
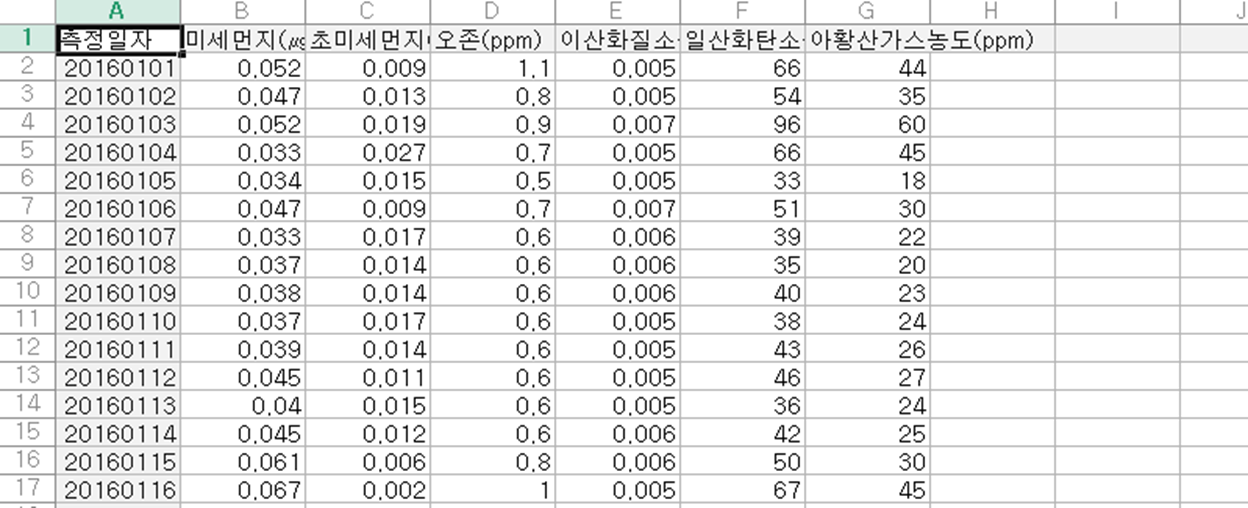
정보
- 업무명 : 데이터분석 준전문가 (ADsP) Ⅰ 데이터 이해 : 01~15강
- 작성자 : 이상호
- 작성일 : 2024.06.15
- 설 명 :
- 수정이력 :
주요 목차
- 01강 목록 및 강의 계획
- 02강Ⅰ-1-1 데이터의 개념
- 03강Ⅰ-1-1 데이터의 개념2
- 04강Ⅰ-1-2 데이터베이스의 개념
- 05강Ⅰ-1-3 데이터베이스의 활용
- 06강Ⅰ-1-3 데이터베이스의 활용2
- 07강Ⅰ-2-1 빅데이터의 개념
- 08강Ⅰ-2-1 빅데이터의 개념2
- 09강Ⅰ-2-2 비즈니스 모델
- 10강Ⅰ-2-3 빅데이터의 문제점과 해결방안
- 11강Ⅰ-3-1 데이터 사이언스란
- 12강Ⅰ-4-1 DBMS와 SQL
- 13강Ⅰ-4-2 데이터에 관련된 기술
- 14강Ⅰ-4-3 빅데이터 분석기술
- 15강Ⅰ-4-4 데이터 관한 기타 내용
01강 목록 및 강의 계획
[데이터 분석 준전문가 자격증 과목 소개]
| 구분 | 시험과목 | 과목별 세부항목 | 비고 |
| 1과목 | 데이터의 이해 |
1.데이터의 이해
2.데이터의 가치와 미래
3.가치 창조를 위한 데이터사이언스와 전략 인사이트
|
|
| 2과목 | 데이터 분석 기획 |
1.데이터 분석 기획의 이해
2.분석 마스터 플랜
|
|
| 3과목 | 데이터 분석 |
1.R기초와 데이터 마트
2.통계분석
3.정형 데이터 마이닝
|
[데이터 분석 준전문가 시험안내]
- 총점 60점 이상시에 자격증 취득
- 과목별 40% 미만 취득시 과락
- 응시료 50,000원
| 구분 | 시험과목 | 문항수 | 배점 | 시험시간 |
필기 |
객관식 | 객관식 | 90분 (1시간30분) |
|
| 1. 데이터의 이해 | 10 | 100 (각 2점) |
||
| 2. 데이터분석 기획 | 10 | |||
| 3. 데이터분석 | 30 | |||
| 계 | 50 | 100 |
[데이터 분석 준전문가 시험 일정]

02강Ⅰ-1-1 데이터의 개념
(1) 데이터의 정의
- ① 데이터라는 용어는 1646년 영국의 문헌에서 처음 등장, 라틴어 dare(주다)의 과거 분사형으로 ‘주어진 것’ 이란 의미로 사용
- ② 데이터는 추론과 추정의 근거를 이루는 사실
(2) 데이터의 분류
- ① 일차데이터(primary data)
- 연구조사자에 의하여 직접 수집된 데이터를 말합니다.
- 조사연구, 실험과 관측연구는 가장 널리 쓰이는 일차데이터 수집방법입니다.
- ② 이차데이터(secondary data)
- 연구조사자의 문제와는 다른 목적으로 다른 사람에 의하여 수집된 데이터입니다.
- 이차데이터는 데이터를 수집한 사람이 연구조사자와 같은 기관에 있는 사람인가 아닌가에 따라 다시 내부 또는 외부 데이터로 나눕니다.
(3) 데이터 웨어하우스(data warehouse)
- 데이터 사이의 관계나 패턴을 확인하는 세밀한 분석을 할 수 있도록, 기업 내부와 외부의 모든 데이터를 정리하여 저장하는 데이터 저장소이다.
(4) 데이터 마이닝(data mining)
- 분석적 기법을 적용하는 과정을 데이터 마이닝이라고 합니다.
- 기술통계, 교차제표, 회귀분석, 상관관계 등이 데이터 채집 도구로써 사용되는 상태입니다.
- 그 외 다양한 기법
- 인자분석(factor analysis)
- 군집분석(cluster analysis)
- 판별분석(discriminant analysis)
- 다차원척도법(multidimensional scaling)
03강Ⅰ-1-1 데이터의 개념2
(2) 데이터의 분류
- ① 일차데이터(primary data)
- 일차 데이터(primary data)는 연구조사자에 의하여 직접 수집된 데이터를 말합니다.
- 조사연구, 실험과 관측연구는 가장 널리 쓰이는 일차데이터 수집방법입니다.
- 내가 측정 장비 (온도계 등)로부터 직접 수집한 데이터를 사용
- ② 이차데이터(secondary data)
- 이차데이터는 연구조사자의 문제와는 다른 목적으로 다른 사람에 의하여 수집된 데이터입니다.
- 이차데이터는 데이터를 수집한 사람이 연구조사자와 같은 기관에 있는 사람인가 아닌가에 따라 다시 내부 또는 외부 데이터로 나눕니다.
- 동일 회사 내 내부 사람이 수집한 데이터를 사용
- 다른 회사 내 외부 사람이 수집한 데이터를 사용

(3) 데이터의 특성
- ① 존재적 특성 : 객관적인 사실로서의 의미를 가진다.
- 2024년 02월 17일 10시 0분 0초 인천 송도의 온도는 10도이다.
- 측정 장비 (온도계)를 통해 직접 측정하여 사실이 실제로 존재
- ② 당위적 특성 : 추론, 예측, 추정의 근거를 가진다.
- 현재의 기상 조건과 과거 데이터를 바탕으로 내일 인천 송도의 평균 온도는 15도 예상된다.
- 단순한 사실을 넘어서 미래 가능성에 대한 근거를 제공 ]
(4) 데이터의 유형
| 구분 | 형태 | 예 | 특징 |
| 정성적 데이터 | 언어, 문자 등 | 회사의 매출이 증가 | 비용 소모가 큼 주관적 내용 비정형 데이터 |
| 정량적 데이터 | 수치, 도형, 기호 등 | 나이, 몸무게, 주가 등 | 비용 소모가 작음 객관적 내용 정형 데이터 |
04강Ⅰ-1-2 데이터베이스의 개념
데이터베이스의 정의
- 데이터베이스 (영어: DataBase, DB)는 여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합이다.
- 작성된 목록으로써 여러 응용 시스템들의 통합된 정보들을 저장하여 운영할 수 있는 공용 데이터들의 묶음이다.
- 예를 들면 다음과 같은 정보가 데이터베이스에 기록됨
- 카카오톡 메시지
- 인스타그램에 등록한 사진
- 버스/지하철에서 찍은 교통카드
- 카페에서 구매한 커피 영수증
…
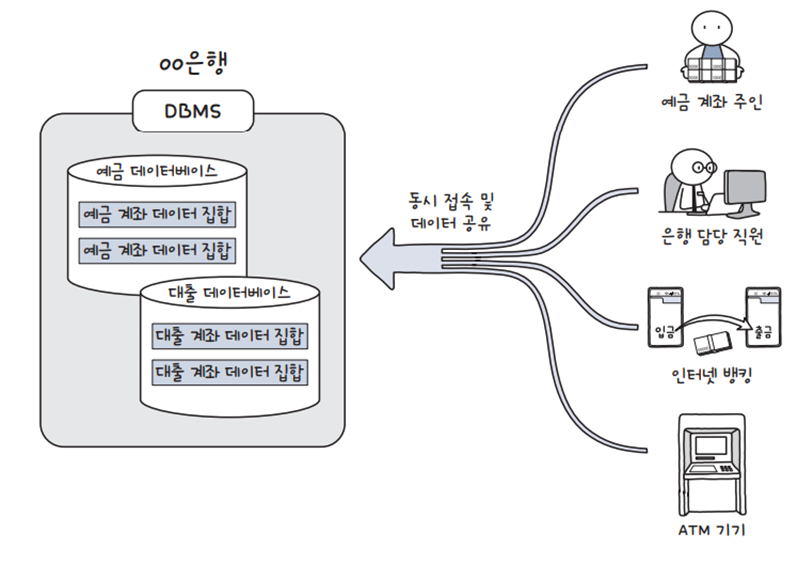
- 데이터베이스 관리 시스템 (DBMS): 데이터베이스를 운영하고 관리하는 소프트웨어
- 예를 들면 은행에서 예금/대출 등의 데이터베이스를 통해 다양한 방법 (자신, 은행 직원, 인터넷 뱅킹, ATM)으로 동시 접근 및 데이터 공유 가능
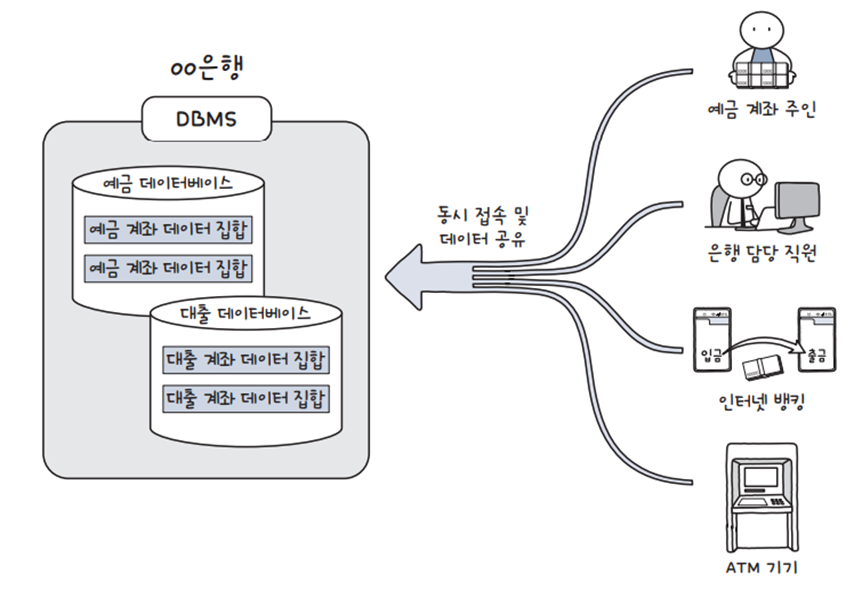
| DBMS | 제작사 | 작동 운영체제 | 기타 |
| MySQL | Oracle | Unix, Linux, Windows, Mac | 오픈 소스(무료), 상용 |
| MariaDB | MariaDB | Unix, Linux, Windows | 오픈 소스(무료), MySQL 초기 개발자들이 제작 |
| PostgreSQL | PostgreSQL | Unix, Linux, Windows, Mac | 오픈 소스(무료) |
| Oracle | Oracle | Unix, Linux, Windows | 상용 시장 점유율 1위 |
| SQL Server | Microsoft | Windows | 주로 중/대형급 시장에서 사용 |
| DB2 | IBM | Unix, Linux, Windows | 메인프레임 시장 점유율 1위 |
| Access | Microsoft | Windows | PC용 |
| SQLite | SQLite | Android, iOS | 모바일 전용, 오픈 소스(무료) |
(1) 데이터베이스의 정의
| 분류 | 내용 |
| 1차 개념 확대 (정형 데이터 관리) |
소재를 체계적으로 배열 또는 구성한 편집물로서 개별적으로 그 소재에 접근하거나 그 소재를 검색할 수 있도록 한것 숫자, 문자 등이 명확하게 정의, 구조화된 형태를 지님
|
| 2차 개념 확대 (빅데이터의 출현으로 비정형데이터 포함) |
문자, 기호, 음성, 화상, 영상 등 상호 관련 된 다수의 콘텐츠를 정보 처리 및 정보 통신 기기에 의하여 체계적으로 수집, 축적하여 다양한 용도와 방법으로 이용할 수 있도록 정리한 정보의 집합체 1차 개념 확대에서와 달리 다양한 형태 (문서, 이미지, 비디오, 이메일 등) 존재
|
(2) 데이터베이스의 특성
- ① 통합된 데이터: 이는 중복된 데이터가 존재하지 않는 것을 말합니다.
고객이 여러 개의 계좌를 가지고 있더라도 각 계좌 정보는 고유한 계좌 번호를 통해 식별되며, 고객의 개인 정보는 중복되지 않게 연결 - ② 저장된 데이터: 컴퓨터가 접근할 수 있는 자기 디스크나 자기 테이프와 같은 저장 매체에 저장되는 것
은행 시스템에 의해 언제든지 접근할 수 있으며, 고객이 온라인 뱅킹을 통해 계좌 이체를 요청할 때 신속하게 처리 - ③ 공용 데이터: 여러 사용자가 서로 다른 목적으로 데이터를 공동으로 이용하는 것
고객이 계좌 이체를 할 때, 은행 직원, 온라인 뱅킹 시스템, 모바일 앱 등 다양한 접점에서 동일한 데이터에 접근 가능 - ④ 변화되는 데이터: 기존 데이터의 삭제 및 갱신으로 변화하면서도 현재의 정확한 데이터를 유지
한 고객이 다른 고객에게 돈을 이체하면, 송금하는 고객의 계좌에서는 해당 금액만큼 차감되고, 수령인의 계좌에는 그 금액이 추가
(3) 데이터베이스의 장단점
- ① 데이터베이스 장점
- 데이터 중복 최소화
- 데이터 공유
- 일관성, 무결성, 보안성 유지
- 최신의 데이터 유지
- 데이터의 표준화 가능
- 데이터의 논리적, 물리적 독립성, 용이한 데이터 접근
- 데이터 저장 공간 절약
- ② 데이터베이스 단점
- 데이터베이스 전문가 필요
- 많은 비용 부담
- 데이터 백업과 복구가 어려움
- 시스템의 복잡함
- 대용량 디스크로 접근이 집중되면 과부하 발생
05강Ⅰ-1-3 데이터베이스의 활용
(1) 기업관련 데이터베이스
- ① 1980년대
- (ⅰ) OLTP(On-line Transaction Processing)
- 호스트 컴퓨터가 데이터베이스를 액세스하고, 바로 처리 결과를 돌려주는 형태이다.
- 그러므로 데이터베이스의 데이터를 수시로 갱신하는 상태를 가지게 된다.
- 특징: 실시간 처리, 실시간 갱신
- 대상: 일반 사용자
사례: 은행 거래, 온라인 쇼핑, 예약 시스템 등 일상적인 거래 처리
- (ⅱ) OLAP(On-line Analytical Processing)
- 다양한 비즈니스 관점에서 쉽고 빠르게 다차원적인 데이터에 접근하여 의사 결정에 활용할 수 있는 정보를 얻을 수 있게 해주는 형태이다.
- 특징: 다차원적 데이터 분석, 의사결정지원
- 대상: 데이터 분석가, 경영진과 같은 의사 결정자
- 사례: 재고 관리, 재무 분석, 시장 연구 등에서 전략 수집
- (ⅰ) OLTP(On-line Transaction Processing)
- ② 2000년대
- (ⅰ) CRM(Customer Relationship Management)
- 일명 ‘고객 관계 관리’라고 하며 기업이 고객과 관련된 내,외부 자료를 분석, 통합하여 고객 중심 자원을 극대화하고, 이를 토대로 고객특성에 맞게 마케팅 활동을 계획, 지원, 평가하는 과정을 말한다.
- 특징: 고객 중심의 데이터 관리, 개인 맞춤형 마켓팅, 고객 서비스 개선
- 대상: 소비자, 기업
- 사례:
- 아마존: 고객의 구매 이력과 검색 이력을 분석하여 개인 맞춤형 상품 추천
- 스타벅스: 모바일 앱을 통해 고객의 주문 이력을 관리하고, 맞춤형 쿠폰을 제공 서비스
- (ⅱ) SCM(Supply Chain Management)
- 일명 ‘ 공급망 관리’라고 하며 기업에서 원재료의 생산, 유통 등 모든 공급망 단계를 최적화하여 수요자가 원하는 제품을 원하는 시간과 장소에 제공하는 것을 말한다.
- 특징: 공급망 최적화, 재고관리, 수요 예측
- 대상: 제조업, 유통업
- 사례:
- 월마트: 고도의 SCM 시스템을 통해 재고를 최적화하고, 물류 비용을 절감하여 낮은 가격으로 상품을 제공
- 자라: 신속한 패션 트렌드 반영을 위해 공급망을 통한 빠른 디자인, 생산, 배송 시스템을 구축하여 경쟁 우위를 확보
- (ⅰ) CRM(Customer Relationship Management)
- ③ 분야별 데이터베이스
| 분야 | 내용 |
| 제조 분야 |
ERP(Enterprise Resource Planning): 경영자원을 하나의 통합 시스템으로 재구축
BI(Business Intelligence): 의사 결정에 활용하는 비즈니스 프로세스
CRM(Customer Relationship Management): 고객관계관리이라고 하며 고객 중심 자원을 극대화하여 고객 특성에 맞게 마케팅 활동을 계획, 지원, 평가하는 과정이다.
RTE(Real-Time Enterprise): 회사의 주요 경영정보를 통합관리하는 실시간 기업의 시스템
|
| 금융 분야 |
EAI(Enterprise Application Integration): 정보를 중앙 집중적으로 통합, 관리, 사용할 수 있는 환경 구현
EDW(Enterprise Data Warehouse): 기존 데이터 웨어하우스의 확장된 버전
|
[12회 기출문제]
다음 중 기업내부 데이터베이스인 고객관계관리(CRM)에 대한 설명으로 적절한 것은 무엇인가?
① 부품의 설계, 제조, 유통 등의 공정포함
② 외부 공급업체와의 정보시스템 통합으로 시간과 비용 최적화
③ 기업의 내부 고객들만을 대상으로 한 정보시스템
④ 단순한 정보의 수집에서 탈피, 분석 중심의 시스템 구축 지향
[19회 기출문제]
아래는 데이터베이스를 기반으로 기업 내 구축되는 주요 정보시스템 중 하나를 설명한 것이다. 보기에서 가장 적절한 것을 고르면?
| 기업 전체를 경영자원의 효과적 이용이라는 관점에서 통합적으로 관리하고 경영의 효율화를 기하기 위한 시스템 |
① ERP
② CRM
③ SCM
④ KMS
06강Ⅰ-1-3 데이터베이스의 활용2
(2) 사회기반구조 관련 데이터베이스
① 개념
- 사회 각 부문의 정보화가 본격화되면서 데이터베이스 구축이 활발히 추진
- 정부를 중심으로 무역, 통관, 물류, 조세, 국세, 조달 등 사회간접자본 차원에서 정보망 구축
- 주요 장점
- 사회기반구조의 문제점을 파악하고 개선하여 더 나은 사회를 만듬
- 다양한 서비스를 제공하여 우리 삶을 더욱 편리함
- 새로운 사업을 창출하고 경제 발전에 기여
② 분류
- (ⅰ) EDI(electronic data interchange)
- 무역에 필요한 각종 서류를 표준화된 양식을 통해 컴퓨터통신망을 이용하여 거래처에 전송하는 시스템 친구에게 편지를 보내는 기능과 유사함
- 즉 서류를 전자 파일로 변환해서 빠르고 정확하게 전송
- (ⅱ) VAN(Value Added Network)
- 부가가치통신망이라 부르며 공중 전기통신사업자로부터 통신회선을 차용하여 독자적인 네트워크를 형성하는 서비스
- 인터넷보다 더 안전하고 빠르게 정보를 주고받을 수 있는 특별한 네트워크 공간
- (ⅲ) CALS(Commerce At Light Speed)
- 전자상거래 구축을 위해 기업 내에서 비용 절감과 생산성 향상을 추구할 목적으로 시작한 서비스
- 제품의 라이프 사이클 전반에 관련된 데이터를 통합하고 공유, 교환할 수 있도록 한 경영통합정보 시스템
- 제품 생산 과정에서 필요한 모든 정보를 하나의 시스템에 담아 관리하는 시스템
③ 분야별 데이터베이스
| 분야 | 내용 | 설명 |
| 물류 | CVO(Commercial Vehicle Operation System) 화물운송정보 | 트럭의 위치, 운행 경로, 화물 정보 등을 알려주는 시스템 |
| PORT-MIS 항만운영정보시스템 | 배의 입출항 정보, 화물 처리 정보 등 항만 운영 정보를 관리하는 시스템 | |
| KROIS 철도운영정보시스템 | 열차의 운행 시간, 노선, 지연 상황 등 철도 운영 정보를 알려주는 시스템 | |
| LIS (Logistics Information System) 물류 정보 시스템 | 물류 관련 정보를 수집, 저장, 처리, 분석하는 시스템 | |
| 지리 | GIS(Geographic information System) 지리정보시스템 | 도로, 건물, 산, 강 등 지리 정보를 보여주는 시스템 |
| RS(Remote Sensing) 원격탐사 | 위성 사진으로 지구 표면을 관찰하고 변화를 파악하는 시스템 | |
| 의료 | UH(Ubiquitous-Health) | 건강 정보를 관리하고 질병 예방 및 건강 증진을 돕는 시스템 |
| 교육 | NEIS(National Education Information System) 교육행정정보시스템 | 학생 정보, 교사 정보, 교육 과정 등 교육 관련 정보를 관리하는 시스템 |
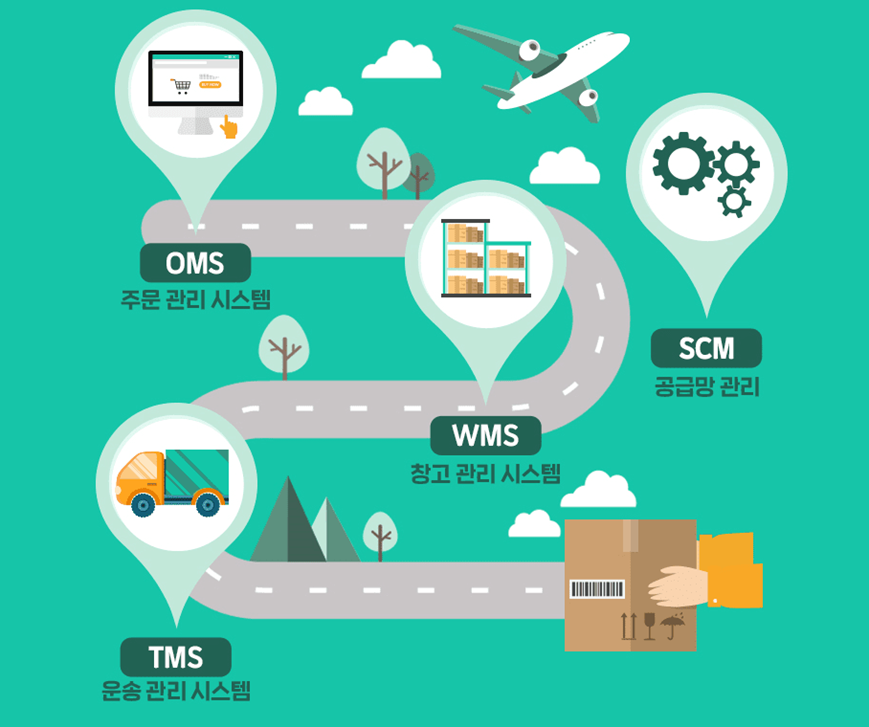
④ LIS (Logistics Information System) 물류 정보 시스템
- 물류의 과정을 시스템화 또는 전산화하여 운송, 보관, 포장 등 전반적인 물류과정이 효율적으로 관리될 수 있도록 만들어진 정보 처리 시스템
물류 비용을 절감시키고 물류 서비스 품질 향상을 목표
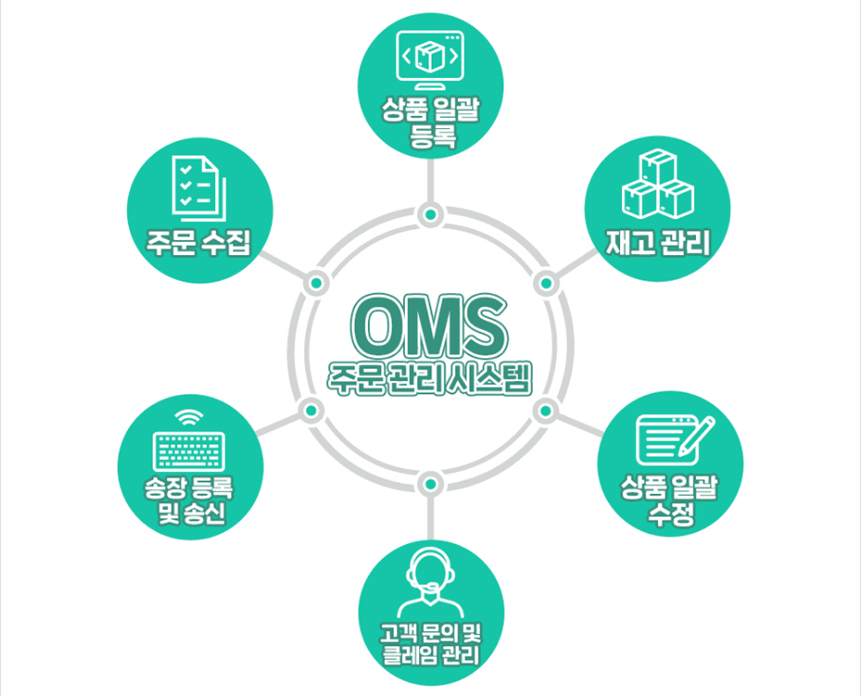
- 물류의 첫 단계인 주문내역, 결제확인, 주문취소, 반품 등 소비자의 주문을 관리하고 통합적으로 처리하는 주문 관리
- 판매자는 OMS에 기록된 데이터를 바탕으로 상품의 재고 파악, 입고 예정일 등을 쉽게 확인할 수 있으며, 다수의 채널을 운영하는 대상에게 적합한 시스템
- ① 예측 가능한 재고관리 및 재고파악의 용이
- ② 업무 시간 단축 및 효율성 증대
- ③ 고객의 소비패턴 파악과 고수요 제품 확인
- ④ 고객의 주요 데이터 활용
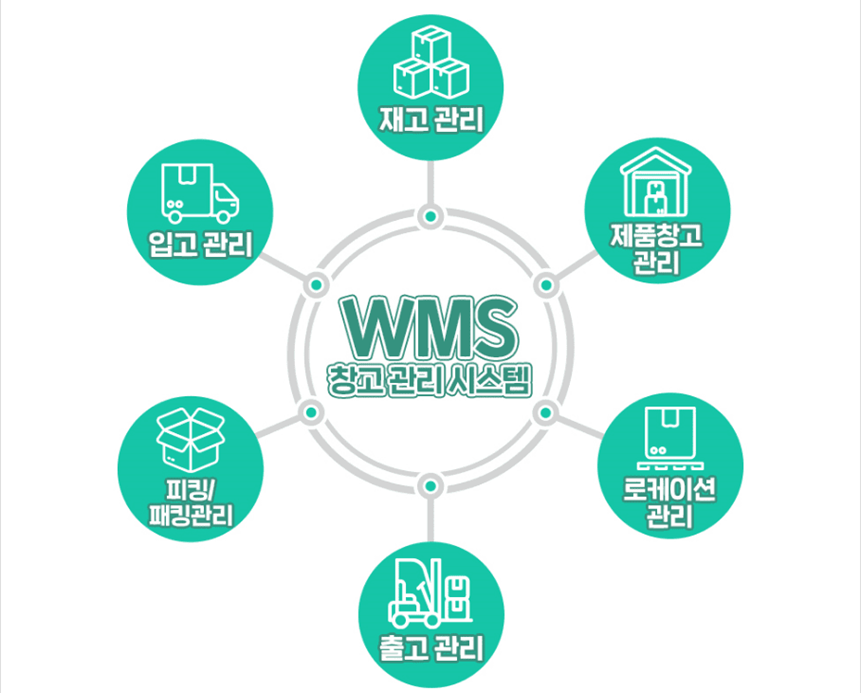
- 배송 센터 또는 자재∙재고 창고 내에서 물류 및 자재∙재고를 관리하면서 발생하는 모든 활동을 관리하는 창고 통합 관리 시스템
- 입고, 적치, 재고, 피킹, 출고 등을 통합 관리하여 고객 기업의 물류 관리 및 운영 능력을 향상
- ① 적정한 인원계획 수립 가능
- ② 창고공간의 효율적인 관리
- ③ 노동 생산성의 향상
- ④ 자재에 대한 실시간 정보 제공
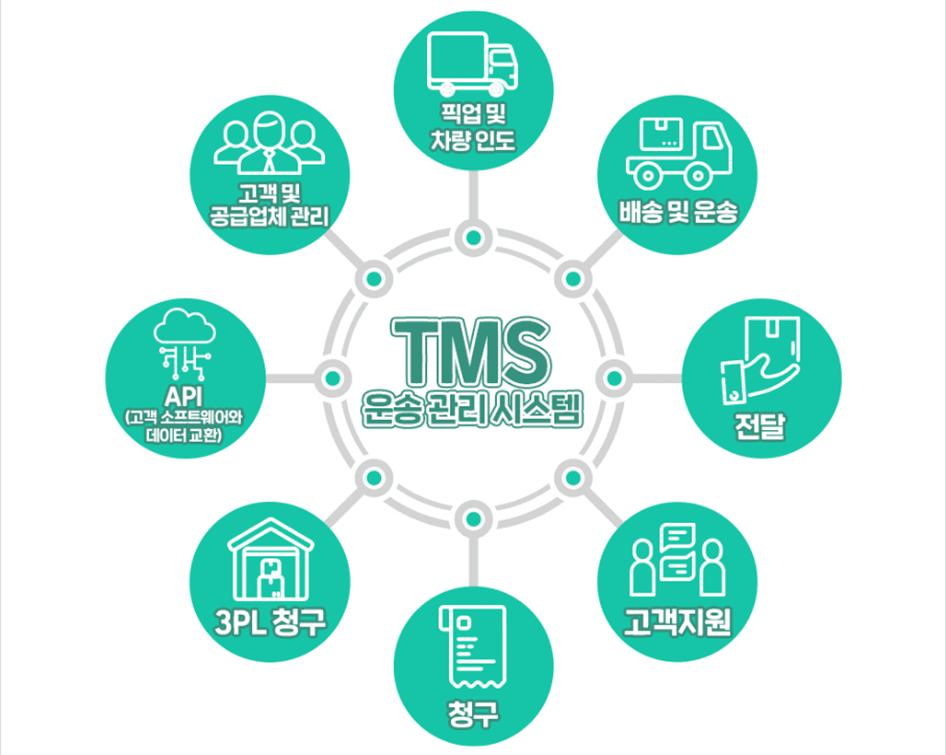
- 제품을 배송하여 고객에게 전달되는 운송 수단을 배정하고 그 운송 일정을 계획, 관리하여 최종적으로는 성과/지표를 전반적으로 관리하는 시스템
- 운송 계획을 수립하고 실행하여 물류 프로세스의 최적화를 지원
- ① 운송비 절감 기회 분석 가능
- ② 물류 적재율 향상
- ③ 물류 프로세스 최적화
- ④ 탄소 배출 감소
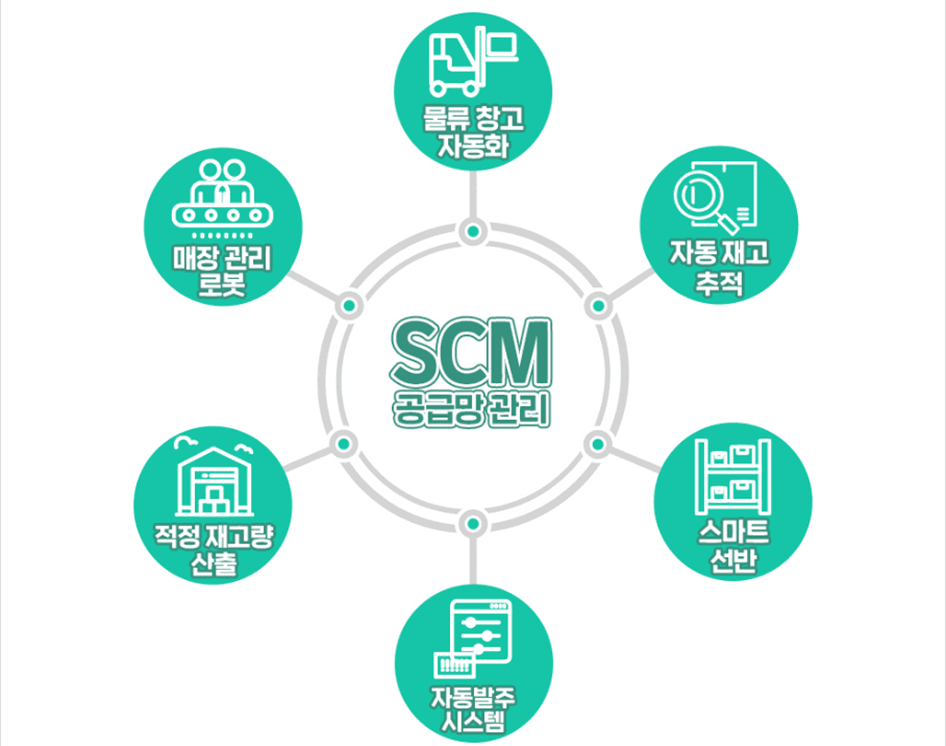
- 공급망 관리로, 제품 생산을 위한 원재료 구매부터 최종 소비자까지 전체적인 물류 프로세스를 하나의 통합망으로 관리하는 경영전략시스템
- 단순한 물류 관리만이 아닌, 소비자의 만족도를 위한 높은 효율성을 높임
- ① 체계화된 물류 시스템 구축
- ② 소비자의 만족도 극대화
- ③ 기업의 경쟁력 강화
- ④ 물류비용 절감
[13회 기출문제]
다음 중 사회기반 구조로서의 데이터베이스에 대한 설명으로 가장 부적절한 것은?
① 물류, 무역, 조세 등 사회간접자본 차원에서 정보망을 통해 유통, 이용된 정보가 데이터베이스로 구축
② 지리, 교통 부문에서 데이터베이스가 보다 고도화되어 데이터베이스를 구축
③ 인터넷의 보편화로 데이터베이스가 사회 전반의 인프라로 자리매김
④ 의료, 교육, 행정 부분에서는 데이터베이스 구축과 활용이 활성화되지 못함
07강Ⅰ-2-1 빅데이터의 개념
(1) 빅데이터의 정의
① 가트너 그룹(Gartner Group)의 더그 래니(Doug Laney) 최초 제안
| 3V | ||
| 양/규모 (Volume) | 다양성(Variety) | 속도(Velocity) |
| 센서 측정 데이터, 비정형 데이터 | 영상, 사진 등 | 원하는 데이터의 추출 및 분석속도 |

② 정의
- (좁은 의미) 3V로 요약되는 데이터 자체
- (중간 의미) 데이터 자체뿐 아니라 처리, 분석 기술적 변화 또한 빅데이터로 정의
- (넓은 의미) 인재, 조직 변화까지 포함하여 빅데이터를 정의
(2) 빅데이터의 출현배경
- (산업계) 고객 데이터를 축적하여 보유하여 데이터의 숨어있는 가치를 발굴하고 출현
- 쿠팡에서 물건 구매 시 회원정보 필요 데이터 수집/축적/적재 자주 구매한 상품, 연관 상품 (고기-쌈장-채소 등)
- (학계) 거대 데이터를 다루는 학문 분야가 늘어나면서 기술 아키텍처 및 통계 도구 발전
- 목표: 내일 온도 예측
- 과거: 사람에 의해 수작업으로 온도 측정/기록 예보관에 의해 추론
- 현재: 측정 장비에 의해 자동화 측정/기록 슈퍼컴퓨팅 및 통계 기술에 의해 예측
- (기술발전) 디지털화, 저장 기술의 발달, 인터넷의 보급 등의 기술 발전
- 과거: 편지, 사진 촬영 시 종이 보관
- 현재: 이메일, USB 외장하드 등의 전자 문서 > 클라우드 활용 (구글 드라이브 등)
(3) 빅데이터의 기능
| 구분 | 설명 |
| 사전처리 ▶ 사후처리 | ①필요한 정보만 수집 형태에서 가능한 다양한 많은 데이터를 모으고 ②데이터를 다양한 방식으로 조합해 주요한 정보를 찾는 것 ①온라인 쇼핑몰의 구매 데이터, 고객 리뷰, 제품 조회 기록 등을 모두 수집하여 고객의 구매 패턴, 선호도를 분석하고 개인 맞춤형 상품 추천
②금융 데이터, 거래 데이터, 소셜 미디어 데이터 등을 분석하여 사기 행위를 예측
|
| 표본조사 ▶ 전수조사 | 표본을 조사하여 모집단을 추정하는 형태에서 전수조사 형태로 변화 일부 고객에게 온라인 설문조사 대신 모든 고객 데이터를 분석하여 고객 만족도를 정확하게 파악하고 개선 방향을 설정
|
| 질 ▶ 양 | 데이터가 추가될 경우 양질의 정보가 오류 정보를 포함되나 더 좋은 예측 결과 도출 초기에는 선택된 소수의 댓글 분석하여 대중의 감정을 예측할 때, 분석된 데이터의 질이 전체 대중의 실제 감정을 반영하는 데 한계가 있음 최근 빅데이터 (데이터의 양)이 크게 증가해서 대규모 데이터를 분석함으로써 얻어진 통찰력은 보다 정확하게 대중의 감정과 트렌드를 반영 |
| 인과관계 ▶ 상관관계 | 상관관계를 통하여 특정 현상에 대한 분석 온도와 아이스크림 판매량 사이의 상관관계를 분석하고, 미래의 판매량을 예측하기 위한 모델을 개발
즉 기계학습 알고리즘을 활용하여 온도 변화가 아이스크림 판매에 미치는 영향을 보다 정확히 예측
|
[14회 기출문제]
다음 중 글로벌 기업의 빅데이터 활용사례로 그 연결이 부적절한 것은?
① 구글 – 실시간 자동 번역시스템을 통한 의사소통의 불편해소
② 라쿠텐 – 이용자의 콘텐츠 기호를 파악하여 새로운 영화를 추천해주는 씨네매치 (Cinematch) 시스템 운영
③ 월마트 – 소셜 미디어를 통해 고객 소비 패턴을 분석하는 월마트랩(Wallmart Labs) 운영
④ 자라 – 일일 판매량을 실시간 데이터 분석으로 상품 수요를 예측
08강Ⅰ-2-1 빅데이터의 개념2
(4) 빅데이터의 가치 산정의 어려움
- ① 데이터 활용방식 : 데이터의 활용방식이 재사용, 재조합, 다목적용 데이터 개발 등이 일반화되면서 가치 산정이 어려워 졌다.
- (재사용) 온라인 쇼핑몰 내 구매 데이터 분석 > 고객에게 맞춤형 상품 추천
- (재조합) 고객 리뷰 데이터, 구매 데이터 분석 > 만족에 따른 상품 제공
- (다목적 활용) 구매 데이터, 날씨 데이터, 교통 데이터를 함께 분석하여 최적의 배송 경로 도출
- ② 새로운 가치 창출 : 빅데이터 시대에는 기존에 없던 가치를 창출함에 따라 측정의 어려움이 생김
- 유튜브 스트리밍 서비스 > 시청 기록 기반 영화 추천 (개인별 선호도 취향 급변, 개인정보 수집 윤리 문제 등)
- ③ 분석 기술 발전 : 현재는 가치 없는 데이터일지라도 추후에는 새로운 분석 기술을 통하여 거대한 가치를 가질 수 있다.
- 이미지 분석 기술 발전 > 사진 속 사물 인식/분류 > 얼굴 표정 내 감정 인식 > 텍스트 (좋음, 나쁨, 슬픔 등) 추출
(5) 빅데이터의 영향
| 대상 | 내용 |
| 기업 | 빅데이터를 활용해 소비자의 행동을 분석하고 시장변동을 예측하여 비즈니스 모델을 발전 넷플릭스: 시청 기록 분석하여 개인에게 맞춤형 콘텐츠 추천
아마존: 구매 패턴 분석하여 상품 추천 및 쇼핑 경험 개선
|
| 정부 | 기상, 인구이동 등의 데이터를 수집하여 사회 변화를 추정 대한민국 정부24: 국민 데이터 분석하여 맞춤형 공공 비대면 서비스 제공 및 민원 해결
대한민국 복지로: 다양한 복지 서비스 (초중고 교육비 지원, 청년월세지원 등)를 비대면 신청 가능
|
| 개인 | 개인의 목적에 따라 빅데이터를 활용 멜론 음원: 빅데이터 기반으로 제공 중인
개인화 서비스 (TOP100 외 아티스트 추천) 제공 |
[15회 기출문제]
다음 중 빅데이터가 만들어 내는 변화로 가장 부적절한 것은?
① 사전처리에서 사후처리 시대로의 변화
② 대면조사에서 표본조사로의 변화
③ 데이터의 질보다 양의 중요도 증가
④ 인과관계에서 상관관계의 중요도 증가
[12회 기출문제]
다음 중 데이터의 가치 측정이 어려운 이유로 적절하지 않은 것은 무엇인가?
① 데이터 재사용의 일반화로 특정 데이터를 언제 누가 사용했는지 알기 힘들기 때문이다.
② 빅데이터 전문 인력의 증가로 다양한 곳에서 빅데이터가 활용되고 있기 때문이다.
③ 분석기술의 발전으로 과거에 분석이 불가능했던 데이터를 분석할 수 있게 되었기 때문이다.
④ 빅데이터는 기존에 존재하지 않던 새로운 가치를 창출하기 때문이다.
[13회 기출문제]
다음 중 빅데이터의 수집, 구축, 분석의 최종 목적으로 가장 적절한 것은?
① 새로운 통찰과 가치를 창출
② 데이터 중심 조직 구성
③ 초고속 데이터 처리 기술 개발
④ 데이터 관리 비용 절감
09강Ⅰ-2-2 비즈니스 모델
(1) 빅데이터 활용 기본 테크닉
| 구분 | 지도 | 지도 | 지도 | 지도/비지도 | 비지도 | 기타 |
| 테크닉 | 회귀 분석 | 분류 분석 | 감정 분석 | 소셜네트워크 분석 | 연관규칙 학습 | 유전자 알고리즘 |
| 내용 | 두 변인의 관계를 파악할 때 사용 | 특성에 따라 분류 | 특정주제에 대해 저자의 감정분석 | 특정인과 관 계도 |
변인들 간에 주목할 만한 상관관계 찾는 방법 | 최적화가 필요한 문제의 해결책 제시 점진적으로 진화 |
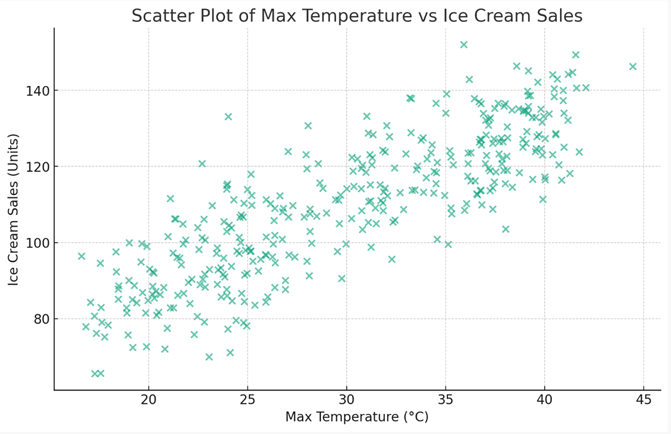
- [회귀 분석] 최고 기온을 이용하여 판매량 예측
- (질문) 날씨가 더우면 아이스크림이 더 많이 팔릴까?
- (입력 데이터) 최고 기온
- (출력 데이터) 아이스크림 판매량
- (학습 모형) 선형회귀모형
- [분류 분석] 최고 기온을 이용하여 판매량 범주 예측
- (질문) 날씨가 더우면 아이스크림 2개 분류 (많은, 적음)로 나타낼 수 있을까?
- (입력 데이터) 최고 기온
- (출력 데이터) 아이스크림 분류 범주 (많음, 적음)
- (학습 모형) 로지스틱회귀모형

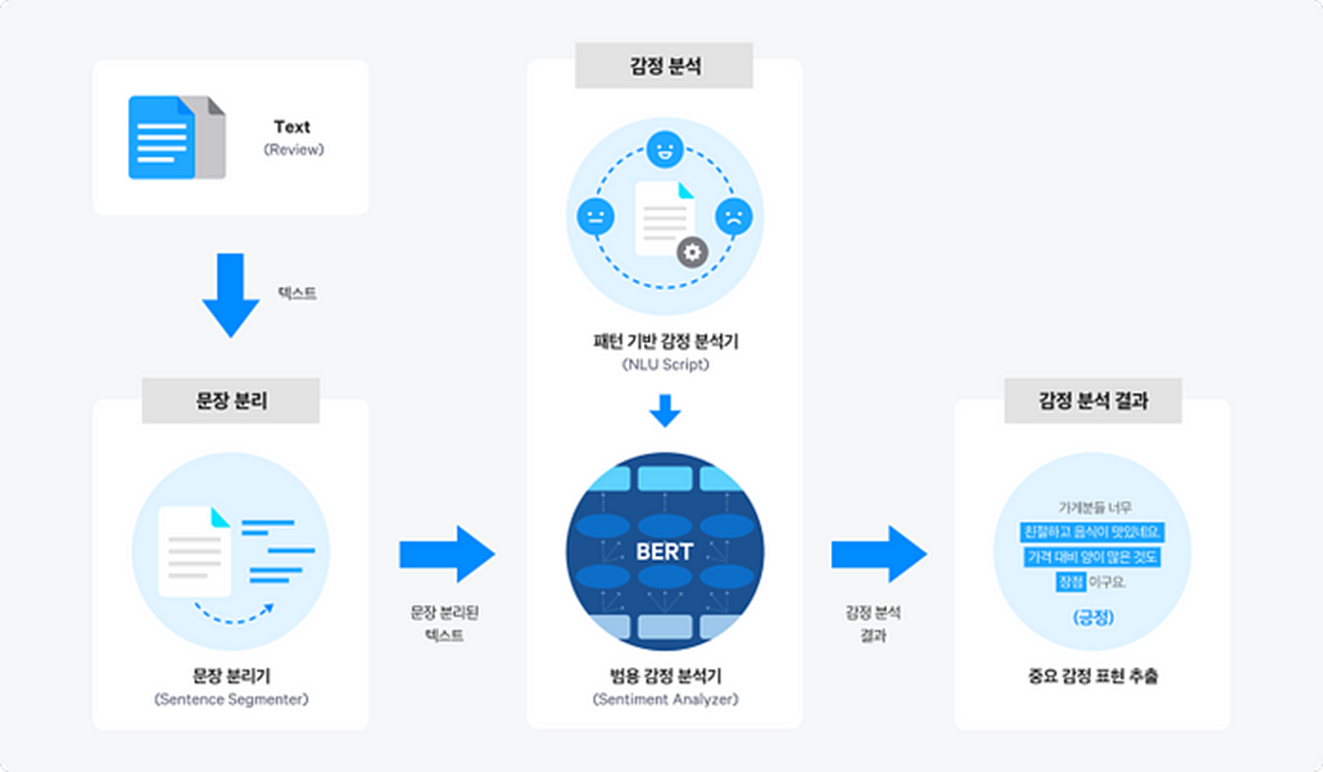
- 감정분석

- 소셜네트워크 분석
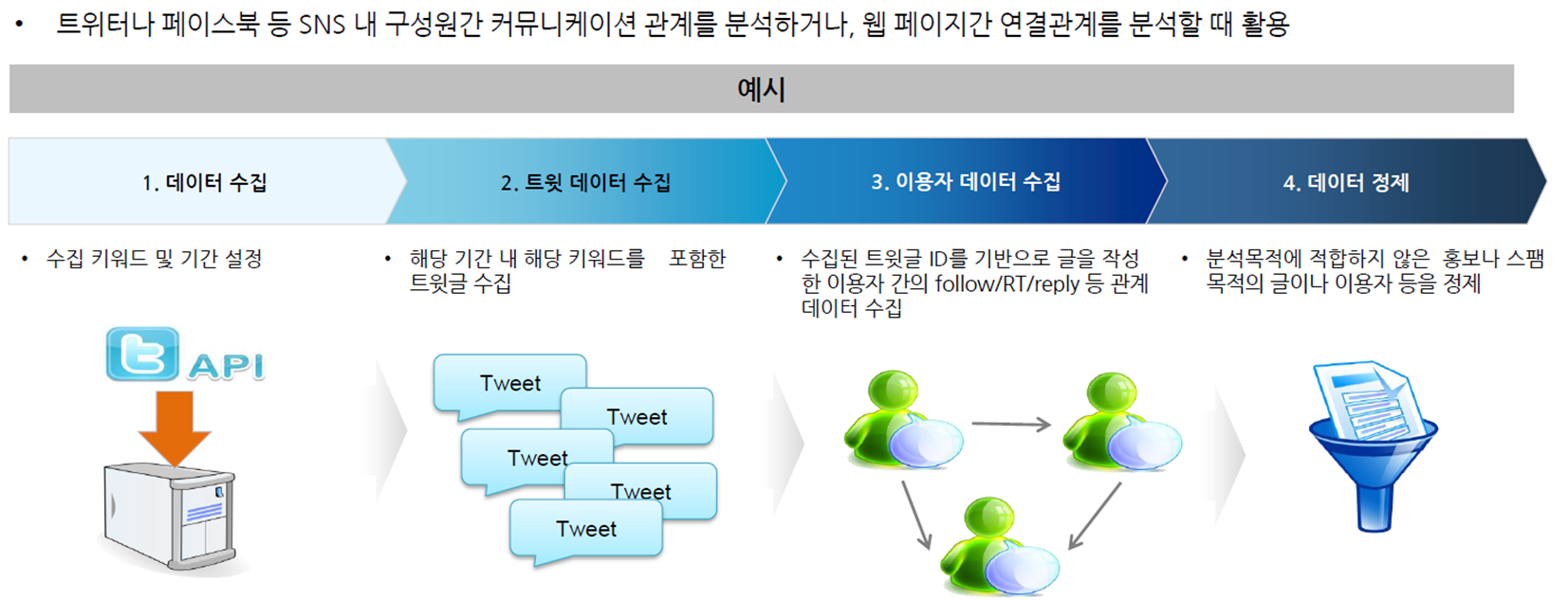
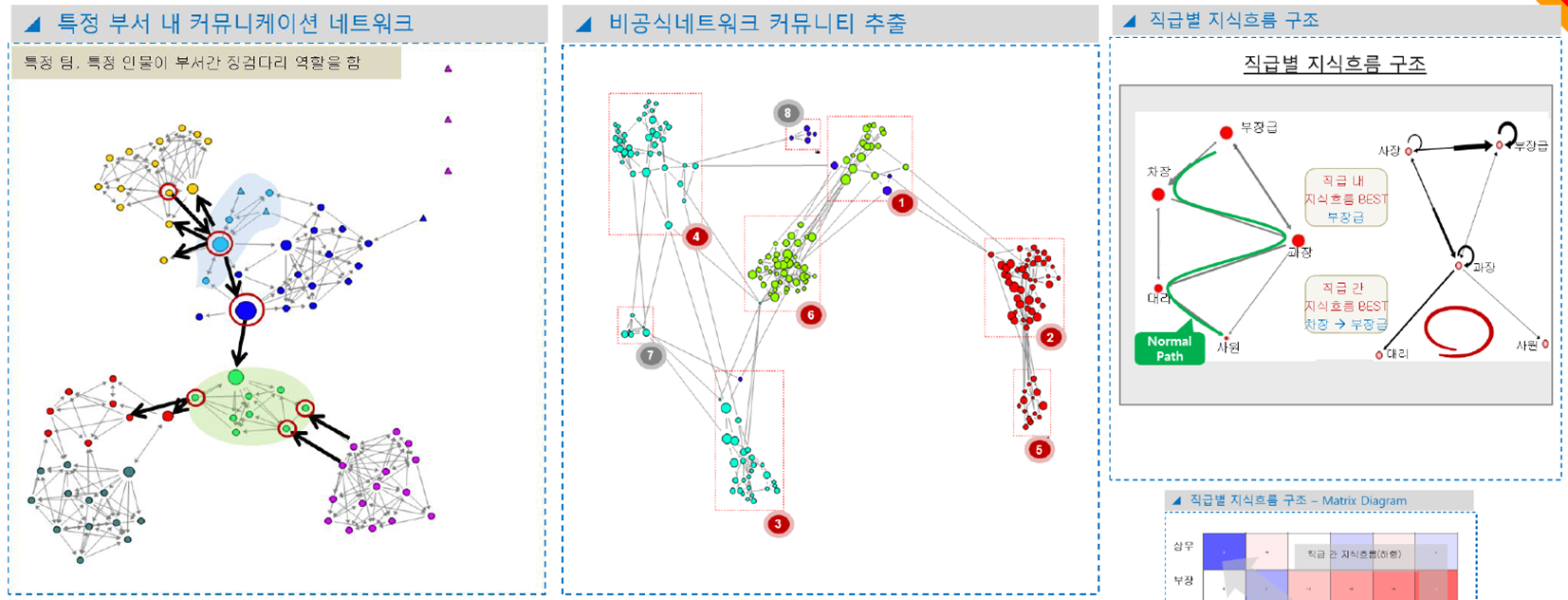
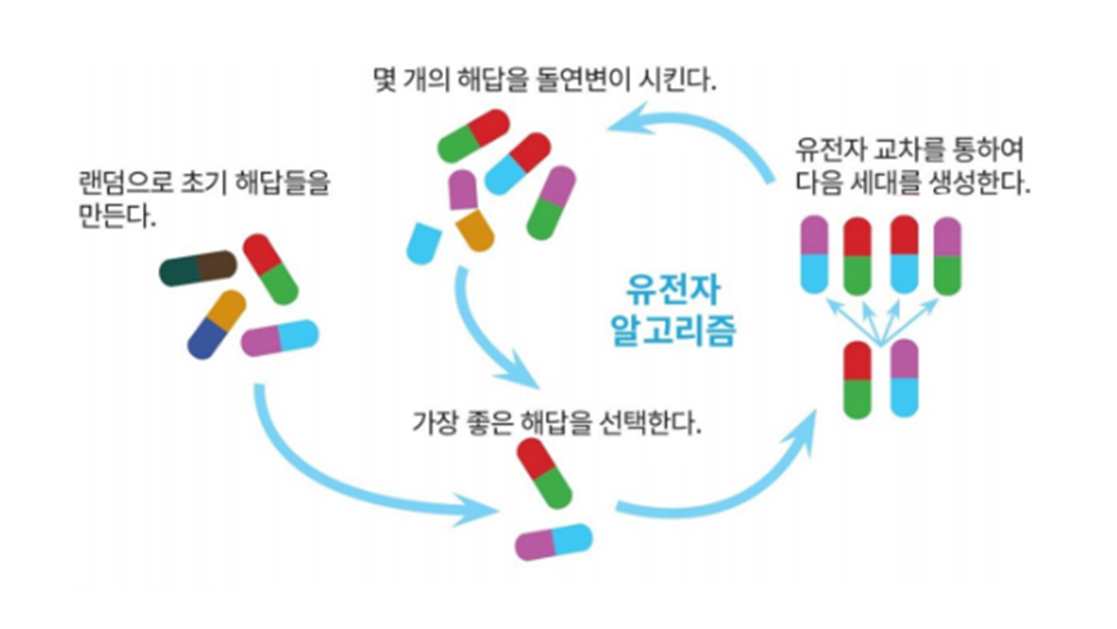
- 유전자 알고리즘
- 생물 유전학에 기반을 둔 진화 과정을 모방한 알고리즘
- 6단계 (생성, 선택, 교차, 변이, 대치, 연산) 과정을 거쳐 최적화 결과 제공
- 연관규칙 학습
[쉽게 배우는 AI] 11. 연관 규칙 학습이란? | 요즘IT
연관 규칙 학습은 이름에서도 알 수 있듯 서로 연관된 특징을 찾는 학습 방법입니다. 이러한 연관 규칙 학습은 쉽게 추천 관련 알고리즘을 떠올리면 되는데요. 영화를 예매했을 때 비슷한 장르
yozm.wishket.com
[14회 기출문제]
다음 중 감성분석에 대한 설명으로 가장 부적절한 것은?
① 특정 주제에 대한 사용자의 긍정, 부정, 의견을 분석한다.
② 주로 온라인 쇼핑물에서 사용자의 상품평에 대한 분석이 대표적 사례이다.
③ 사용자간의 소셜 관계를 알아내고자 할 때 이용한다.
④ 사용자가 사용한 문장이나 단어가 분석 대상이 된다.
[12회 기출문제]
아래와 같은 비즈니스 문제가 있다면 각 문제를 해결하기 위해 주로 사용되는 기법과 연결이 적절하지 않은 것은?
① 맥주를 사는 사람은 콜라도 같이 구매하는 경우가 많다 - 연관규칙학습
② 고객의 만족도는 충성도에 어떤 영향을 미치는가? - 회귀분석
③ 친분관계가 승진에 어떤 영향을 미치는가? - 소셜 네트워크 분석
④ 택배차량은 어떻게 배치하는 것이 비용측면에서 효율적인가? - 유형분석
[17회 기출문제]
아래 빅데이터 활용을 위한 기본테크닉 중 어떤 사례에 해당하는가?
| A마트는 금요일 저녁에 맥주를 사는 사람은 기저귀도 함께 구매했다는 사실을 발견하고, 두가지 상품을 가까운 곳에 진열하기도 결정했다 |
① 회귀분석
② 연관분석
③ 유형분석
④ 구문분석
10강Ⅰ-2-3 빅데이터의 문제점과 해결방안
(1) 빅데이터의 문제점
- ① 사생활 침해
- 개인정보 유출과 같은 사생활 침해를 받을 수 있다
- 소셜 미디어 플랫폼 (인스타그램 등)에서 사용자의 게시물, 좋아요, 팔로우 목록 등을 분석하여 개인적 취향, 정치적 성향, 심지어 건강 상태까지도 반영하여 예측
- ② 데이터 오용
- 잘못된 지표를 사용하는 것은 빅데이터를 통해서 피해를 받을 수 있다.
특정 지역의 교통량 데이터를 잘못 분석하여 불필요한 도로 확장 프로젝트에 막대한 예산을 투입하는 경우
- 잘못된 지표를 사용하는 것은 빅데이터를 통해서 피해를 받을 수 있다.
- ③ 책임 원리의 훼손
- 범죄 예측 프로그램에 의해 범행을 저지르기 전에 체포와 같은 명확한 결과에 대한 책임 원리의 훼손
미국의 재범 예측 프로그램 (COMPAS)는 범죄 재발 확률을 예측하여 판사와 교도관이 보석, 석방, 감옥에서의 처우 결정을 내리는 데 도움을 줌 - 그러나 백인보다 흑의 재범 위험률을 높게 보는 편향된 예측 결과를 제공함
- 이는 법적 판단에 영향을 미쳐 사람들이 불공평한 대우를 제공
- 범죄 예측 프로그램에 의해 범행을 저지르기 전에 체포와 같은 명확한 결과에 대한 책임 원리의 훼손
- 개인정보 유출과 같은 사생활 침해를 받을 수 있다
(2) 문제점의 해결방안
- ① 사생활 침해의 해결방안
- 익명화 기술의 발전이 필요하다.
- 사용자의 개인정보를 수집 기업은 데이터를 익명화 (삭제, 블라, 마스킹 등)하여 개인을 식별할 수 없게 만든 후에 데이터 분석함
- 익명화 기술의 발전이 필요하다.
- ② 데이터 오용
- 불이익을 당한 사람들을 대변할 전문가(알고리즈미스트) 필요
- 알고리즘에 대한 접근권을 제공하여 예측 알고리즘의 부당함을 반증할 방법 명시
- 데이터 오용 신고를 위한 플랫폼 또는 신고보상 프로그램 제공 (페이스북 참조: https://www.facebook.com/data-abuse/faq)
- ③ 책임 원리의 훼손
- 잘못된 예측 알고리즘을 통한 판단을 근거로 불이익을 최소화하는 장치 마련
- 미국의 재범 예측 프로그램 (COMPAS)을 사용 시 결정적인 판단의 근거 대신 보조 도구로 한정적으로 조치
- 잘못된 예측 알고리즘을 통한 판단을 근거로 불이익을 최소화하는 장치 마련
[17회 기출문제]
다음 중 사생활 침해를 막기 위해 개인정보를 무작위 처리하는 등 데이터가 본래 목적 외에 가공되고 처리되는 것을 방지하는 기술은 무엇인가?
① 정규화
② 난수화
③ 익명화
④ 일반화
[14회 기출문제]
다음 중 빅데이터 시대에 발생할 수 있는 위기 요인으로 가장 부적절한 것은?
① 재산권 침해
② 데이터 오용
③ 책임원칙 훼손
④ 사생활 침해
[13회 기출문제]
다음 중 빅데이터 시대 위기 요인 중 사생활 침해 문제를 해결하기 위해 개인 정보를 사용하는 자가 적극적인 보호장치를 강구하게 하는 방법으로 가장 적절한 것은?
① 알고리즘에 대한 접근을 허용해 부당함을 반증할 방법을 명시해 공개할 것을 주문
② 개인정보 제공자가 허락하는 동의제의 도입
③ 개인정보를 사용하는 사람이 직접 책임지는 책임제의 도입
④ 정보 사용자에게 수집된 내용을 공개하고 접근하는 권리 부여
11강Ⅰ-3-1 데이터 사이언스란
(1) 데이터 사이언스의 개념
- 데이터 사이언스는 수학, 통계학, 데이터 공학, 컴퓨터 공학 등의 전문지식을 종합한 학문이다
- 데이터로부터 의미있는 정보를 추츨해내는 학문으로 정형 또는 비정형을 막론하고 다양한 유형의 데이터를 대상으로 분석뿐만 아니라 효과적으로 구현하고 전달하는 과정
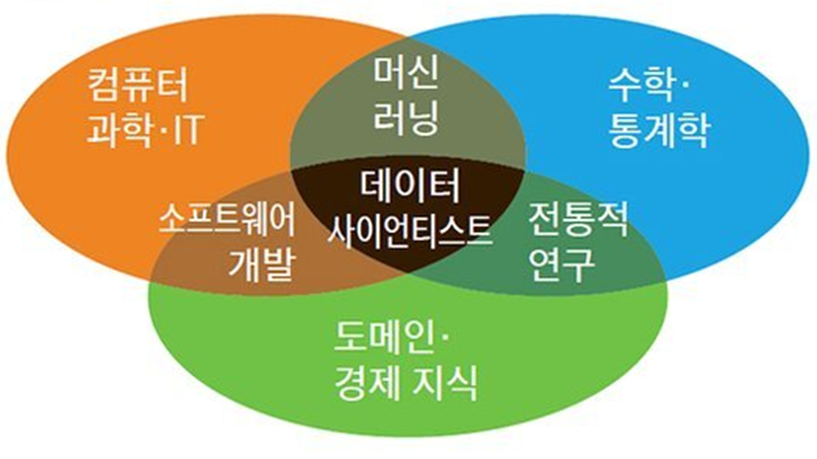
(2) 데이터 사이언스의 영역
- 타 분야 영역이 결합된 다학제적 분야
- ① 분석 영역 : 수학, 확률모델, 통계, 머신러닝, 불확실성 모델링 등
- ② IT 영역 : 프로그래밍, 데이터 엔지니어링, 데이터 웨어하우스 등
- ③ 비즈니스 영역 : 프레젠테이션, 스토리텔링, 시각화 등
(3) 데이터 사이언티스트의 요구역량
- ① 빅데이터에 대한 이론적 지식
- 다양한 머신러닝 알고리즘 원리 이해
- ② 분석 기술에 대한 숙련
- 데이터 전처리 (결측값 처리, 이상치 제거 등) 등 기술 필요
- ③ 통찰력 있는 분석
- 고객의 요구사항 (도로 확장 프로젝트 시 교통량 분석 등)에 맞게 데이터 분석 필요
- ④ 설득력 있는 전달
- 데이터 시각화 도구를 활용하여 이해하기 쉬운 형태 정리
- ⑤ 다분야간 협력
- 타 분야 영역이 결합된 다학제적 분야로서 협업 필요
(4) 데이터 사이언스; 과학과 인문의 교집합
- 분석기술보다 더 중요한 것은 소프트 스킬
- 전략적 통찰을 주는 분석은 단순 통계나 데이터 처리와 관련된 지식
- 그 외에 스토리텔링, 커뮤니케이션, 창의력, 열정, 직관력, 비판적 시각, 대화능력 등 인문학적 요소가 필요하다.
[18회 기출문제]
데이터 사이언스에서 인문학적 사고는 반드시 필요한 요소이다. 다음 중 인문학 열풍을 가져오게 한 외부 환경 요소로 가장 부적절한 것은?
① 디버젼스 동영학이 작용하는 복잡한 세계화
② 비즈니스 중심이 제품생산에서 체험 경제를 기초로 한 서비스로 이동
③ 경제의 논리가 생산에서 최근 패러다임인 시장 창조로 변화
④ 빅데이터 분석 기법의 이해와 분석 방법론 확대
[17회 기출문제]
데이터 사이언스에 대한 설명으로 가장 부적절한 것은?
① 데이터 사이언스는 데이터로부터 의미 있는 정보를 추출하는 학문이다.
② 주로 분석의 정확성에 초점을 두고 진행한다.
③ 정형데이터 뿐만 아니라 다양한 데이터를 대상으로 한다.
④ 기존의 통계학과는 달리 총체적 접근법을 사용한다.
[14회 기출문제]
다음중 데이터 사이언티스트의 필요 역량으로 가장 부적절한 것은?
① 설득력 있는 스토리텔링
② 통찰력 있는 분석
③ 네트워크 최적화
④ 다분야 간 협력을 위한 커뮤니케이션
12강Ⅰ-4-1 DBMS와 SQL
(1) DBMS의 개념과 종류
- ① DBMS(Data Base Management System)란 무엇인가?
- 데이터베이스를 관리하여 응용프로그램들이 데이터베이스를 공유하며 사용할 수 있는 환경을 제공하는 소프트웨어이다.
| DBMS | 제작사 | 작동 운영체제 | 기타 |
| MySQL | Oracle | Unix, Linux, Windows, Mac | 오픈 소스(무료), 상용 |
| MariaDB | MariaDB | Unix, Linux, Windows | 오픈 소스(무료), MySQL 초기 개발자들이 독립해서 만듬 |
| PostgreSQL | PostgreSQL | Unix, Linux, Windows, Mac | 오픈 소스(무료) |
| Oracle | Oracle | Unix, Linux, Windows | 상용 시장 점유율 1위 |
| SQL Server | Microsoft | Windows | 주로 중/대형급 시장에서 사용 |
| DB2 | IBM | Unix, Linux, Windows | 메인프레임 시장 점유율 1위 |
| Access | Microsoft | Windows | PC용 |
| SQLite | SQLite | Android, iOS | 모바일 전용, 오픈 소스(무료) |
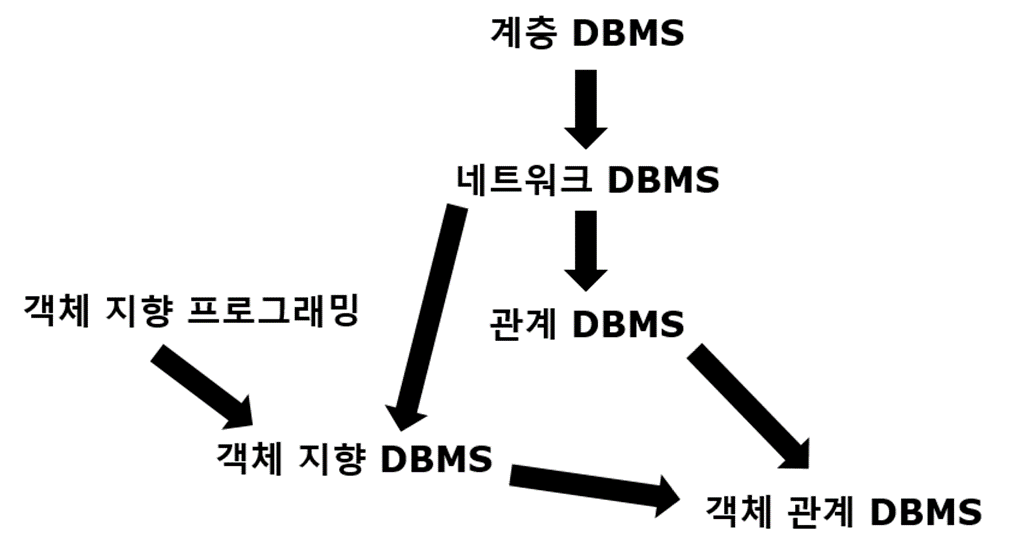
- ② DBMS의 종류
- (ⅰ) 관계형 DBMS: 80년대 초반
- (ⅱ) 객체지향 DBMS: 80년대 후반 객체 지향 프로그래밍 + 네트워크 DBMS
- (ⅲ) 네트워크 DBMS, (ⅳ) 계층형 DBMS: 60~70년대 DBMS
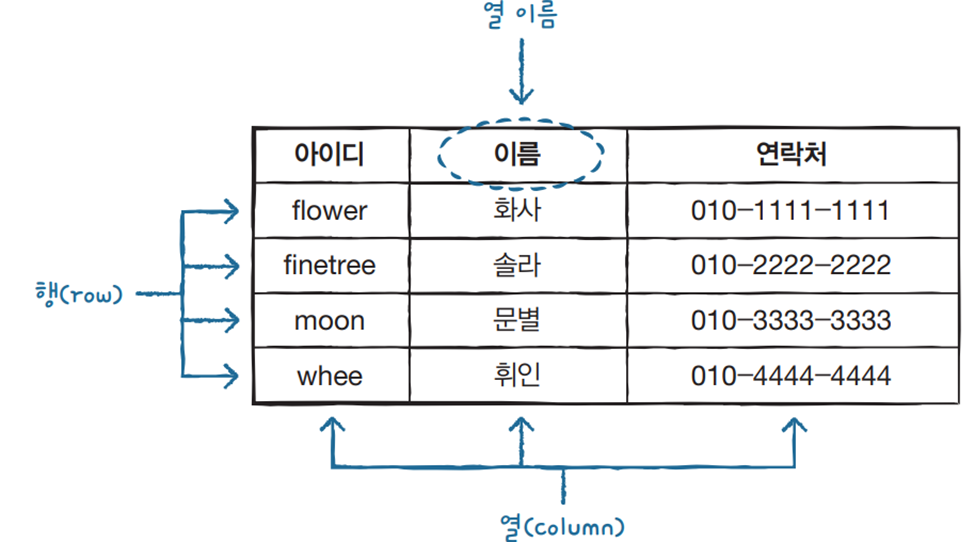
- (ⅰ) 관계형 DBMS
- 데이터를 칼럼, 로우를 이루는 하나 이상의 테이블로 정리하며, 고유키가 로우를 식별한다.
- 로우는 레코드나 튜플로 부르며 일반적으로 각 테이블/관계는 하나의 엔티티 타입을 대표한다.
- 대부분의 DBMS에서 속함
- (ⅱ) 객체지향 DBMS
- 일반적으로 사용되는 테이블 기반의 관계형 DB와 다르게 정보를 ‘객체’ 형태로 표현하는 모델
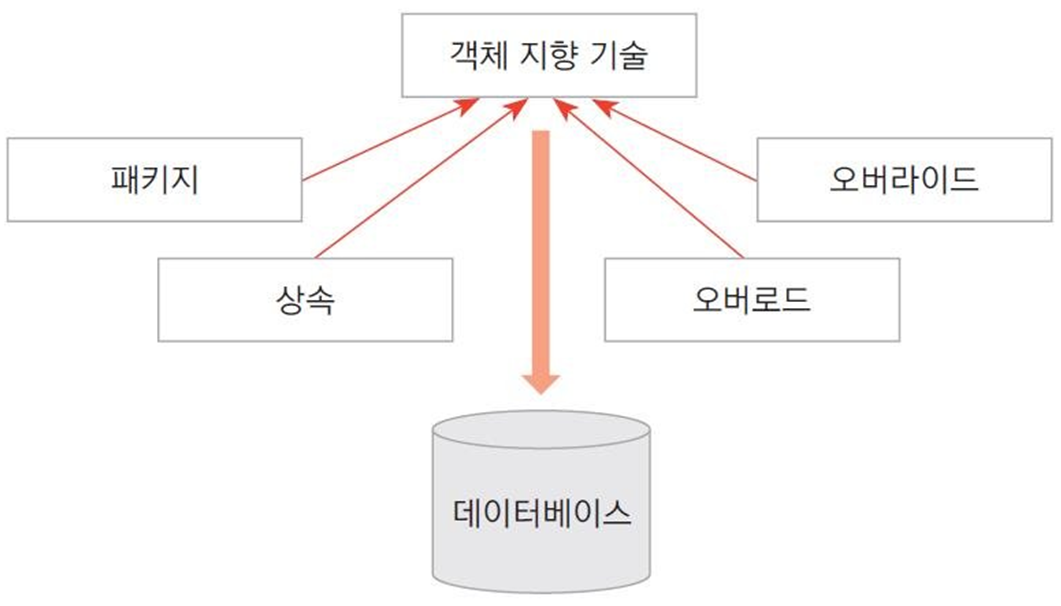
- (ⅲ) 네트워크 DBMS
- 레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 하는 데이터베이스 모델

- (ⅳ) 계층형 DBMS
- 트리구조를 기반으로 하는 계층 데이터베이스 모델이다
(2) SQL의 개념과 주요함수
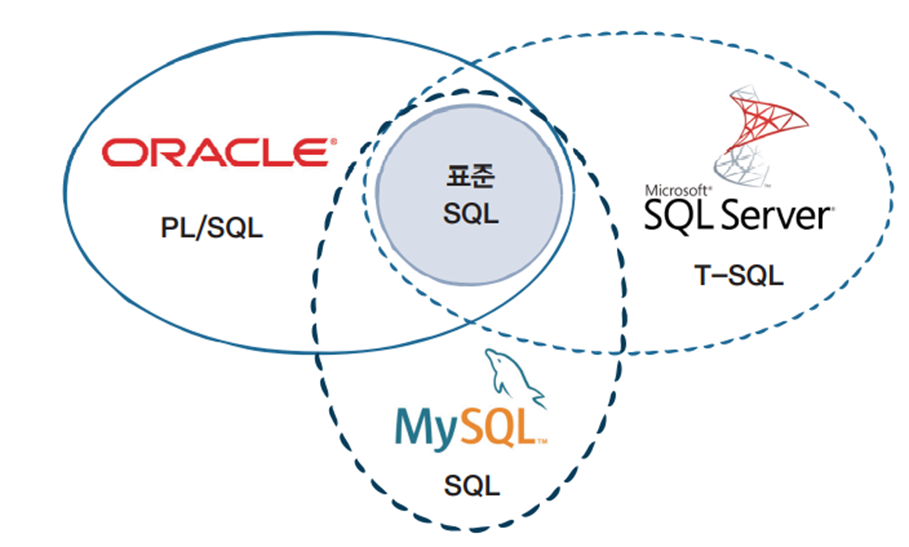
- ① SQL(Structured Query Language)이란 무엇인가?
- 데이터베이스에 접근할 수 있는 데이터 베이스의 하부 언어로, 단순한 질의 기능 뿐만 아니라 완전한 데이터의 정의와 조작 기능을 갖추고 있다.
- ② SQL 주요 함수
| 함수명 | 설명 |
| AVG | 평균값 |
| COUNT | 특정 조건의 맞는 개수 |
| SUM | 총합 |
| STDDEV | 분산 |
| MIN | 가장 작은 값 |
| MAX | 가장 큰 값 |
[17회 기출문제]
다음 중 사용자 정의 데이터 및 멀티미디어 데이터 등 복잡한 데이터 구조를 표현, 관리할 수 있는 데이터베이스 관리 시스템은 무엇인가?
① 관계형 DBMS
② 객체지향 DBMS
③ 네트워크 DBMS
④ 계층형 DBMS
[15회 기출문제]
SQL은 다양한 집계함수를 제공하는데, 다음 집계함수 중 어떠한 데이터의 타입에도 사용이 가능한 것은?
① AVG
② COUNT
③ SUM
④ STDDEV
13강Ⅰ-4-2 데이터에 관련된 기술
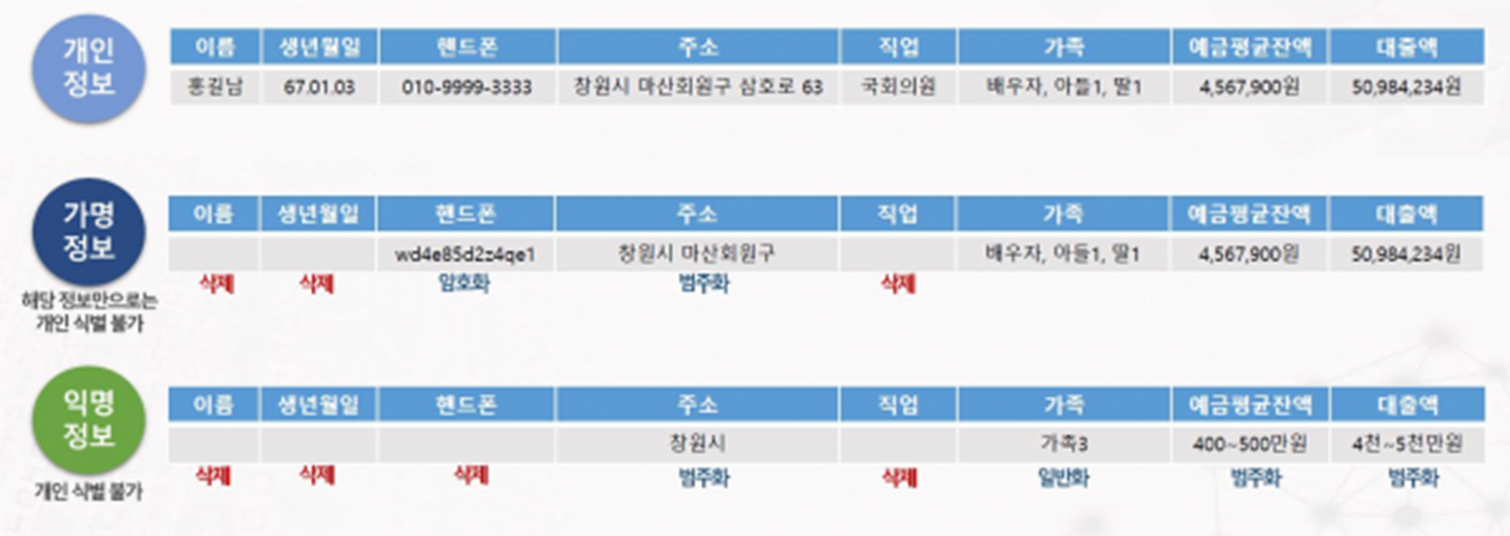
(1) 개인정보 비식별 기술
- 데이터 셋에서 개인을 식별할 수 있는 요소를 전부 또는 일부를 삭제하거나 다른값으로 대체하는 등의 방법으로 개인을 알아볼 수 없도록 하는 기술
- (예제) 데이터마스킹, 가명처리, 총계처리, 데이터값 삭제, 데이터 범주화
(2) 데이터 무결성(Data Integrity)
- 데이터베이스 내의 데이터에 대한 정확한 일관성, 유효성, 신뢰성을 보장하기 위해 데이터 변경/ 수정시 여러 가지 제한을 두어서 데이터의 정확성을 보증
- 기본 키(Primary Key) 제약 조건: 각 행이 고유하게 식별되도록 합니다. 은행 계좌 데이터베이스에서 각 계좌는 고유한 계좌 번호를 기본 키로 가지며, 중복이 허용되지 않습니다.
- 외래 키(Foreign Key) 제약 조건: 두 테이블 간의 관계를 정의하고, 참조 무결성을 유지합니다. 주문 테이블의 고객 ID가 고객 테이블의 기본 키를 참조함으로써, 주문이 유효한 고객에 의해서만 생성되도록 합니다.
- 체크(Check) 제약 조건: 특정 조건을 만족하는 데이터만 테이블에 삽입되도록 합니다. 직원 테이블에서 나이가 18세 이상인 경우에만 데이터를 추가하도록 하는 체크 제약 조건을 설정할 수 있습니다.
- 유일(Unique) 제약 조건: 특정 컬럼의 모든 값이 유일함을 보장합니다. 사용자 이메일 주소가 모두 다르도록 합니다.
(3) 데이터 레이크(Data Lake)
- 많은 정보 속에서 의미있는 내용을 찾기 위해 방식에 상관없이 데이터를 저장하는 시스템
- 웹사이트, 소셜 미디어, IoT(사물 인터넷) 기기 등 다양한 소스로부터 생성된 정형 데이터, 비정형 데이터, 반정형 데이터 등 모든 형태의 데이터
[13회 기출문제]
아래에서 설명하고 있는 ( )는 무엇인가? 데이터 레이크
| 지난 몇 년간 여러 사일로 대신 하나의 데이터 소스를 추구하는 경향이 생겼다. 전사적으로 쉽게 인사이트를 공유하는데 도움이 되기 때문이다. 다시 말해 별도로 정제되지 않은 자연스러운 상태의 아주 큰 데이터 세트인 ( )을/를 기업들이 구현하는 것은 2017년 새롭게 등장한 트랜드가 아니다. 그러나 2017년은 이를 적절히 관리해 운영하는 첫해가 될 전망이다. |
14강Ⅰ-4-3 빅데이터 분석기술
(1) 하둡(Hadoop)
- 여러 개의 컴퓨터를 하나인 것처럼 묶어 대용량 데이터를 처리하는 기술
- 여러 컴퓨터를 하나의 시스템처럼 묶어 대용량 데이터를 처리하는 오픈 소스 소프트웨어 프레임워크
- 저렴한 하드웨어를 사용하여 대규모 데이터를 처리할 수 있도록 설계되었으며, 분산 파일 시스템(HDFS)와 MapReduce 프로그래밍 모델을 기반으로 합
(2) 아파치 스파크(Apache Spark)
- 실시간 분산형 컴퓨팅 플랫폼으로써 스칼라로 작성이 되어 있으나 스칼라/자바/R/파이썬 API를 지원한다.
- 실시간 분산 컴퓨팅을 위한 오픈 소스 프레임워크
- 하둡보다 빠른 처리 속도를 제공하며, 메모리 기반 컴퓨팅을 통해 데이터 처리 성능을 향상
(3) 스마트 팩토리(Smart Factory)
- 사물 인터넷(IoT) 기술을 활용하여 공장의 생산 시스템을 자동화하고 최적화
- 센서, 데이터 분석, 머신러닝 등을 통해 공장 내 설비와 기계의 상태를 실시간으로 모니터링하고, 데이터 기반 의사결정을 통해 생산성을 향상시키고 품질을 개선
(4) 기계학습(Machine Learning), 심화학습(Deep Learning)
- 기계학습은 인공지능의 연구 분야 중 하나로 데이터를 통해 학습하여 예측이나 판단을 하는 기술
- 심화학습은 기계학습의 한 종류로, 인공 신경망을 사용하여 데이터에서 복잡한 패턴을 학습하는 기술
머신러닝(Machine Learning)이란?
- 1959년, 아서 사무엘은 기계 학습을 다음과 같이 정의
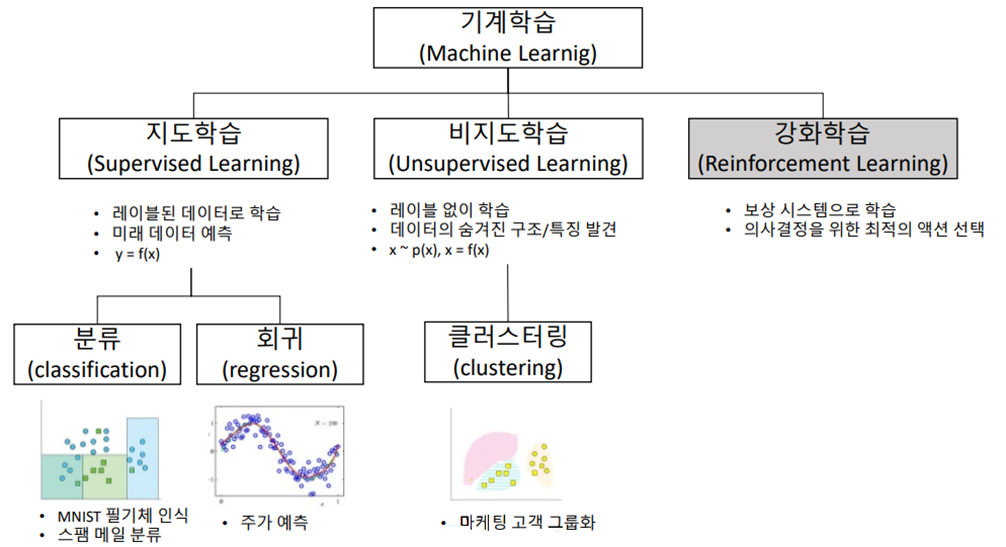
"기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야“ - 알고리즘 유형
- 지도 학습
- 자율 학습 (기계 학습)
- 준 지도 학습
- 강화 학습
- 심화 학습
- 일반적으로 기계 학습은 훈련 이후 새롭게 들어온 데이터를 정확히 처리할 수 있는 능력을 말한다.
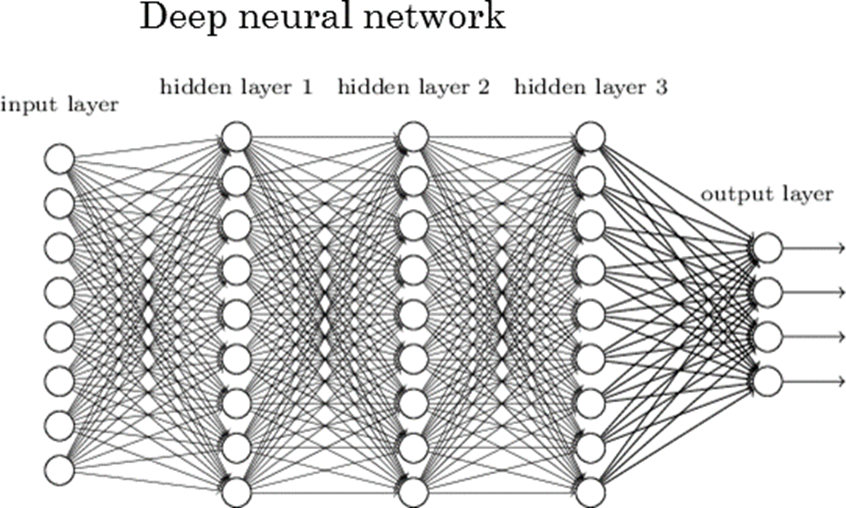
심화학습(deep learning)이란?
- 심층 학습(深層學習) 또는 딥 러닝(영어: deep structured learning, deep learning 또는 hierarchical learning)
- 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화(abstractions, 다량의 데이터나 복잡한 자료들 속에서 핵심적인 내용 또는 기능을 요약하는 작업)를 시도하는 기계 학습 알고리즘의 집합
- 큰 틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야라고 이야기할 수 있다.
15강Ⅰ-4-4 데이터 관한 기타 내용
(1) B2B (Business to Business)
- 기업과 기업 사이의 거래를 기반으로 한 비즈니스 모델
- 제조업체가 유통업체에 상품을 공급하거나, 소프트웨어 회사가 다른 회사에 솔루션을 제공하는 경우
(2) B2C (Business to Consumer)
- 기업과 고객 사이의 거래를 기반으로 한 비즈니스 모델
- 온라인 쇼핑몰에서 제품을 구매하거나, 택배 회사에서 배송 서비스를 이용하는 경우
(3) 블록체인 (Blockchain)
- 거래 정보를 암호화하여 하나의 블록이라는 덩어리로 묶고, 이 블록들을 순서대로 연결하여 만든 거래 장부이다.
- 탈중앙화된 방식으로 운영되기 때문에 중개자 없이, 거래 정보의 위변조가 어려움
- 암호화폐, 금융, 공급망 관리, 의료 등 다양한 분야에서 활용
(4) 데이터의 유형
| 유형 | 내용 | 예시 |
| 정형 데이터 |
형태(고정된 필드)가 있으며 연산이 가능함
데이터 수집 난이도가 낮고 형식이 정해져 있어 처리가 쉬운 편
|
관계형 데이터베이스, 스프레드시트, CSV 등 |
| 반정형 데이터 |
형태(스키마, 메타데이터)가 있으며 연산이 불가능함
데이터 수집 난이도는 중간
|
XML, HTML, JSON, 로그형태 등 |
| 비정형 데이터 |
형태가 없고, 연산이 불가능
데이터 수집 난이도는 높고 처리가 어려움
|
소셜데이터, 영상, 이미지, 음성, 텍스트 등 |

[12회 기출문제]
다음 중 데이터에 대한 설명으로 가장 적절하지 않는 것은 무엇인가?
① 양질의 데이터를 확보하지 못하면 잘못된 분석 결과를 얻음
② 창의적인 데이터 매시업은 기존에 풀기 어려웠던 문제 해결에 도움
③ 비정형 데이터는 데이터 내부에 데이터를 갖고 있으며 일반적으로 파일 형태로 저장
④ 공공부문에서 개방하고 있는 대표적인 데이터는 교통 데이터, 물가 데이터, 의료 데이터이다.
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'자기계발 > 자격증' 카테고리의 다른 글
| [자격증] 데이터분석 준전문가 (ADsP) Ⅲ 데이터 분석 : 01~08강 (0) | 2024.06.15 |
|---|---|
| [자격증] 데이터분석 준전문가 (ADsP) Ⅱ 데이터 분석 기획 : 01~17강 (0) | 2024.06.15 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 기초, 핵심 요약, 문제풀이 (0) | 2023.02.14 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 10회, 11회 기출 문제 (0) | 2022.10.27 |
| [자격증] 데이터분석 전문가 (ADP) 필기 : 제5과목 데이터 시각화 (0) | 2022.10.27 |








최근댓글