

정보
-
업무명 : 선형 회귀 : 다중 회귀 분석
-
작성자 : 박진만
-
작성일 : 2020-04-19
-
설 명 :
-
수정이력 :
내용
[개요]

[특징]
-
통계이론 설명
[활용 자료]
-
없음
[자료 처리 방안 및 활용 분석 기법]
-
없음
[사용법]
-
내용 참조
상세 내용
[다중 회귀 분석]
-
회귀 분석은 원인과 결과 또는 결과와 결과 간의 양적 관계를 확인하는 분석 방법 중 하나이다.
-
예를 들어, 옥신은 식물 줄기의 키 및 성장을 촉진하는 물질로 알려져 있다. 이 때 식물에 주어진 옥신 농도가 높을수록 줄기의 키 성장률이 높아진다.
-
따라서, 키의 성장률의 결과는 옥신 농도의 원인으로 설명 될 수 있다.
-
여기서 y가 성장 속도이고 x가 옥신 농도 인 경우, y 및 x는 다음 선형 회귀 방정식으로 표현할 수 있다.
-
위 회귀 방정식에서 x를 독립 변수 (또는 설명 변수)라고하고 y를 종속 변수 (또는 목적 변수)라고 할 수 있다.

-
그러나 결과가 단 하나의 원인에 의해 영향을 받는 단순한 경우 이외에, 결과가 여러 원인에 의해 영향을 받는 복잡한 경우 또한 있을 수 있다.
-
예를 들어, 벚꽃의 개화 날짜는 온도, 강수량 및 태양 복사와 같은 다양한 요인의 영향을 받는 것으로 간주된다.
-
따라서 여러 원인이 존재하는 경우에 대해서는 여러 독립 변수 x1, x2, ..를 준비하고 하나의 종속 변수 y를 설명하는 회귀 방정식을 공식화 하여야 한다.

-
여기서 등장 하는것이 다중회귀 분석이다.
-
다중 회귀 분석은 하나의 결과를 여러 원인으로 설명하기 위한 분석 방법이다.
-
즉 회귀 방정식을 기반으로 여러 원인 x를 사용하여 하나의 결과 y를 설명하는 방법이다.
-
따라서 회귀 방정식의 각 계수를 결정해야 할 필요가 있다.
-
이 계수를 결정하는 방법인 최소 제곱법은 회귀 방정식의 계수를 결정하는데 사용된다.
-
간단한 회귀 분석과 마찬가지로, 회귀 방정식을 사용하여 "회귀 모델 방정식으로 계산 한 y의 추정값"과 "실제로 관측 된 y의 관측 값" 사이의 오차 e를 최소화하는 방법이 사용되어, 각 계수를 결정하게 된다.
[다중 회귀 분석의 최소제곱법]
-
이제 n 개의 독립 변수를 갖는 하나의 종속 변수를 설명하는 모델을 고려해보자.
-
이때, i 번째 데이터 세트 (종속 변수 yi; 독립 변수 xi1, xi2, ..., xin)에 초점을 맞출 때, 관찰 값과 추정값 사이의 오차 ei는 다음과 같이 계산 될 수 있다.

-
여기서 ei는 양수 값과 음수값이 모두 출현하게 될 수 있다.
-
따라서 i = 1, 2, 3, ... 인 경우 오차의 합계를 찾는 것이 어렵다.
-
따라서 이 오차를 그대로 사용하는 대신 제곱 한 후에 사용하게 된다.
-
이때 모든 오류를 동시에 최소화하는 것은 그 합계를 최소화하는 것과 같다.
-
따라서 오차의 제곱의 합 Se를 고려하면 아래와 같다.

-
여기서 Se가 최소가되도록 계수 βk (k = 0,1, ..., n)을 구하기 위해서는, Se를 βk (k = 0,1, ..., n)의 다변량 함수로 간주하고 각 βk (k = 0,1, ..., n)로 편미분하여 Se가 최소가되는 βk (k = 0,1, ..., n)을 구하면 된다.
[최소 제곱 행렬 계산]
-
이제 종속 변수로 구성된 벡터를 Y로 놓는다.
-
또한 독립 변수를 X로 회귀 계수로 이루어진 벡터를 β로 놓는다.
-
이때 회귀 모형은 다음 식으로 쓰여질 수 있다.

-
이 때, 오차 제곱 합은 다음과 같이 구할 수 있다.
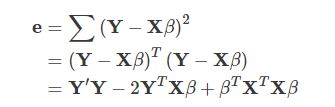
-
위의 식에 열 벡터 β로 편미분하여 열 벡터 e가 최소가되는 열 벡터 β를 구한다.

-
여기서 만약 행렬 X'X가 역행렬을 가지면 좌우로 \(X^{\top} X\)의 역행렬을 곱해서 열 벡터 β를 구할 수 있다.

-
여러 설명 변수간의 높은 상관 관계가 있는 경우 \(X^{\top} X\)에 역행렬이 존재하지 않을 수 있다.
-
이 경우, 작은 노이즈에 해당하는 λI를 \(X^{\top} X\)에 추가하여 (\(X^{\top} X\)+ λI)의 역행렬을 찾아 회귀 계수를 구하는 방법이 있다.
-
이것을 릿지 (Ridge) 회귀라고 한다.
[독립 변수의 선택]
-
독립 변수 x는 데이터로 존재하는 경우, 모든 모델에 통합 할 수 있다.
-
그러나 서로간의 상관이 높은 독립 변수를 모델 식에 통합해서 공선으로 인한 X'X의 역행렬을 계산할 수 없거나 모델이 독립 변수에 과도하게 적합해 버리는 위험성이 생긴다.
-
이러한 위험을 억제하는 모델을 만들 때 데이터에 포함 된 독립 변수를 모든 모델에 통합하는 것이 아니라 종속 변수를 설명하는 데 중요한 독립 변수 만 모델에 포함해야 할 필요가 있다.
-
중요한 독립 변수를 선택하는 방법에는 아래와 같은 방법이있다.
-
실험 계획 단계에서 이미 중요하다고 생각되는 요인 (요인)을 독립 변수로 선택한다.
-
생각할 수있는 모든 요인의 전체 조합을 이용하여 회귀 분석을 실시하여 각각의 분석 결과에 대한 평가 지표 (AIC, Cp 통계 등)를 사용하여 평가하고 가장 좋았던 조합을 이용한다.
-
모든 요인 각각에 대해 전적으로 회귀 식에 대입하여 분석을 실시하여 가장 결과가 좋은 조합을 본다. 그런 다음이 독립 변수와 나머지 독립 변수 하나를 선택하여, 2 개의 독립 변수로 회귀 분석을 실시한다. 계속하여 3 개의 독립 변수로 회귀 분석을 실시하고 4 개의 독립 변수로 회귀 분석을 실시... 처럼 결과가 개선 될 때까지를 순차적으로 독립 변수를 늘려 나가는 방법이다.
-
처음으로 모든 독립 변수를 회귀 식에 대입하여 분석을 실시한다. 다음으로 독립 변수를 하나 제거하고 회귀 모델을 작성하고 적합성을 조사한다. 그리고가장 개선 된 모델을 찾아 모델에서 더 또 다른 독립 변수를 줄이고, 적합성을 조사한다. 이러한 작업을 결과가 개선되지 않을 때까지 순차적으로 독립 변수를 줄여 나간다.
-
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'통계 이론' 카테고리의 다른 글
| [통계 이론] 선형 회귀 : 로그 우도 함수의 최대 우도 (가능도) 추정 (0) | 2020.04.19 |
|---|---|
| [통계 이론] 선형 회귀 : 오차구조 (error structure), 연결 함수 (link function), 선형 예측 (linar predictor) (0) | 2020.04.19 |
| [통계 이론] 선형 회귀 : 단일 회귀 분석 (0) | 2020.04.19 |
| [통계 이론] 베이지안 통계학: 사전 분포 (0) | 2020.04.18 |
| [통계 이론] 베이지안 통계학: 사후 분포 (0) | 2020.04.18 |