정보
업무명 : 범주형 데이터를 다루는 "forcats" 패키지 소개
작성자 : 박진만
작성일 : 2020-02-09
설 명 :
수정이력 :
내용
[개요]
tidyverse패키지 군의 하나로, 범주 형 변수 (Factor 형 데이터)를 만지는 데 특화 한 것으로 forcats패키지가 존재한다.
개발의 경위 나 자세한 내용은 패키지의 공식 사이트 및 "R for Data Science"의 Factors 장을 참조하길 바람
Tools for Working with Categorical Variables (Factors) • forcats
Tools for Working with Categorical Variables (Factors)
Helpers for reordering factor levels (including moving specified levels to front, ordering by first appearance, reversing, and randomly shuffling), and tools for modifying factor levels (including collapsing rare levels into other, 'anonymising', and manua
forcats.tidyverse.org
15 Factors - R for Data Science
R for Data Science
This book will teach you how to do data science with R: You’ll learn how to get your data into R, get it into the most useful structure, transform it, visualise it and model it. In this book, you will find a practicum of skills for data science. Just as a
r4ds.had.co.nz
[특징]
범주형 데이터를 다루는 forcats 패키지 소개
[사용법]
본문의 소스코드를 실행하면 됨
[사용 OS]
Windows10
[사용 언어]
R v3.6.2
R Studio v1.2.5033
소스 코드
[명세]
[설치]
CRAN에 등록 되어있음
해당 패키지는 tidyverse패키지에 속해있기 때문에 tidyverse를 설치하는 경우 동시에 설치된다.
# {tidyverse}을 설치하면 자동으로 설치됨.
install.packages("tidyverse")
# 물론 독립적으로도 설치 가능
install.packages("forcats")
# 깃허브를 통해 인스톨 역시 가능
# install.packages("devtools")
devtools::install_github("tidyverse")
# install.packages("githubinstall")
githubinstall::githubinstall("forcats")
[패키지 로드]
해당 패키지는 tidyverse패키지 그룹에 속해있지만 library(tidyverse)를 통해 독립적으로 사용할 순 없다.
# 동시에 로드 library(tidyverse) library(forcats)
[함수 목록 확인]
export되는 함수를 조회할 수 있음.
# 함수 목록 확인
ls("package:forcats")

함수의 참조는 아래의 사이트에서 추가적으로 확인 가능
Function reference
forcats is a part of the tidyverse, an ecosystem of packages designed with common APIs and a shared philosophy. Learn more at tidyverse.org.
forcats.tidyverse.org
[예제에 사용할 데이터]
본 글에 사용할 예제 데이터는 forcats패키지에 내포되어있는 gss_cat데이터를 사용하고 있다.
데이터의 내용은 "?gss_cat"에 표시되는 도움말을 확인하면 된다.
gss_cat #> # A tibble: 21,483 x 9 #> year marital age race rincome partyid #> <int> <fctr> <int> <fctr> <fctr> <fctr> #> 1 2000 Never married 26 White $8000 to 9999 Ind,near rep #> 2 2000 Divorced 48 White $8000 to 9999 Not str republican #> 3 2000 Widowed 67 White Not applicable Independent #> 4 2000 Never married 39 White Not applicable Ind,near rep #> 5 2000 Divorced 25 White Not applicable Not str democrat #> 6 2000 Married 25 White $20000 - 24999 Strong democrat #> 7 2000 Never married 36 White $25000 or more Not str republican #> 8 2000 Divorced 44 White $7000 to 7999 Ind,near dem #> 9 2000 Married 44 White $25000 or more Not str democrat #> 10 2000 Married 47 White $25000 or more Strong republican #> # ... with 21,473 more rows, and 3 more variables: relig <fctr>, #> # denom <fctr>, tvhours <int> names(gss_cat) #> [1] "year" "marital" "age" "race" "rincome" "partyid" "relig" #> [8] "denom" "tvhours"
[Factor 의 order 을 변경하기]
factor로 설정되어있는 levels은 변경하지 않고, 순서 (order)를 변경한다.
이는 모델링과 테이블, 시각화에서 큰 효과를 발휘한다.
[등장 순서 factor의 levels를 재정리 (fct_inorder)]
"등장한 순서" 에 따라 levels의 order를 설정하려면 fct_inorder()함수를 사용한다.
사용법
fct_inorder(f)
f : 임의의 factor 형 데이터.
예시
f <- factor(c("b", "b", "a", "c", "c", "c"))
f
#> [1] b b a c c c
#> Levels: a b c
fct_inorder(f)
#> [1] b b a c c c
#> Levels: b a c
[등장 빈도 순으로 factor의 levels를 재정리 ( fct_infreq)]
데이터에서 나온 "빈도가 많은 순서"에서 levels의 order를 정렬하려면 fct_infreq()함수를 사용함.
사용법
fct_infreq(f)
f : 임의의 factor 형 데이터.
예시
f <- factor(c("b", "b", "a", "c", "c", "c"))
f
#> [1] b b a c c c
#> Levels: a b c
fct_infreq(f)
#> [1] b b a c c c
#> Levels: c b a
[수동으로 factor의 levels를 재정리 ( fct_relevel)]
levels의 순서를 수동으로 정렬한다.
사용법
fct_relevel(f, ...)
f : 임의의 factor 형 데이터
... : 문자열 벡터를 지정합니다. 지정된 값을 levels의 왼쪽 (시작)에 가지고 가고, 그렇지 않으면 뒤로 이동합니다.
예시
즉 base::relevel() 의 래퍼에서 ...의 부분에 지정된 값을 가지고 오게 됨.
또한, 모든 요소를 준비하고 일부러 지정하지 않고, 지정하지 않은 요소는 자동으로 뒤로 이동하게 됨.
f <- factor(c("a", "b", "c"))
fct_relevel(f)
#> [1] a b c
#> Levels: a b c
fct_relevel(f, "c")
#> [1] a b c
#> Levels: c a b
fct_relevel(f, "b", "a")
#> [1] a b c
#> Levels: b a c또한 존재하지 않는 levels 값을 지정하면 경고가 표시되고, 해당 요소는 무시됨.
fct_relevel(f, "d") #> Warning: Unknown levels in `f`: d #> [1] a b c #> Levels: a b c fct_relevel(f, "b", "d") #> Warning: Unknown levels in `f`: d #> [1] a b c #> Levels: b a c fct_relevel(f, "d", "b") #> Warning: Unknown levels in `f`: d #> [1] a b c #> Levels: b a c
[다른 1 변수에 따라 정렬하도록 levels을 다시 정렬 ( fct_reorder)]
다른 변수를 사용하여 levels를 정렬함.
예를 들어 "각 카테고리에서 x의 중앙값을 사용하여 내림차순으로 되도록 levels를 정렬하고 싶은 경우" 에 사용할 수 있다.
- 사용법
fct_reorder(f, x, fun = median, ..., .desc = FALSE)
f
factor 형 벡터.
x
정렬 기준으로 사용할 변수. 이 변수를 아래의 fun지정 집계 용 함수에 보낸 결과를 정렬에 사용할 수 있음.
fun
집계 용 함수를 지정할 수 있다. 디폴트는 median. 이며, 또한 반환 값은 단일 벡터가 되어야만 한다.
...
fun에 보내는 다른 인수를 여기에서 지정할 수 있다. 즉 na.rm = TRUE등을 지정할 수 있다.
.desc
논리 값을 지정. 내림차순 / 오름차순을 지정합니다. 기본값은 FALSE으로 오름차순 정렬.
예시
해당 함수는 1 차원 데이터의 그래프를 그릴 때 혹은 표를 만들 때 효과를 발휘할 수 있다.
예를 들어, 아래와 같은 패턴을 가정해보자.
boxplot(Sepal.Width ~ Species, data = iris)

여기서, " Sepal.Width" 의 크기 순서로 X 축 정렬을 하고 싶다고 가정한다면
boxplot(Sepal.Width ~ fct_reorder(Species, Sepal.Width), data = iris)

또한 기본적으로 중간값을 사용하고 있지만, 변경도 가능하다.
boxplot(Sepal.Width ~ fct_reorder(Species, Sepal.Width, .fun = sample, size = 1), data = iris)

만약 내림차순으로 하려면 아래와 같이 하면 된다.
boxplot(Sepal.Width ~ fct_reorder(Species, Sepal.Width, .desc = TRUE), data = iris)
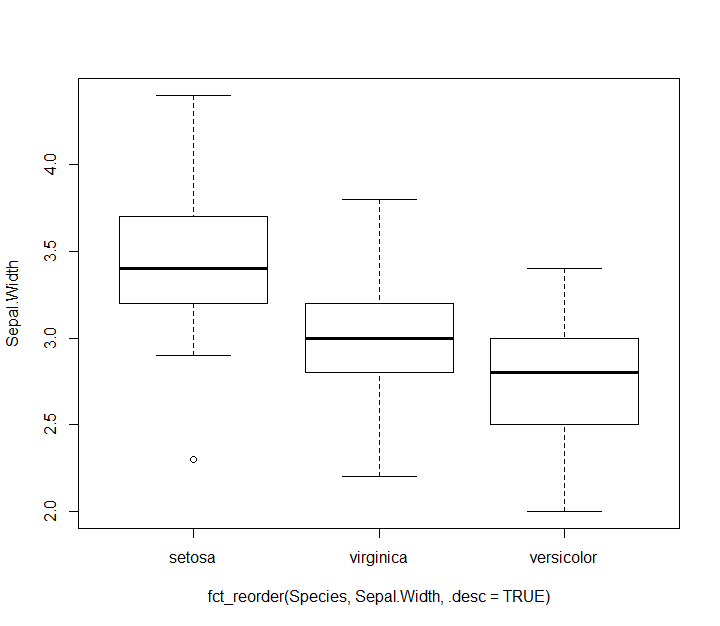
이것들은 물론 ggplot2 등의 라이브러리에서도 유효하다. (아래의 코드 참조)
library(ggplot2) # 7 ggplot(iris, aes(Species, Sepal.Width)) + geom_boxplot()

종전과 마찬가지로 변경도 가능하다.
ggplot(iris, aes(fct_reorder(Species, Sepal.Width), Sepal.Width)) + geom_boxplot() + labs(x = "Species")

또한 두개 변수를 키로 사용하는 경우 fct_reorder2 를 사용할 수 있다.
[다른 두 변수에 따라 정렬하도록 levels을 다시 정렬 ( fct_reorder2)]
다른 변수를 사용하여 levels를 정렬.
fct_reorder과의 차이는 정렬시 사용하는 변수가 두 개라는 것
- 사용법
fct_reorder2(f, x, y, fun = last2, ..., .desc = FALSE)
f
factor 형 벡터.
x, y
정렬 기준으로 사용할 변수. 이 변수를 아래의 fun지정 집계 용 함수에 보낸 결과를 정렬에 사용할 수 있음.
fun
집계용 함수를 지정. 기본값은 last2 패키지에있는 함수 (후술).
...
fun에 보내는 다른 인수를 여기에서 지정합니다. 즉 na.rm = TRUE 등을 사용할 수 있음.
.desc
논리 값, 내림차순 / 오름차순을 지정합니다. 기본값 FALSE으로 내림차순.
예시
기본적인 아이디어는 fct_reorder와 같음.
또한 인수 fun의 기본값으로 설정하고있다 last2라는 함수는 다음과 같이 정의하고 있다.
last2 <- function(x, y) {
y[order(x, na.last = FALSE)][length(y)]
}즉 x의 오름차순에 따라 y를 정렬하고 그 하단의 요소를 반환 하는 함수이다.
이를 각 factor의 요소마다 tapply구한 값을 사용하여 levels 값을 정렬함.
물론 median나 mean같은 함수로 변경할 수 있다.
이것이 가장 효과를 발휘하는 경우는 범례에 맞추고 무조건 변수를 정렬하고 싶을 때 유효하다.
예를 들어, 다음과 같은 패턴을 가정하자
chks <- subset(ChickWeight, as.integer(Chick) < 10) chks <- transform(chks, Chick = fct_shuffle(Chick)) ggplot(chks, aes(Time, weight, colour = Chick)) + geom_point() + geom_line()

범례를 보면 데이터 levels 설정 그대로 순서가 결정되며, 그래프에 그려져있는 것과 매칭이 어렵다.
그래서 Times(x 축)와 weight(y 축)의 큰 요소에 대응되도록 Chick(color 요소 범례 수)의 levels를 설정할 수 있다.
ggplot(chks, aes(Time, weight, colour = fct_reorder2(Chick, Time, weight))) + geom_point() + geom_line() + labs(colour = "Chick")
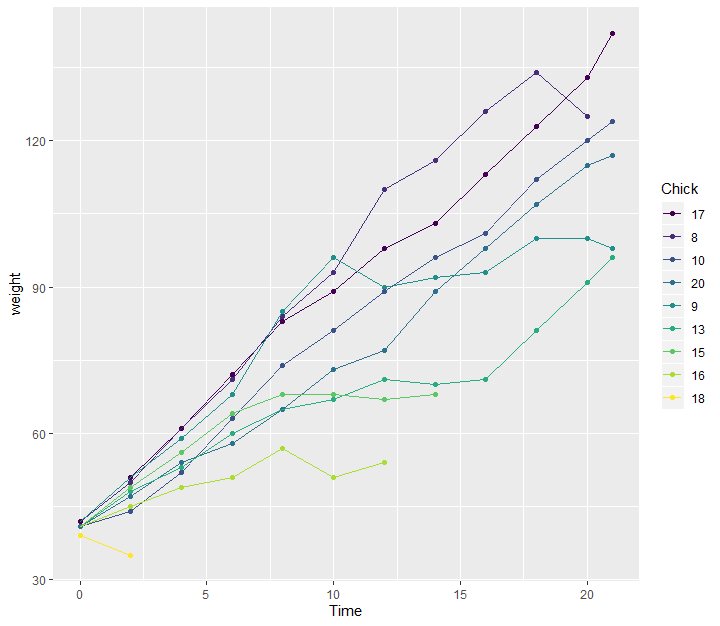
각 계열 (factor의 각 levels)의 가장 오른쪽의 요소를 사용하여 내림차순으로 되도록 levels이 정렬되었다.
levels의 순서를 반대로 ( fct_rev)
순서를 반전시킨다.
사용법
fct_rev(f)
f
임의의 factor
예시
f <- factor(c("a", "b", "c"))
fct_rev(f)
#> [1] a b c
#> Levels: c b a
[정렬 된 factor 데이터 levels 순서를 비틀기 ( fct_shift)]
정렬 된 factor 데이터에서 그 levels를 밀어낸다.
회전을 생각하면 쉽다.
사용법
fct_shift(f, n = 1L)
f
factor 형 벡터.
n
(회전) 수. 양수라면 왼쪽으로 이동하고 음수이면 오른쪽으로 이동
예시
예를 들어 요일 이름 및 월 이름 등 순환하는 경우에 효과를 발휘한다.
예를 들어, 다음과 같은 데이터를 가정하자
x <- factor(
c("Mon", "Tue", "Wed"),
levels = c("Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"),
ordered = TRUE
)
x
#> [1] Mon Tue Wed
#> Levels: Sun < Mon < Tue < Wed < Thu < Fri < Sat이것을 왼쪽으로 한번 밀고자 한다면
fct_shift(x) #> [1] Mon Tue Wed #> Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun
미는 횟수를 지정할 수도 있다.
fct_shift(x, n = 2) #> [1] Mon Tue Wed #> Levels: Tue < Wed < Thu < Fri < Sat < Sun < Mon
왼쪽이 아닌 오른쪽으로 밀고싶은 경우
fct_shift(x, n = -2) #> [1] Mon Tue Wed #> Levels: Fri < Sat < Sun < Mon < Tue < Wed < Thu
[순서를 셔플 ( fct_shuffle)]
셔플한다.
사용법
fct_shuffle(f)
f
factor형 벡터
예시
f <- factor(c("a", "b", "c"))
fct_shuffle(f)
#> [1] a b c
#> Levels: b a c
fct_shuffle(f)
#> [1] a b c
#> Levels: c a b
[factor의 levels 값을 변경]
- 순서를 (가능한 한) 유지 한 채 levels 값을 변경시킨다.
[factor의 levels 값을 익명화 (fct_anon)]
levels 값을 적당한 일련 번호에 무작위로 대체하여 원본 levels 값을 알 수 없도록 한다.
사용법
fct_anon(f, prefix = "")
- f
factor형 벡터
prefix
임의의 레이블에 부여하는 문자열
예시
levels 값도 원래의 levels의 order도 유지되지 않는다.
예를들어 다음의 데이터를 가정한다.
gss_cat$relig %>% fct_count() #> # A tibble: 16 x 2 #> f n #> <fctr> <int> #> 1 No answer 93 #> 2 Don't know 15 #> 3 Inter-nondenominational 109 #> 4 Native american 23 #> 5 Christian 689 #> 6 Orthodox-christian 95 #> 7 Moslem/islam 104 #> 8 Other eastern 32 #> 9 Hinduism 71 #> 10 Buddhism 147 #> 11 Other 224 #> 12 None 3523 #> 13 Jewish 388 #> 14 Catholic 5124 #> 15 Protestant 10846 #> 16 Not applicable 0
이에 대해 fct_anon()를 끼우게 되면
gss_cat$relig %>% `fct_anon() %>% fct_count() #> # A tibble: 16 x 2 #> f n #> <fctr> <int> #> 1 01 32 #> 2 02 10846 #> 3 03 3523 #> 4 04 689 #> 5 05 95 #> 6 06 109 #> 7 07 5124 #> 8 08 388 #> 9 09 224 #> 10 10 147 #> 11 11 0 #> 12 12 93 #> 13 13 104 #> 14 14 23 #> 15 15 71 #> 16 16 15
이처럼 levels 값은 연속적 수치값으로 고쳐지게 된다.
또한 n 값을 비교 해보면 알 수 있듯이, 일련 번호의 부여 방법은 무작위로 되어 있다.
또한 번호 앞에 전에 원하는 문자열을 붙이는 것이 가능하다.
gss_cat$relig %>%
fct_anon("kosaki") %>%
fct_count()
#> # A tibble: 16 x 2
#> f n
#> <fctr> <int>
#> 1 kosaki01 109
#> 2 kosaki02 224
#> 3 kosaki03 95
#> 4 kosaki04 5124
#> 5 kosaki05 23
#> 6 kosaki06 689
#> 7 kosaki07 147
#> 8 kosaki08 10846
#> 9 kosaki09 32
#> 10 kosaki10 15
#> 11 kosaki11 104
#> 12 kosaki12 0
#> 13 kosaki13 93
#> 14 kosaki14 388
#> 15 kosaki15 71
#> 16 kosaki16 3523
[factor의 level을 병합 (fct_collapse)]
스스로 정의한 levels 그룹에, factor 값을 드롭한다.
사용법
fct_collapse(f, ...)
- f
- factor 형 벡터
- ...
- 명명 된 벡터 시리즈. 각각의 벡터에있는 levels 값이 지정된 것으로 대체됨
예시
즉, "여러 levels을 정리해 하나의 levels이 되도록 정리할 때" 사용할 수 있다. 예를 들어, 다음과 같은 데이터를 가정할 수 있다.
fct_count(gss_cat$partyid) #> # A tibble: 10 x 2 #> f n #> <fctr> <int> #> 1 No answer 154 #> 2 Don't know 1 #> 3 Other party 393 #> 4 Strong republican 2314 #> 5 Not str republican 3032 #> 6 Ind,near rep 1791 #> 7 Independent 4119 #> 8 Ind,near dem 2499 #> 9 Not str democrat 3690 #> 10 Strong democrat 3490
현재 10 levels이 존재한다. 그러나 이 때 5 레벨로 줄이고자 한다면.
partyid2 <- fct_collapse(gss_cat$partyid,
missing = c("No answer", "Don't know"),
other = "Other party",
rep = c("Strong republican", "Not str republican"),
ind = c("Ind,near rep", "Independent", "Ind,near dem"),
dem = c("Not str democrat", "Strong democrat")
)
fct_count(partyid2)
#> # A tibble: 5 x 2
#> f n
#> <fctr> <int>
#> 1 missing 155
#> 2 other 393
#> 3 rep 5346
#> 4 ind 8409
#> 5 dem 7180위와 같이 정리할 수 있다. 이 때 이 처리에 의해 새롭게 배분 된 levels 값으로 실제 개수가 반영될 수 있으므로 주의하여야 한다.
[factor의 levels 값을 수동으로 변경 ( fct_recode)]
levels의 각 값을 수동으로 변경한다.
사용법
fct_recode(f, ...)
f
factor 형 벡터
...
새로 설정 levels 값을 명명 된 문자열 벡터를 지정한다.
예시
x <- factor(c("apple", "bear", "banana", "dear"))
fct_recode(x, fruit = "apple", fruit = "banana")
#> [1] fruit bear fruit dear
#> Levels: fruit bear dear이때 존재하지 않는 levels 값을 사용하면 경고가 나오고, 그 부분은 무시된다.
fct_recode(x, fruit = "apple", fruit = "bananana") #> Warning: Unknown levels in `f`: bananana #> [1] fruit bear banana dear #> Levels: fruit banana bear dear
또한 새로운 levels 값 NULL을 지정하면 그 수준이 삭제되고 값도 삭제된다.
fct_recode(x, NULL = "apple", fruit = "banana") #> [1] <NA> bear fruit dear #> Levels: fruit bear dear
[새로운 Level 추가]
새로운 levels 값을 추가.
[factor에 levels를 추가 ( fct_expand)]
사용법
fct_expand(f, ...)
f
factor 형 벡터.
...
추가하고 싶은 levels 값을 문자열로 지정
예시
f <- factor(sample(letters[1:3], 20, replace = TRUE)) f #> [1] b a c a c b b b b b a a b c a b a c a b #> Levels: a b c fct_expand(f, "d", "e", "f") #> [1] b a c a c b b b b b a a b c a b a c a b #> Levels: a b c d e f fct_expand(f, letters[1:6]) #> [1] b a c a c b b b b b a a b c a b a c a b #> Levels: a b c d e f
[NA에 임의의 결측값 levels을 부여 ( fct_explicit_na)]
factor 형 데이터 내에 NA가 존재하는 경우, 그 값에 "(Missing)"라는 levels을 삽입한다고 가정하자.
사용법
fct_explicit_na(f, na_level = "(Missing)")
f
factor 형 벡터.
na_level
NA로 설정할 levels 값
예시
f1 <- factor(c("a", "a", NA, NA, "a", "b", NA, "c", "a", "c", "b"))
f1
#> [1] a a <NA> <NA> a b <NA> c a c b
#> Levels: a b c
table(f1)
#> f1
#> a b c
#> 4 2 2위와 같은 데이터를 가정하였을 때
f2 <- fct_explicit_na(f1) f2 #> [1] a a (Missing) (Missing) a b (Missing) #> [8] c a c b #> Levels: a b c (Missing) table(f2) #> f2 #> a b c (Missing) #> 4 2 2 3
즉, " NA" 를 다른 문자열로 대체하여 그대로 levels 값으로 설정한다.
[기타]
[여러 factor 데이터를 연결하여 levels를 결합 ( fct_c)]
여러 factor 형 데이터를 정리 한 list 데이터의 내부를 참조하고 그것을 연결시켜 levels로 결합시킨다.
사용법
fct_c(fs)
- fs
- factor 형 벡터를 묶은 list 형 데이터
예시
fs <- list(factor("a"), factor("b"), factor(c("a", "b")))
fct_c(fs)
#> [1] a b a b
#> Levels: a b
[factor의 각 요소의 발생 횟수를 카운트 ( fct_count) ]
factor 자료형 전용 count 함수
사용법
fct_count(f, sort = FALSE)
fs
factor 형 벡터를 묶은 list 형 데이터
sort =TRUE를 지정하면, 빈도수의 내림차순으로 정렬됨.
예시
f <- factor(sample(letters)[rpois(1000, 10)]) table(f) #> f #> a b d e f g h i j k l m n o q s u v #> 33 1 82 130 37 14 51 10 46 12 79 1 43 7 8 90 1 112 #> w x y z #> 4 108 129 2 fct_count(f) #> # A tibble: 22 x 2 #> f n #> <fctr> <int> #> 1 a 33 #> 2 b 1 #> 3 d 82 #> 4 e 130 #> 5 f 37 #> 6 g 14 #> 7 h 51 #> 8 i 10 #> 9 j 46 #> 10 k 12 #> # ... with 12 more rows fct_count(f, sort = TRUE) #> # A tibble: 22 x 2 #> f n #> <fctr> <int> #> 1 e 130 #> 2 y 129 #> 3 v 112 #> 4 x 108 #> 5 s 90 #> 6 d 82 #> 7 l 79 #> 8 h 51 #> 9 j 46 #> 10 n 43 #> # ... with 12 more rows
[사용되지 않은 levels을 드롭 ( fct_drop) ]
사용법
fct_drop(f)
f
factor 형 벡터.
예시
droplevels()과 비슷함
그러나 해당 함수는 사용하지 않는 level 을 무조건 삭제함
f <- factor(c("a", "b"), levels = c("a", "b", "c"))
f
#> [1] a b
#> Levels: a b c
fct_drop(f)
#> [1] a b
#> Levels: a b
[factor 데이터 목록에서 levels을 통일 ( fct_unify)]
목록의 factor 데이터의 levels를 모두 참조하여 통일시킨다.
사용법
fct_unify(fs, levels = lvls_union(fs))
- fs
- 계수 형 벡터를 묶은 list 형 데이터.
- levels
- 참조 통합시키는 levels의 목록입니다.
예시
여러 factor 형 리스트를 참조하여 그 중 levels이 다른 경우에는 공통이 되도록 levels를 통합하고 모두 같은 levels을 부여함.
fs <- list(factor("a"), factor("b"), factor(c("a", "b")))
fct_unify(fs)
#> [[1]]
#> [1] a
#> Levels: a b
#>
#> [[2]]
#> [1] b
#> Levels: a b
#>
#> [[3]]
#> [1] a b
#> Levels: a
[unique ()의 출력을 factor의 levels 순서로 출력 ( fct_unique) ]
factor 형 데이터에서 고유 값을 반환한다.
사용법
fct_unique(f)
f
계수 형 벡터
예시
unique()거의 비슷하지만, 결과가 다소 다름
f <- factor(letters[rpois(100, 10)]) unique(f) #> [1] o k j g m h l n i p e d f c q #> Levels: c d e f g h i j k l m n o p q fct_unique(f) #> [1] c d e f g h i j k l m n o p q #> Levels: c d e f g h i j k l m n o p q
unique()는 결과가 나타나는 순서이지만 ct_unique()이 결과는 levels의 순서로 출력된다.
[전체]
참고 문헌
[논문]
- 없음
[보고서]
- 없음
[URL]
- 없음
문의사항
[기상학/프로그래밍 언어]
- sangho.lee.1990@gmail.com
[해양학/천문학/빅데이터]
- saimang0804@gmail.com
'프로그래밍 언어 > R' 카테고리의 다른 글
| [R] 대화형 테이블을 생성하는 "DT" 패키지 소개 (0) | 2020.02.12 |
|---|---|
| [R] ggplot2에서 텍스트 추가를 위한 "ggfittext" 패키지 소개 (0) | 2020.02.12 |
| [R] 문자열 조작 "stringr" 패키지 소개 (1) | 2020.02.09 |
| [R] 데이터 정제를 위한 "dplyr, tidyr" 패키지 소개 (0) | 2020.02.08 |
| [R] 기상 관측소 정보를 이용하여 태양 위치 시간 (일출/일몰/아침 골든/남중/저녁 골든/일몰/항해 박명/천문 박명/밤/아침 박명) 계산 (0) | 2020.01.09 |








최근댓글