

정보
-
업무명 : 정보처리기사 실기 : 21강 SQL 응용 (절차형 SQL 작성하기)
-
작성자 : 이상호
-
작성일 : 2020-05-11
-
설 명 :
-
수정이력 :

내용
[프로시저 및 호출문 작성]
[1] 절차형 SQL
-
1. 절차형 SQL의 개념
-
타 개발 언어와 유사하게 SQL에도 절차 지향적인 프로그램이 가능하며, 이를 이용하여 SQL문의 연속적인 실행나 조건에 따른 분기, 반복 등의 제어를 활용하여 다양한 기능을 수행하는 저장 모듈을 생성하고 쉽게 활용할 수 있다.
-
이는 DB 작업의 고효율화를 기반으로 높은 생산성을 확보할 수 있게 해 준다. 다음은 절차형 SQL 내의 작업 진행을 간략히 표시한 추상적 개념도이다.
-

-
2. 절차형 SQL의 특징
-
절차형 SQL의 특징은 다음과 같다.
-
DBMS 엔진에서 직접 실행한다.
-
BEGIN/END의 Block화된 구조로 되어 있어 각 기능별로 모듈화가 가능하다.
-
조건문, 반복문 등 단일 SQL 문장으로는 실행하기 어려운 연속적인 작업을 처리하는 데에 적합하다.
-
일련의 작업에 필요한 데이터를 DBMS 내부에서 직접 처리하기 때문에 일반적으로 Input/Output Packet이 적다.
-
타 절차형 언어에 비해 작업의 효율성은 낮은 편이다.
-
DBMS 벤더별 차이가 있어서 벤더가 다른 환경에 이식하는 경우 수정 및 재컴파일이 필요하다.
-
-
-
3. 절차형 SQL의 구성 프로시저, 사용자 정의함수 및 트리거 등이 다소 차이가 있으나 필수적 요소를 고려한 구성은 아래와 같다. 아래의 요소만 갖추어도 정상적인 컴파일도 가능하고 실행도 가능하다.
-
DECLARE: 대상이 되는 프로시저, 사용자 정의함수 등을 정의
-
BEGIN: 프로시저, 사용자 정의함수가 실행되는 시작점
-
END: 프로시저, 사용자 정의함수가 실행되는 종료점
-

-
4. 절차형 SQL의 유형
-
DBMS 벤더에 따라 P제품(O사), T제품(M사), S제품(D사) 등의 절차형 SQL이 있다. 벤더에 따라 특성성 차이가 있으나 기본적 맥락은 동일하다. 다만, 벤더가 다른 환경에 이식하는 경우 수정 및 재컴파일이 필요할 수 있다.
-
(1) P제품
-
O사의 SQL 언어를 확장하기 위해 사용하는 절차형 SQL 언어이다. P제품의 특징은 다음과 같다.
-
O사와 P제품을 지원하는 어떤 서버로도 프로그램을 옮길 수 있는 이식성을 가진다.
-
P프로그램을 입력받으면 SQL 문장과 프로그램 문장을 구분하여 처리한다. 즉, 프로그램 문장은 P 엔진이 처리하고 SQL 문장은 O사 서버의 SQL Statement Executor가 실행 하도록 작업을 분리하여 처리한다
-
-
(2) T제품
-
M사에서 ANSI / ISO 표준의 SQL에 약간의 기능을 더 추가하여 보완적으로 만든 것이다.
-
변수 선언 기능 @@이라는 전역 변수(시스템 함수)와 @이라는 전역 변수가 있다.
-
지역 변수는 사용자가 자신의 연결 시간 동안만 사용하기 위해 만들어지는 변수이 며, 전역 변수는 이미 SQL 서버에 내장된 값이다.
-
흐름 제어 사용이 가능하며 연산자 사용, 데이터 유형 제공이 가능하다.
-
-
-
-
[2] 프로시저 작성
-
1. 프로시저의 개념
-
프로시저는 절차형 SQL을 활용하여 특정 기능을 수행할 수 있는 트랜잭션 언어이다.
-
프로시저 호출을 통해 실행되며, 이를 통해 일련의 SQL 작업을 포함하는 데이터 조작어(DML: Data Manipulate Language)를 수행하는 것이 일반적이다.
-
시스템에서의 일일 마감 작업, 또는 일련의 배치 작업 등을 프로시저를 활용하여 관리하고 주기적으로 수행하기도 한다.
-
-
2. 프로시저의 구성
-
일반적인 프로시저의 구성은 다음과 같다.
-

-
DECLARE
-
: 프로시저의 명칭, 변수와 인수 그리고 그에 대한 데이터 타입을 정의하는 선언부이다.
-
-
BEGIN / END
-
: 프로시저의 시작과 종료를 표현하는 데 필수적이며, BEGIN / END를 쌍을 이루어 추가하므로 Block을 구성한다. 다수 실행을 제어하는 기본적 단위가 되며 논리 적 프로세스를 구성한다.
-
-
CONTROL
-
: 기본적으로는 순차적으로 처리한다. 특정 비교 조건에 따라(IF) 참인 Block 또는 문장을 실행하거나(THEN), 기타의 경우에도 조건에 맞는 Block 또는 문장을 실행 한다(ELSIF 또는 ELSE). 조건에 따라 반복을 수행할 수도 있다. (LOOP).
-
-
SQL
-
: DQL(SELECT), DML(INSERT, UPDATE, DELETE)을 주로 사용한다. 자주 사용하지 는 않으나 DDL(TRUNCATE 등)을 사용하기도 한다.
-
-
EXCEPTION
-
: BEGIN ~ END절에서 실행되는 SQL문이 실행될 때 예외 발생 시 예외 처 리 방법을 정의하는 처리부이다.
-
-
TRANSACTION
-
: 프로시저에서 수행된 DML 수행 내역의 DBMS의 적용 또는 취소 여부를 결정하는 처리부이다. 일반 SQL과 동일하게 최종 COMMIT / ROLLBACK 시점 이후부터 실행된 DML의 적용 / 취소를 수행한다
-
-
3. 프로시저의 문법
-
상기 설명한 프로시저의 구성에 기반한 프로시저의 문법은 다음과 같다.
-
- CREATE 명령어로 DBMS 내에 프로시저 생성이 가능하다.
-
- [OR REPLACE] 명령은 기존 프로시저 존재 시에 현재 컴파일하는 내용으로 덮어쓴다는 (Overwrite) 의미이다. 기존 동명의 프로시저가 존재하고 CREATE 명령문만 사용하면 컴파일 시에는 에러가 발생한다.
-
- PARAMETER는 외부에서 프로시저 호출 시 변수를 입력 또는 출력할 수 있다. MODE는 변수의 입력/출력을 구분하며 다음과 같이 사용한다.
-
(가) IN: 운영 체제에서 프로시저로 전달되는 MODE
-
(나) OUT : 프로시저에서 처리된 결과가 운영 체제로 전달되는 MODE
-
(다) INOUT : IN과 OUT의 두 가지 기능을 동시에 수행하는 MODE
-
-
-

-
4. 프로시저의 예시 아래는 매출 마감 처리를 하는 간단한 프로시저이다.
-
마감 일자(V_CLOSING_DATE)를 입력변수로 선언한다.
-
내부에서 매출 총액 변수(V_SALES_TOT_AMT)를 선언한다.
-
판매 내역 테이블(SALES_LIST_T)에서 마감 일자의 매출액 합계(SALES_AMT)를 계산하 여 매출 총액 변수에 입력한다.
-
예외 사항으로 데이터 미 존재 시 매출 총액은 0으로 입력한다.
-
마감 내역 테이블(SALES_CLOSED_T)에 마감 일자와 매출 총액을 삽입한다.
-
종료 시 COMMIT으로 트랜잭션을 완료 처리한다.
-

-
작성된 프로시저는 외부 호출을 통해서 실행된다. 응용 프로그램에서 호출하거나 내부 스케줄러에 의해 배치 작업을 수행하는 경우 등에 호출되어 프로시저가 사용된다.
-
1. 프로시저 호출문의 문법 SQL 명령어를 활용하여 작성된 프로시저를 호출한다.
-
SQL TOOL을 활용하여 직접 실행시키는 경우에는 EXECUTE, 줄여서 EXEC 명령어를 실 행하여 프로시저를 실행한다.
-
프로시저에 입출력 변수가 존재하는 경우 데이터 유형 및 MODE에 변수를 입력하여 실행한다. 데이터 유형의 경우 자동 변환이 되어고 별도 오류 가 발생하지 않는 경우가 많지만 가급적 프로시저에서 선언한 데이터 타입과 동일하게 입 출력 변수를 넣어서 실행시킨다.
-
SQL TOOL 등을 사용하지 않고 응용 프로그램이나 타 프로시저 등에서 호출 시에는 프 로그램에 따라 별도 명령어 없이 “@프로시저명” 또는 프로시저 명칭만 적어서 호출 가능하다.
-
-

-
2. 프로시저 호출문 예제
-
위에서 제시된 프로시저 예제를 호출하는 경우를 예시로 한다.
-

[수행-프로시저 및 호출문 작성하기]
[1] 프로시저 작성
-
1. 프로시저 작업 목표를 수립한다.
-
(1) 데이터 작업을 통해 구현하고자 하는 데이터 변경 항목을 정의한다.
-
(2) 단순 데이터 작업이 아닌, 일련의 절차를 통해 구현 가능한지 검토하고, 해당되는 경우 프로시저를 사용하는 것을 결정한다.
-
(3) 프로시저를 통해서 구현하려고 하는 기능이나 일련의 작업에 대한 대략적 개념을 상기한다.
-

-
2. 생성할 프로시저에 관련되거나 필요한 테이블 및 데이터를 확인한다.
-
(1) 프로시저 내에서 구현하고자 하는 결과 데이터 생성을 위한 요소 데이터가 맞는지 확인한다.
-
(2) 필요로 하는 모든 데이터를 조사하였는지 확인하고, 추가로 필요한 데이터가 없는 지 점검한다.
-
(3) 관련된 모든 데이터가 포함된 기존 테이블 및 구조를 확인한다.
-
(4) 다수의 테이블로부터 데이터를 검색하는 경우에는 조인(JOIN)이나 집합 명령어 등을 활용할 수 있다.
-
-
3. 관련된 기존 테이블 및 데이터 간의 관계를 분석한다.
-
(1) 필요로 하는 모든 데이터 조회 및 접근이 가능하도록 한다. 조사한 테이블의 구조 및 주키(PK : Primary Key), 외래키(FK : Foreign Key)를 확인하여 테이블 간의 관계를 정의할 수 있도록 한다.
-
(2) 관련된 데이터를 분석한다. 문자열, 코드, 숫자, 날짜 등 데이터 형식도 확인하고 설계 시 반영 가능하도록 누락된 사항이 없는지 점검한다.
-
(3) 구현에 필요한 모든 데이터를 취합하였는지 확인하고, 필요시 이전 단계로 돌아가 필요한 데이터 및 관련 테이블을 조사한다. 설계 단계에서 누락된 데이터를 확인하고 작성하는 것도 무방하나, 전체 프로세스 및 데이터 흐름 작성 측면에서 필요로 하는 데이터는 모두 취합하고 설계하는 것이 바람직하다.
-
-
4. 프로시저의 기능을 설계한다.
-
(1) 프로시저의 변수를 분석한다.
-
(가) 프로시저 외부와 연동되어야 하는 입력, 출력변수를 분석한다.
-
1) 프로시저 외부와 연동되는 입력변수를 분석한다. 여기서 입력변수는 테이블로부터 데이터를 조회하는 것이 아니라, 프로시저 수 행 시 외부에서 변수(Parameter)로 입력을 통해 넣는 값을 의미한다. 예를 들면, 일별 판매액 집계 시 대상이 되는 일자 등은 프로시저 수행 시 지정하게 되며, 이 값이 외부의 입력변수이다.
-
2) 프로시저 외부와 연동되는 출력변수를 분석한다. 프로시저의 출력변수는 사용자 정의함수에서의 결과와는 조금 다르게 프로시저 실행에 대한 결과나 오류코드 및 내용 등의 문장(Comment)을 사용하는 경우가 대다수이다. 필수적인 것은 아니지만 프로시저 실행에 대한 요약이나 결론 등을 나타낼 때 좋으니 참조한다.
-
-
(나) 프로시저 내부에서 생성하고 활용되어야 하는 변수를 분석한다. 별도의 변수 선언이나 값 등을 입력하고 계속 사용하는 값을 대상으로 하는 것이 좋다. 모든 값을 내부 변수로 사용할 필요는 없으며, 예를 든다면 자주 사용되는 현재의 시간이나 목표일 등의 값이다.
-
-
(2) 프로시저의 데이터 흐름도를 작성한다.
-
(가) 주요 데이터값을 위주로 전체적인 흐름을 구상한다. 가령 프로시저 초반에는 필요로 하는 값들을 조회하고 원하는 중간 결과값 등을 산출하여 마지막에는 원하는 데이터를 입력하는 것 정도가 이에 해당한다.
-
(나) 조건, 반복, 분기 등의 데이터 흐름을 위주로 프로세스를 작성한다. 동일한 결 과를 얻는 프로시저를 작성하더라도 어떻게 데이터 흐름을 설계하느냐에 따라 전체적 성능이나 소요시간 등의 차이가 발생할 수 있다. 단순한 구조를 유지하 며, 효과적 흐름이 가능하도록 전체 흐름을 설계한다.
-
(다) 데이터 흐름도 작성은 프로시저 작성 과정 중 가장 핵심적인 사항이다. 단독으로 설계하는 것보다 관련자들과의 논의를 통해 진행하는 것도 추천한다.
-
-
(3) 예외 처리를 설계한다.
-
(가) 프로시저 내부에서 사용되는 SQL문의 예외 발생 상황을 설계한다. 데이터 질의 어(DQL: Data Query Language)의 경우에는 조회되는 데이터가 없거나 단일 내 부 변수값에 다수 결과값을 입력하는 등의 경우가 있을 수 있다.
-
(나) 발생 가능한 상황 별 예외를 정의하고 처리 방안을 구상한다. 해당 프로시저가 실행되며 발생 가능한 상황을 가정하고 사전에 정의함으로써, 실행 중 가능한 12 에러 상황을 방지하고 처리 방안을 제시한다
-
-
(4) 프로시저 실행 시의 예기치 않은 상황을 고려했는지 확인한다.
-
(가) 프로시저 실행이 실행 빈도에 영향을 주지 않도록 작성한다. 예를 들면 하루에 한 번 실행되는 것을 가정하고 작성하더라도 운영환경에서의 예기치 않은 사정 에 의해 두 번 이상 실행될 수 있음을 염두에 둔다. 이런 경우 두 번 이상 실 행이 되지 않거나, 실행이 되더라도 결과에 영향을 주지 않도록 설계한다.
-
(나) 트랜잭션(Transaction)의 위치를 고민한다. 내부적으로 간단한 경우에는 정상 종 료시에만 프로시저 마지막에 반영(COMMIT)하는 것이 가장 좋다는 것을 숙지 하고 설계한다. 참고로, 복잡한 프로시저나 내부에서 다루는 데이터의 용량이 매우 큰 경우, 마지막에 반영하기에는 DBMS 메모리에 많은 부담을 주게 된다. 이런 경우는 중간중간 반영을 하고 별도의 DB LOG를 적재하거나 테이블에 작업내역을 삽입하는 경우도 있음을 숙지한다.
-
-
-
5. 프로시저를 작성한다.
-
(1) 프로시저의 변수를 선언한다.
-
(가) 설계 단계에서 작성한 프로시저 외부와 연동되어야 하는 입력, 출력변수를 선언하고 활용한다.
-
(나) 설계 단계에서 작성한 프로시저 내부에서 생성하고 활용되어야 하는 변수를 선언하고 활용한다.
-
-
(2) 프로시저의 기능 설계를 바탕으로 작성한다.
-
(가) 설계한 데이터 프로세스를 중심으로 코드를 작성한다. 가독성 확보 및 블록별 실행 순서 명시화를 위한 줄바꿈(Indentation)에 유의하며 작성한다.
-
(나) 조건, 반복, 분기 등 사전에 정의해 놓은 데이터 흐름 설계를 기반으로 코드를 작성한다.
-
-
(3) 예외 처리를 구현한다.
-
(가) 설계 단계에서 구상한 프로시저 내부에서 사용되는 SQL문의 예외 발생 상황에 서의 코드를 작성한다.
-
(나) 발생 가능한 상황별 예외를 정의하고 처리 방안을 작성한다
-
-
(4) 코딩 규칙을 준수하였는지 확인한다.
-
(가) 소스 가독성을 높이기 위한 줄바꿈(Indentation)을 엄격히 적용한다. 기본적으로 SQL 문장의 가독성을 확보하기 위해 줄바꿈을 적용한다. 프로시저의 경우는 SQL뿐만 아니라 내부에서의 블록화된 부분 및 조건문, 반복문 등의 다양한 명 령어가 사용되므로 특히 더 유의하여 줄바꿈 방식을 적용한다.
-
(나) 내외부 변수 사용 시 변수 명명 방법을 준수하였는지 확인한다. 데이터사전(DD : Data Dictionary)을 사용하는 것이 일반적이며, 용어의 통일을 활용하여 혼동을 최소화하여 생산성 저하를 방지할 수 있다.
-
(다) 주석문을 가급적 많이 작성한다. 주요변수나 데이터 진행흐름, 로직 등을 설계 자나 작성자는 알 수 있지만 타 작업자는 쉽게 이해하지 못하는 경우가 대다수 이다. 이런 경우 가독성 증대를 위해 주석문을 적극 활용한다.
-
-
-
6. 프로시저를 컴파일한다.
-
(1) 프로시저를 컴파일한다. 컴파일하게 되면 DBMS에 반영되고, 그때부터 사용 가능하다.
-
(2) 컴파일 과정 중 에러가 발생할 수 있다. 그럴 경우 컴파일 과정에서 발생하는 메시 지를 참조하여 원인을 해결한다. 에러의 경우는 매우 다양하며, 컴파일하기 전에 알 기가 어려울 수 있기 때문에 에러를 해결하는 과정 중에 필요한 시간이 많이 걸릴 수 있다. 결과 메시지를 최대한 참조하여 에러를 해결하고, 완료되면 재컴파일한다. 대개의 경우 프로시저 컴파일 오류는 문법적 오류로 인해 발생하며, 이 부분에 문 제가 없을 경우 컴파일은 정상적으로 가능하다.
-
[2] 프로시저 호출문을 작성한다.
-
1. 프로시저의 외부 입출력 변수를 확인하고 호출문을 작성한다.
-
(1) 입력, 출력 데이터는 프로시저에서 선언된 데이터 유형(Type: 문자열, 숫자 및 날짜 등)과 일치하게 작성한다. 호출 시 에러가 발생하지 않을 수 있지만 DBMS에서 변환 하는 과정 등에서 비효율적 동작을 필요로 할 수 있으며 정확한 프로그래밍 작성을 위해 지양하도록 한다.
-
(2) 데이터 타입 외 기타 Validation을 고려하여 변수를 작성한다. 예를 들면 8자리의 문 자열로 선언된 변수에 10자리의 문자열을 호출한다거나 존재하지 않는 2월 30일의 날짜를 호출하는 경우이다.
-
-
2. SQL 명령문을 실행하여 프로시저를 호출한다.
-
(1) 정상적으로 종료되는 경우 의도한 바와 같이 작업이 되었는지 확인한다.
-
(가) 프로시저 작성 시 수립한 목표대로 작업이 완료되었는지 확인한다. 대개의 경우 프로시저는 데이터 조작어(DML : Data Manipulation Language)를 수반하고 있 다는 사실을 상기한다.
-
(나) 데이터 질의어(DQL : Data Query Language) 명령어를 사용하여 추가, 수정되거나 삭제된 데이터를 확인한다. 프로시저 수행 후 정상 수행 내역의 확인을 위한 데이터 질의 쿼리를 작성하는 것도 방법이지만, 더 좋은 것은 프로시저를 설계하고 작 성한 다음 곧바로 확인이 가능하도록 쿼리를 미리 작성해 놓는 것이다.
-
-
(2) 비정상적으로 종료되는 경우에는 원인을 확인한다.
-
(가) 프로시저 실행 시 나타나는 오류메시지를 참조하여 어느 과정에서 어떻게 에러 가 발생했는지 확인한다.
-
(나) 메시지를 참조하여 프로시저를 수정하거나 호출문을 수정 후 재호출한다.
-
1) 프로시저가 컴파일은 되었으나, 수행 과정 중 에러가 발생할 수 있다. 단순 에 러이거나 또는 근본적 문제로 인한 것일 수 있다. 에러가 발생하는 부분을 확 인하고 이를 수정한다. 일반적으로 프로시저 호출 과정 중 발생하는 에러의 경우 문제가 되는 프로시저의 줄(Row)과 오류원인을 표현하는 경우가 많다. 이를 참조하여 조치하고 재컴파일한다.
-
2) 프로시저 자체에는 문제가 없으나, 외부 호출문으로 인해 오류가 발생할 수도 있다. 오류 메시지를 확인하여 외부 호출문이나 호출 변수 등을 수정한다.
-
3) 프로시저를 재호출한다. 근본적 해결이 되지 않았다면 방금 수정한 문제가 다 시 발생할 수 있다. 이런 경우 좀더 분석을 하고 내용을 확인하여 근본적 조 치를 취한다. 또한 발생했던 문제가 해결된다 하더라도, 다른 문제가 다시 발 생할 수도 있다. 메시지를 참조하여 프로시저를 수정하고 재컴파일하는 과정 을 반복한다.
-
-
-
[사용자 정의함수 및 호출쿼리 작성]
[1] 사용자 정의함수 작성
-
1. 사용자 정의함수의 개념
-
사용자 정의함수는 프로시저와 동일하게 절차형 SQL을 활용하여 일련의 연산 처리 결과 를 단일값으로 반환할 수 있는 절차형 SQL이다.
-
DBMS에서 제공되는 공통적 함수 이외에 사용자가 직접 정의하고 작성한다.
-
사용자 정의함수의 호출을 통해 실행되며, 반환되는 단일값을 조회 또는 삽입, 수정 작업에 이용하는 것이 일반적이다.
-
기본적인 개념 및 사용법, 문법 등은 상기 언급된 프로시저와 동일하며, 종료 시 단일값을 반환한다는 것이 프로시저와의 가장 큰 차이점이다.
-
-
2. 사용자 정의함수의 구성
-
기본적인 사항은 프로시저와 동일하고 반환에서의 부분만 프로시저와 다르다.
-

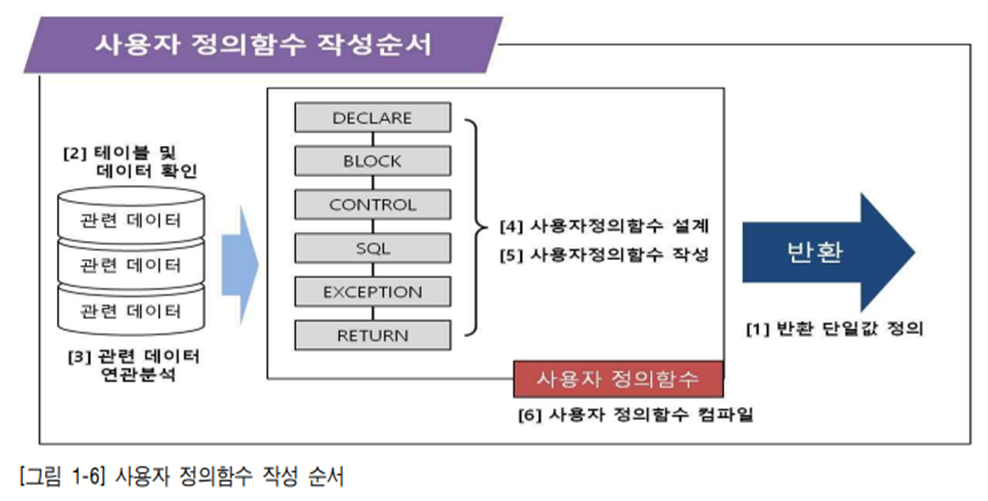
-
3. 사용자 정의함수의 문법
-
프로시저 문법과 유사하고, 위에서 언급한 바와 같이 결과를 리턴하는 부분이 차이가 있다.
-
CREATE 명령어로 DBMS 내에 사용자 정의함수 생성이 가능하다.
-
[OR REPLACE] 명령을 통해 기존 사용자 정의함수 존재 시에 현재 컴파일하는 내용으로 Overwrite할 수 있다. 만약, 기존 동명의 프로시저가 존재하고 CREATE 명령문만 사용하여 컴파일 시에는 에러가 발생한다.
-
RETURN 명령을 통해 사용자 정의함수 종료 시 사용자 정의함수를 호출한 쿼리에 반환하는 단일 값을 정의한다.
-
-

-
4. 사용자 정의함수의 예제
-
다음 사용자 정의함수는 생일을 입력 받아 나이를 출력하는 간단한 예시이다.
-
생년월일(V_BIRTH_DATE)을 입력변수로 선언한다.
-
현재 연도(V_CURRENT_YEAR) 변수와 생년(V_BIRTH_DATE) 변수를 문자열 4자리로 선언한다.
-
반환할 대상인 나이(V_AGE) 변수를 숫자 형식으로 선언한다.
-
현재 일자(SYSDATE)를 조회하고 연도 4자리만 파싱하여 현재 연도 변수에 입력한다.
-
생년월일 8자리에서 4자리만 파싱하여 생년 변수에 입력한다.
-
현재 연도와 생년을 숫자 형식으로 변환한 후 두 수의 차에 1을 더하고 나이 변수에 입 력한다.
-
구해진 나이값(한국 기준)을 반환한다.
-
-

[2] 사용자 정의함수 호출쿼리 작성
-
작성된 사용자 정의함수는 프로시저와 동일하게 외부에서의 호출을 통해 실행된다.
-
비교적 단순한 결과값을 구하는 것이 보통이며, 또는 타 시스템에 정보 제공 등 은닉을 통해 캡슐화를 제공하는 데에도 많이 사용된다.
-
1. 사용자 정의함수 호출쿼리 작성 문법 DQL 또는 DML 문장을 활용하여 사용자 정의함수를 호출한다.
-
직접 사용자 정의함수 결과값을 데이터 질의어에 활용하거나(첫번째 예제), 사용자 정의함 수 결과값을 데이터 조작어에 직접 적용하게 하여(두번째 예제) 활용 가능하다. 그 밖의 부분은 프로시저의 호출과 유사하다.
-
-
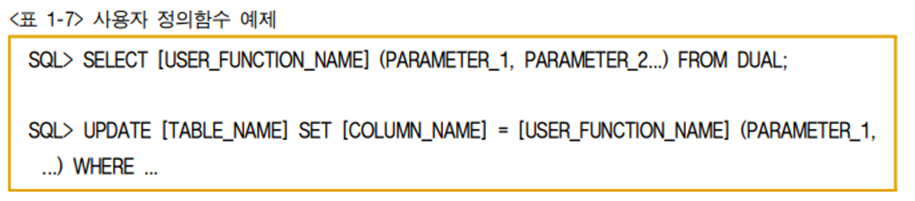
-
2. 사용자 정의함수 호출쿼리 작성
-
예제 위에서 제시된 사용자 정의함수를 호출하는 쿼리를 예시로 한다.
-
첫 번째 사용자 정의함수는 생년월일값(1990년 1월 1일)을 가지고 연령값을 가져오며, 두 번째 사용자 정의함수는 직원 아이디(EMPLOYEE_ID)값을 활용하여 생일(BIRTH_DATE) 컬럼 내의 값을 직접 활용하여 연령값에 수정한다.
-

[트리거 작성]
[1] 트리거 작성
-
1. 트리거의 개념
-
특정 테이블에 삽입, 수정, 삭제 등의 데이터 변경 이벤트가 발생하면 DBMS에서 자동적으로 실행되도록 구현된 프로그램을 트리거라고 한다.
-
이벤트는 전체 트랜잭션 대상과 각 행에 의해 발생되는 경우 모두를 포함할 수 있으며 테이블과 뷰(View), DB 작업을 대상으로 정의할 수 있다
-
-
2. 트리거의 목적
-
특정 테이블에 대한 데이터 변경을 시작점으로 설정하고, 그와 관련된 작업을 자동적으로 수행하기 위해 트리거를 사용한다.
-
일반적으로 이벤트와 관련된 테이블의 데이터 삽입, 추가, 삭제 작업을 DBMS가 자동적으로 실행시키는 데 활용되나, 데이터 무결성 유지 및 로그 메시지 출력 등의 별도 처리를 위해 트리거를 사용하기도 한다.
-
-
3. 트리거의 구성
-
앞에서 설명한 프로시저나 사용자 정의함수와 기본적 문법은 같다.
-
일반적인 트리거의 구성도는 [그림 1-7]과 같다.
-
반환이 없다는 점, DML을 주된 목적으로 한다는 점에서는 프로시저와 유사하나, EVENT 명령어를 통해 트리거 실행을 위한 이벤트를 인지한다는 점과 외부 변수 IN, OUT이 없다 는 점이 프로시저나 사용자 정의함수와 다르다.
-
-

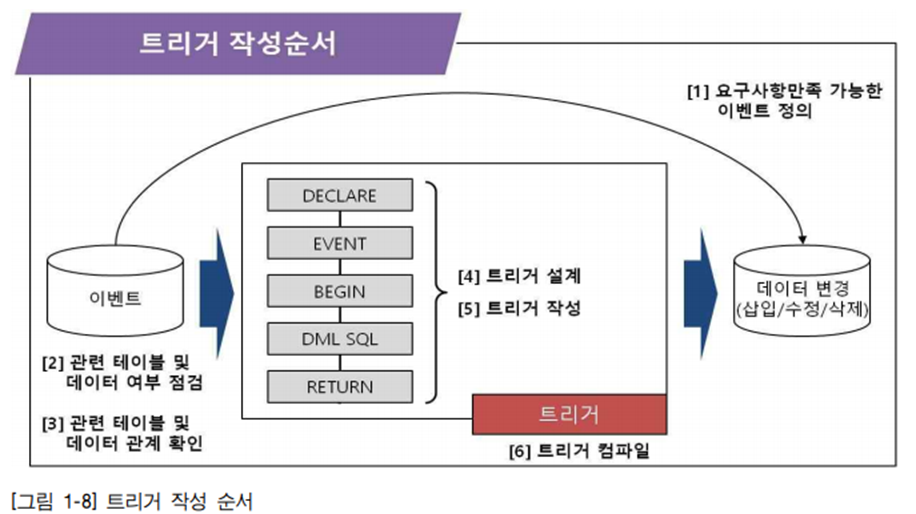
-
4. 트리거의 문법
-
위에서 나온 트리거의 구성을 기반으로 하는 트리거의 문법은 다음과 같다.
-
대상 테이블(TABLE_NAME)에 벌어진 이벤트 유형(TRANSACTION TYPE, INSERT / UPDATE / DELETE) 및 이벤트 순서(BEFORE / AFTER)에 맞게 트리거 수행을 위한 조건을 입력한다.
-
매번 변경되는 데이터 행의 수만큼 실행을 위한 명령어(FOR EACH ROW)를 정의하기도 한다.
-
트리거에는 레코드 구조체라는 개념이 존재하는데, 대상 테이블의 데이터 변경을 이벤트 로 처리하기 때문에 변경 전후의 데이터값을 각각 구분할 때 사용된다.
-
P언어에서는 :OLD, :NEW로 사용되며, T언어에서는 deleted와 inserted로 사용된다.
-
각각 이전․이후 데이터를 의미하며, INSERT 시에는 이전 값은 NULL, DELETE 시에는 이후 값이 NULL을 의미한다
-
-

-
5. 트리거 작성의 예제
-
다음은 직원 정보 변경 시 변경된 데이터를 이력 테이블에 적재하는 간단한 트리거의 예시이다.
-
직원 정보(EMPLOYEE_INFO_T) 테이블 수정 후(AFTER UPDATE) 실행된다.
-
직원 정보 이력(EMPLOYEE_INFO_H) 테이블에 데이터를 삽입(INSERT)한다.
-
기존 직원 ID(:OLD.EMPLOYEE_ID) 기준이며, 기타 직원 정보는 변경된 정보(:NEW.)를 삽입한다
-
-

-
6. 트리거 작성 시 주의 사항
-
(1) 데이터 제어어(DCL, Data Control Language) 사용 불가
-
트리거 내에는 COMMIT, ROLLBACK 등의 DCL을 사용할 수 없다. 쉽게 말하면 Auto Commit을 하는 결과와 같다고 할 수 있다.
-
트리거 내에 COMMIT이나 ROLLBACK을 사 용하고 컴파일하면 에러가 나는 것을 볼 수 있다.
-
여기서 하나 더 유의할 부분은 트리 거로 인해 발생하는 모든 후속 절차에도 동일하게 적용된다는 것이다.
-
트리거 내에서 타 프로시저를 호출하는 것도 가능한데, 해당 프로시저 내에 COMMIT이 포함되어 있 다면 이로 인해 오류가 유발된다.
-
-
(2) 오류에 특히 주의할 것
-
트리거 실행 중 오류가 발생하게 되면 트리거 실행의 원인을 제공한 데이터 작업에도 영향을 주는 경우가 많다.
-
즉, 특정 테이블에 데이터를 추가한 후 발생하는 트리거에 서 오류가 발생할 경우에는 트리거 이후의 작업이 진행되지 않는 것 뿐만 아니라, 더 나아가 데이터가 추가되지 않는다. 결국 트랜잭션을 합치는 과정에서 더 높은 무결성 및 품질을 요구한다고 볼 수 있으므로 이런 부분에서 주의를 요한다.
-
-
[연습문제]
-
절차형 SQL의 특징이 잘못된 것은?
-
(1) BEGIN/END의 Block화된 구조로 되어 있어 각 기능별로 모듈화가 가능하다.
-
(2) 조건문, 반복문 등 단일 SQL 문장으로는 실행하기 어려운 연속적인 작업을 처리하는 데에 적합하다.
-
(3) 일련의 작업에 필요한 데이터를 DBMS 내부에서 직접 처리하기 때문에 일반적으로 Input/Output Packet이 적다.
-
(4) 타 절차형 언어에 비해 작업의 효율성은 높은 편이다.
-
-
다음 중 코딩 규칙을 잘못 설명한것은?
-
(1) 소스 가독성을 높이기 위한 줄바꿈(Indentation)을 엄격히 적용한다.
-
(2) 내외부 변수 사용 시 변수 명명 방법을 준수하였는지 확인한다.
-
(3) 데이터사전(DD : Data Dictionary)을 사용하는 것이 일반적이며, 용어의 통일을 활용하여 혼동을 최소화하여 생산성 저하를 방지할 수 있다.
-
(4) 주석문을 가급적 적게 작성한다. 주요변수나 데이터 진행흐름, 로직 등을 설계 자나 작성자는 알 수 있지만 타 작업자는 쉽게 이해하지 못하는 경우가 대다수 이다. 이런 경우 가독성 증대를 위해 주석문을 적극 활용한다.
-
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'자기계발 > 자격증' 카테고리의 다른 글
| [자격증] 정보처리기사 실기 : 23강 소프트웨어 개발 보안 구축 (SW 개발 보안 설계하기) (0) | 2020.05.12 |
|---|---|
| [자격증] 정보처리기사 실기 : 22강 SQL 응용 (응용 SQL 작성하기) (0) | 2020.05.12 |
| [자격증] 정보처리기사 실기 : 20강 애플리케이션 테스트 관리 (애플리케이션 성능 개선하기) (0) | 2020.05.11 |
| [자격증] 정보처리기사 실기 : 19강 애플리케이션 테스트 관리 (애플리케이션 통합 테스트하기) (0) | 2020.05.11 |
| [자격증] 정보처리기사 실기 : 18강 애플리케이션 테스트 관리 (애플리케이션 테스트케이스 설계하기) (0) | 2020.05.10 |