장성
- 데이터 전송 보장 메커니즘
- 다양한 수집과 저장 플러그인
- 인터페이스 상속을 통한 애플리케이션 기능 확장

- 2. 대규모 분산 병렬 처리 (하둡)
- 선형적인 성능과 용량 확장
- 고장감내성
- 핵심 비즈니스 로직에 집중
- 풍부한 에코시스템 형성

[데이터 연동]
- 스쿱
- 데이터베이스를 대상으로 맵리듀스와 같은 대규모 분산 병렬 처리를 하는 것은 심한 부하를 야기할 수 있음
- 이러한 이유로 정형 데이터와 비정형 데이터간의 연계 분석을 위해서 데이터베이스의 데이터를 하둡으로 복사를 한 후 하둡에서 대규머 분산 병렬 처리를 수행
- 그 결과로 생성된 요약된 작은 데이터 셋을 다시 데이터베이스에 기록

[대용량 질의기술]
- 아파치 드릴 : 드레멜의 아키텍처와 기능을 동일하게 구현한 오픈 소스 버전의 드레멜
- 아파치 스팅거 : 기존의 하이브 코드를 최대한 이용하여 성능 개선하는 식으로 개발 진행
- 샤크 : 인메모리 기반의 대용량 데이터웨어하우징 시스템
- 아파치 타조
- 임팔라 : 하둡 전문 회사인 클라우데라에서 개발 주도
- 호크 : 상용과 커뮤니티 2가지 버전 제공
- 프레스토 : 페이스북에서 자체적으로 개발, 하둡 기반의 데이터웨어하우징 엔진

[데이터 처리 기술]
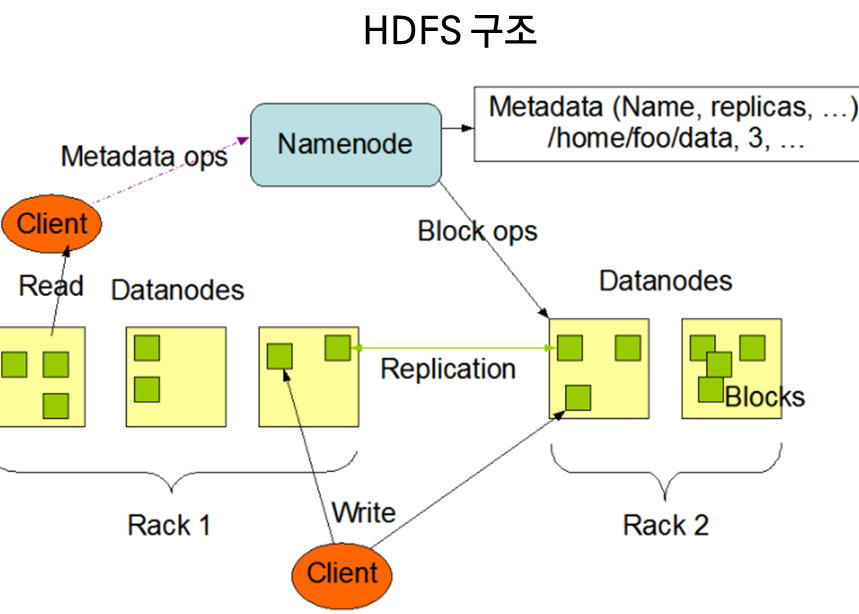
- 분산파일시스템
- GFS, HDFS, 러스터 (객체 기반 클러스터 파일 시스템)
- 데이터베이스 클러스터
- 무공유
- 무공유 클러스터에서 각 데이터베이스 인스턴스는 자신이 관리하는 데이터 파일을 자신의 로컬 디스크에 저장하며, 이 파일들은 노드 간에 공유하지 않는다.
- 공유디스크
- 클러스터에서 데이터 파일은 논리적으로 모든 데이터베이스 인스턴스 노드들과 공유하며, 각 인스턴스는 모든 데이터에 접근할 수 있다.
- Oracle RAC 서버
- 가용성
- 확장성
- 비용절감
- IBM DB2
- MS SQL 서버
- MySQL
- NoSQL (구글 빅테이블, 아마존 Simple DB, 마이크로소프트 SSDS)
[분산 컴퓨팅 기술]
- MapReduce
- 분할정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델
- 특별한 옵션을 주지 않으면 Map task 하나가 1개의 블록 (64MB)을 대상으로 연산 수행
- 분할정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델

[병렬 쿼리 시스템]
- 구글 sawzall
- MapReduce를 추상화한 스크립트 형태의 병렬 프로그래밍 언어
- Sawzall은 사용자가 이해하기 쉬운 인터페이스를 제공하여 MapReduce 개발 생산성을 높였다.
- 이로써 MapReduce에 대한 이해가 없는 사용자들도 더욱 쉽게 병렬 프로그래밍을 할 수 있게 되었다.
- MapReduce를 추상화한 스크립트 형태의 병렬 프로그래밍 언어
- 아파치 피그
- 야후에서 개발해 오픈소스 프로젝트화한 데이터 처리를 위한 고차원 언어
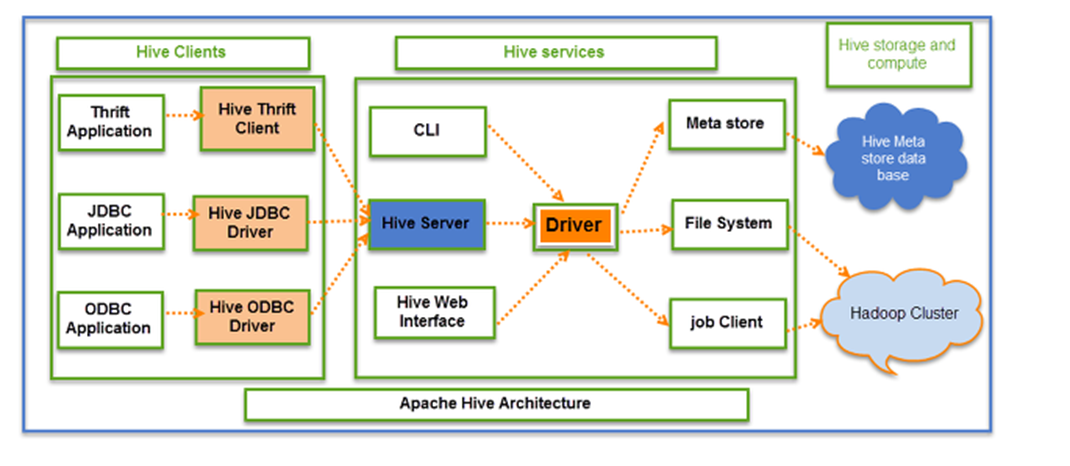
- 아파치 하이브
- 페이스북에서 개발한 데이터 웨어하우진 인프라, 하둡플랫폼에서 동작하며, 사용자가 쉽게 사용할 수 있도록 SQL 기반 쿼리 언어인 JDBC를 지원
[SQL on Hadoop]
- 임팔라
- 분석과 트랜잭션 처리를 모두 지원하는 것을 목표로 만든 SQL 질의 엔진 하둡과 Hbase에 저장된 데이터를 대상으로 SQL 질의를 할 수 있다.

[클라우드 인프라 기술]
- 클라우드 컴퓨팅은 동적으로 확장할 수 있는 가상화 자원들을 인터넷으로 서비스 할 수 있는 기술이고 아래의 3가지 유형으로 나뉨
- SaaS (Software as a Service)
- PaaS (Platform as a Service)
- IaaS (Infrastructure as a Service)
- 클라우드 컴퓨팅에서 인프라 기술은 근간이 되는 기술
- 특히 서버 가상화 기술은 물리적인 서버와 운영체제 사이에 적절한 계층을 추가해 서버를 사용하는 사용자에게 물리적인 자원은 숨기고 논리적인 자원만을 보여주는 기술을 말한다.
[서버 기술 가상화 효과]
- 가상머신 사이의 데이터 보호
- 예측하지 못한 장애로부터 보호
- 공유자원에 대한 강제 사용의 거부
- 서버 통합
- 자원할당에 대한 증가된 유연성
- 테스팅
- 정확하고 안전한 서버 사이징
- 시스템 관리
- CPU 가상화
- 완전 가상화
- 하드웨어 지원 완전가상화
- 반가상화
- 호스트기반 가상화
- 컨테이너 기반 가상화
- 메모리 가상화
- I/O 가상화

참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'자기계발 > 자격증' 카테고리의 다른 글
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제4과목 데이터 분석 (0) | 2022.10.27 |
|---|---|
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제3과목 데이터 분석 기획 (0) | 2022.10.27 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제1과목 데이터 이해 (1) | 2022.10.15 |
| [자격증] 정보처리기사 필기 : 제5과목 정보시스템 구축 (시스템 보안 구축) (0) | 2021.03.03 |
| [자격증] 정보처리기사 필기 : 제5과목 정보시스템 구축 (소프트웨어 개발 보안 구축) (0) | 2021.03.03 |