정보
-
업무명 : R 및 Python을 이용한 '디시인사이드' MBTI 성격 갤러리의 웹 크롤링 및 키워드 분석을 통한 워드 클라우드 생성
-
작성자 : 해솔
-
작성일 : 2020-05-22
-
설 명 :
-
수정이력 :
내용
[개요]

-
MBTI (마이어스-브릭스 유형 지표) 는 제2차 세계 대전 시기에 개발된 일종의 성격유형 테스트이다.
-
즉 사람의 성격을 [외향 (E) -내향 (I)] / [감각 (S) - 직관 (N)] / [감정 (F) - 논리 (T)] / [판단 (J) - 인식 (P)] 을 각 지표로 하여 16개의 유형으로 나눈 것을 뜻한다.
-
따라서 사람들의 성격은 유형에 차이가 있을 것이며, 각 성격에 따라 사용하는 언어적 특징 역시 달라질 것으로 기대된다.
-
본 글에서는 '디시인사이드' 라는 커뮤니티 사이트의 유형별 MBTI 갤러리의 게시글을 크롤링 하고 내용으로부터 키워드를 분석하여 명사 추출 및 빈도분석을 실시하여, 결과적으로 워드클라우드를 생성하고, 이러한 과정이 어떻게 이루어졌는지, 그리고 분석 결과가 어떻게 나타났는지 확인하고자 한다.
-
추가적으로 본인의 MBTI 유형을 직접 검사해보고자 하는 경우 아래의 링크를 참조하여 무료로 검사 및 확인이 가능하다.
[MBTI 성격 유형 검사 하는 곳]
https://www.16personalities.com/ko/
무료 성격 유형 검사, 성격 유형 설명, 인간관계 및 직장생활 어드바이스 | 16Personalit
16Personalities 검사가 너무 정확해 "살짝 소름이 돋을 정도예요"라고 성격 유형 검사를 마친 한 참여자는 말했습니다. 쉽고 간단하면서도 정확한 성격 유형 검사를 통해 당신이 누구이며, 왜 그러��
www.16personalities.com
[특징]
-
디시인사이드 커뮤니티 사이트의 각 유형별 MBTI 갤러리별 언어 사용의 특징을 분석하고자 함
[기능]
-
1. 디시인사이드 크롤링 소스코드 (사용언어 : R)
-
2. 키워드 추출 소스코드 (사용언어 : Python 3.7)
-
3. 빈도분석 및 워드클라우드 생성 소스코드 (사용언어 : R)
[활용 자료]
-
입력자료 : 타겟이 되는 디시인사이드 갤러리 주소
-
사용된 주요한 패키지 종류
-
R
-
dplyr (데이터 처리 및 가공을 위한 패키지)
-
stringr (문자열 처리를 위한 패키지)
-
wordcloud2 (워드클라우드 생성을 위한 패키지)
-
rvest (웹 사이트 크롤링을 위한 패키지)
-
-
Python
-
pandas (데이터 입출력을 위한 패키지)
-
os (시스템 제어를 위한 패키지)
-
konlpy (말뭉치 분석 및 명사 추출을 위한 패키지)
-
[자료 처리 방안 및 활용 분석 기법]
-
말뭉치 분석
-
명사 추출
[사용법]
-
소스 코드 참조
[사용 OS]
-
Windows 10
[사용 언어]
-
R v3.6.2
-
R Studio v1.2.5033
소스 코드
[Step 1. 데이터를 수집할 커뮤니티 확인]
-
디시인사이드는 매우 거대한 커뮤니티 이므로 게시판의 종류 역시 매우 다양하다.
-
여기서 우리가 분석하고자 하는 게시판은 각 유형별 MBTI 게시판이다.
-
따라서 해당 게시판이 있는지를 먼저 확인하는 과정을 거쳤다.
-
확인 결과 분석 대상에 포함되는 총 16개의 갤러리 중에서 ESFJ 갤러리를 제외한 모든 갤러리가 존재하였다.

-
결과적으로 상기한 ESFJ 갤러리를 제외한 15개의 갤러리가 분석 대상이 되었으며 각 갤러리의 목록은 아래와 같다.
-
ENFJ 갤러리
-
ENFP 갤러리
-
ENTJ 갤러리
-
ENTP 갤러리
-
ESFP 갤러리
-
ESTJ 갤러리
-
ESTP 갤러리
-
INFJ 갤러리
-
INFP 갤러리
-
INTJ 갤러리
-
INTP 갤러리
-
ISFJ 갤러리
-
ISFP 갤러리
-
ISTJ 갤러리
-
ISTP 갤러리
-
[Step 2. 데이터 수집]
-
각 갤러리의 데이터 수집은 R 의 rvest 패키지를 통하여 이루어졌다.
-
각 게시판별로 사이트를 크롤링 하기 위하여, 디렉토리를 구분지었으며, 너무 빠른 크롤링이 시행되는 경우 웹 사이트에 대한 공격으로 판단하여 사이트로부터 한시적 IP 차단을 당하게 된다는 사실을 고려하여 크롤링 속도에 딜레이를 주었다.

-
상기한 이유로 인하여 크롤링 속도에 제한이 발생하였으며, 이로 인하여 시간 관계상 각 게시판 글이 총 3000개 이상 존재하는 경우 최근 3000개의 글만을 수집 대상으로 분류하였다.
-
가령 예를 들어 총 게시물의 수가 60000개를 넘어가는 INFP 게시판의 경우 57000번쨰 글 부터 60000번쨰 글 까지를 크롤링 하였다.
-
데이터 수집 소스 코드는 아래와 같다.
#### 페키지 로드 #####
library(rvest)
library(stringr)
library(tidyverse)
library(dplyr)
#### 페키지 로드 #####
#딜레이 시간 설정
times = 2
# 데이터 프레임 생성
data_full <- data.frame()
# 게시판 글 숫자 만큼의 루프문 생성
for (i in 1:34) {
# URL 지정
url_intp <- paste0("https://gall.dcinside.com/mgallery/board/view/?id=esfp&no=",i)
# read html page #
html_page <- tryCatch(html_page <- read_html(url_intp),
error = function(e) return("error"),
warning = function(w) return("warning"),
finally = NULL)
# read html page #
# 404 에러가 발생하는 경우 다음 루프를 진행
if(html_page == "error") {
print("error 404! next loop!")
Sys.sleep(times)
next
}
#### title 추출 ####
html_title <- html_text(html_nodes(html_page, '.title_subject'))
#### contents 추출 ####
html_content1 <- html_nodes(html_page, '.writing_view_box')
html_content2 <- html_nodes(html_content1, 'div')
html_content3 <- str_replace_all(html_text(html_content2)[4],"\r","")
if(is.na(html_content3)){
html_content3 <- str_replace_all(html_text(html_content2)[3],"\r","")
}
if(is.na(html_content3)){
html_content3 <- str_replace_all(html_text(html_content2)[2],"\r","")
}
html_content4 <- str_replace_all(html_content3,"\t","")
html_content_fin <- str_replace_all(html_content4,"\n","")
# 데이터 프레임 병합
data <- data.frame(num = i, title = html_title, content = html_content_fin)
# 데이터 프레임 병합
data_full <- bind_rows(data_full,data)
# 딜레이 지정
Sys.sleep(times)
print(i)
}
# 결과파일 저장
write.csv(data_full,"./esfp_txt.csv")
-
데이터 수집 결과의 예시는 아래의 그림과 같다.

[Step 3. 말뭉치 분석을 통한 단어 추출]
-
말뭉치 분석 및 명사 추출은 Python의 konlpy 패키지를 통하여 수행 되었다.
-
입력 자료는 앞선 크롤링을 통하여 수집된 csv 파일이며, 이를 Python에서 읽어들인 후 말뭉치 분석 및 단어 추출을 수행한다.
-
기타 pandas 및 csv 등 데이터 입출력을 위한 보조 패키지들 역시 사용되었다.
-
말뭉치 분석 및 명사 추출을 위한 소스코드는 아래와 같다.
# 말뭉치 분석 및 명사 추출 패키지 로드
from konlpy.tag import Kkma
# 함수 설정
kkma = Kkma()
#기타 패키지 로드 #
import pandas as pd
import numpy as np
import os
import sys
from dfply import *
import math
import csv
# 글 내용이 없는 경우 nan이 리턴되는데 이를 방지해주는 함수
def isNaN(string):
return string != string
#작업 디렉토리 지정
os.chdir("C:/Users/User/Desktop/wordcloud_dc/ISTP")
#데이터 입력 포멧 결정
data = pd.read_csv("./istp_txt2.csv",encoding='CP949')
# 제목과 내용 분리 #
title = data.title
content = data.content
title_result = []
for i in title:
check = isNaN(i)
if check == True:
continue
title_part = kkma.nouns(i) # 각 제목으로부터 명사 추출
title_result.extend(title_part)# 각 제목으로부터 명사 출력 결과 저장
content_result = []
count = 0
for i in content:
check = isNaN(i)
if check == True:
continue
content_part = kkma.nouns(i) # 각 내용으로부터 명사 추출
content_result.extend(content_part) # 각 내용으로부터 명사 저장
# 출력파일 쓰기 #
with open('istp_title2.csv', 'w', newline='') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
wr.writerow(title_result)
# 출력파일 쓰기 #
with open('istp_contents2.csv', 'w', newline='') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
wr.writerow(content_result)
-
소스코드의 출력 결과 예시는 아래와 같다. (가로로 출력됨)

[Step 4. 분석 결과 전처리]
-
상기 명사 출력 결과를 다시 R에서 읽어들인 후 각 단어의 빈도수를 분석하고자 한다.
-
우선 첫번쨰로 단어의 전처리가 필요하다.
-
단어의 전처리란 가로로 흩어진 단어들을 전치하여 모은 후 이를 빈도분석 하는 과정이다.
-
상기 데이터를 읽어와 전처리 하는 코드는 아래와 같다. (R 프로그램 사용)
library(RColorBrewer)
library(stringr)
library(tidyverse)
library(dplyr)
library(ggplot2)
library(data.table)
library(tm)
library(wordcloud2)
library(webshot)
library(htmlwidgets)
##### 전처리 #####
fn <- Sys.glob(paste0("./ISFJ/txt_result/*"))
data_full <- data.frame()
for (f in fn) {
data_part <- fread(f,sep=",",stringsAsFactors = F)
data_part <- data.frame(word = t(data_part))
data_full <- bind_rows(data_full,data_part)
}
result <- data_full %>%
dplyr::filter(!is.na(word)) %>% # NA 값 걸러내기
dplyr::group_by(word) %>% # 동일단어 그룹화
dplyr::summarise(freq = n()) %>% # 단어의 빈도수 계산
dplyr::ungroup() %>% # 그룹 해제
dplyr::arrange(desc(freq)) %>% #빈도수에 맞추어 정렬
dplyr::filter(freq != 1) %>% # 빈도수가 1인 단어 삭제
dplyr::mutate(word_len = nchar(word)) %>% # 단어의 길이 계산
dplyr::filter(word_len != 1) %>% #단어의 길이가 1인 경우 삭제
dplyr::select(-word_len) #단어의 길이 컬럼 삭제
##### 전처리 끝 #####
-
전처리가 끝난 빈도분석 결과의 예시는 아래와 같다.
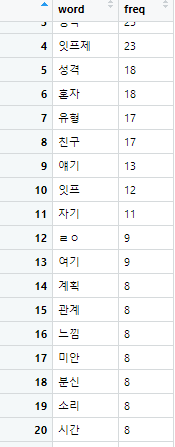
[Step 5. 워드클라우드 생성 및 저장]
-
워드클라우드 생성은 Step 4. 로부터 전처리가 끝난 데이터를 입력자료로 한다.
-
워드클라우드 생성을 위해 R의 wordcloud2 페키지를 이용하였다.
-
결과적으로 워드클라우드 생성 후 html 페이지를 생성하여 이를 다시 png로 불러오는 과정을 실시하여 최종 결과를 생성한다.
-
코드는 아래와 같다.
# 플롯 #
hw = wordcloud2(data =result,
fontFamily='나눔바른고딕',
minSize = 2,
gridSize = 15) # result 데이터를 이용하여 워드 클라우드 생성
# html로 내보내기
saveWidget(hw,"1.html",selfcontained = F)
# 내보낸 html 페이지로부터 png 형태로 불러와서 저장
webshot::webshot("1.html","ISFJ.png",vwidth = 775, vheight = 550, delay = 10)
[fin. 결과]
-
최종적으로 각 유형별 mbti 갤러리별 출력된 워드클라우드는 아래와 같다.
-
ENFJ 갤러리

-
ENFP 갤러리

-
ENTJ 갤러리

-
ENTP 갤러리

-
ESFP 갤러리

-
ESTJ 갤러리

-
ESTP 갤러리

-
INFJ 갤러리

-
INFP 갤러리

-
INTJ 갤러리

-
INTP 갤러리

-
ISFJ 갤러리

-
ISFP 갤러리

-
ISTJ 갤러리

-
ISTP 갤러리

참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
본 블로그는 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있음
'프로그래밍 언어 > R' 카테고리의 다른 글
| [R] 한국 주요 좌표계에 대한 proj4 인자 및 지도 예시 (0) | 2020.10.25 |
|---|---|
| [R] 네이버 네모네모로직 사이트 퍼즐 크롤링 및 해결 프로그램 (2) | 2020.10.24 |
| [R] R을 이용한 수치해석 : 2020년 대학수학능력시험 (수능) 가형 기출문제 (0) | 2020.05.18 |
| [R] 서울대 통계 연구소 R을 이용한 빅데이터 분석 교육 연수 (0) | 2020.05.12 |
| [R] KLAPS 수치예측 모델 자료를 이용하여 내삽 방법 (Multi level B-Spline Approximation, Kriging)에 따른 전처리 및 가시화 (0) | 2020.04.14 |








최근댓글